
Data: Harder to Anonymise Yourself Than You Might Think
Posted: October 18, 2014 Filed under: Education, Opinion | Tags: Black Static, blogging, community, curriculum, data, data visualisation, education, feedback, higher education, Interzone, measurement, reflection, submission, submission system, teaching, teaching approaches, thinking, universal principles of design Leave a commentThere’s a lot of discussion around a government’s use of metadata at the moment, where instead of looking at the details of your personal data, government surveillance is limited to looking at the data associated with your personal data. In the world of phone calls, instead of taping the actual call, they can see the number you dialled, the call time and its duration, for example. CBS have done a fairly high-level (weekend-suitable) coverage of a Stanford study that quickly revealed a lot more about participants than they would have thought possible from just phone numbers and call times.
But how much can you tell about a person or an organisation without knowing the details? I’d like to show you a brief, but interesting, example. I write fiction and I’ve recently signed up to “The Submission Grinder“, which allows you to track your own submissions and, by crowdsourcing everyone’s success and failures, to also track how certain markets are performing in terms of acceptance, rejection and overall timeliness.
Now, I have access to no-one else’s data but my own (which is all of 5 data points) but I’ll show you how assembling these anonymous data results together allows me to have a fairly good stab at determining organisational structure and, in one case, a serious organisational transformation.
Let’s start by looking at a fairly quick turnover semi-pro magazine, Black Static. It’s a short fiction market with horror theming. Here’s their crowd-sourced submission graph for response times, where rejections are red and acceptances are green. (Sorry, Damien.)
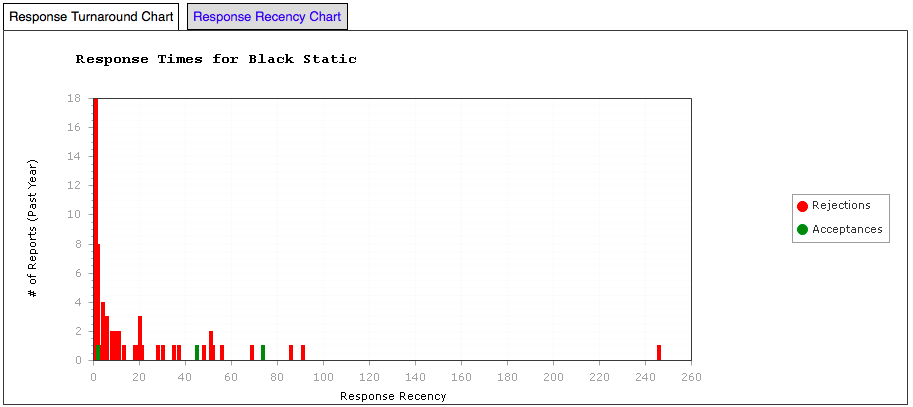
Black Static – Response Time Graph
Black Static has a web submission system and, as you can see, most rejections happen in the first 2-3 weeks. There is then a period where further work goes on. (It’s very important to note that this is a sample generated by those people who are using Submission Grinder, which is a subset of all people submitting to Black Static.) What this looks like, given that it is unlikely that anyone could read a lot 4,000-7,000 manuscripts in detail at a time, is that the editor is skimming the electronic slush pile to determine if it’s worth going to other readers. After this initial 2 week culling, what we are seeing is the result of further reading so we’d probably guess that the readers’ reviews are being handled as they come in, with some indication that this is one roughly weekly – maybe as a weekend job? It’s hard to say because there’s not much data beyond 21 days so we’re guessing.
Let’s look at Black Static’s sister SF magazine, Interzone, now semi-pro but still very highly regarded.

Interzone – Response Time Graph
Lots more data here! Again, there appears to be a fairly fast initial cut-off mechanism from skimming the web submission slush pile. (And I can back this up with actual data as Interzone rejected one of my stories in 24 hours.) Then there appears to be a two week period where some thinking or reading takes place and then there’s a second round of culling, which may be an editorial meeting or a fast reader assignment. Finally we see two more fortnightly culls as the readers bring back their reviews. I think there’s enough data here to indicate that Interzone’s editorial group consider materials most often every fortnight. Also the acceptances generated by positive reviews appear to be the same quantity as those from the editors – although there’s so little data here we’re really grabbing at tempting looking straws.
Now let’s look at two pro markets, starting with the Magazine of Fantasy & Science Fiction.
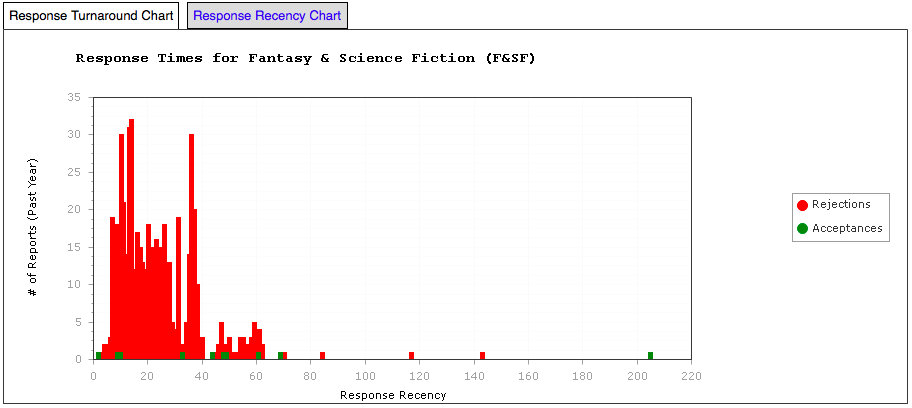
Fantasy & Science Fiction – Response Time Graph
This doesn’t have the same initial culling process that the other two had, although it appears that there is a period of 7-14 days when a lot of work has been reviewed and then rejected – we don’t see as much work rejected again until the 35 day mark, when it looks like all reader reviews are back. Notably, there is a large gap between the initial bunch of acceptances (editor says ‘yes’) and then acceptances supported by reviewers. I’m speculating now but I wonder if what we’re seeing between that first and second group of acceptances are reviewers who write back in and say “Don’t bother” quickly, rather than assembling personalised feedback for something that could be salvaged. Either way, the message here is simple. If you survive the first four weeks in F&SF system, then you are much less likely to be rejected and, with any luck, this may translate (worse case) into personal suggestions for improvement.
F&SF has a postal submission system, which makes it far more likely that the underlying work is going to batched in some way, as responses have to go out via mail and doing this in a more organised fashion makes sense. This may explain why this is such a high level of response overall for the first 35 days, as you can’t easily click a button to send a response electronically and there’re a finite number of envelopes any one person wants to prepare on any given day. (I have no idea how right I am but this is what I’m limited to by only observing the metadata.)
Tor.com has a very interesting graph, which I’ll show below.
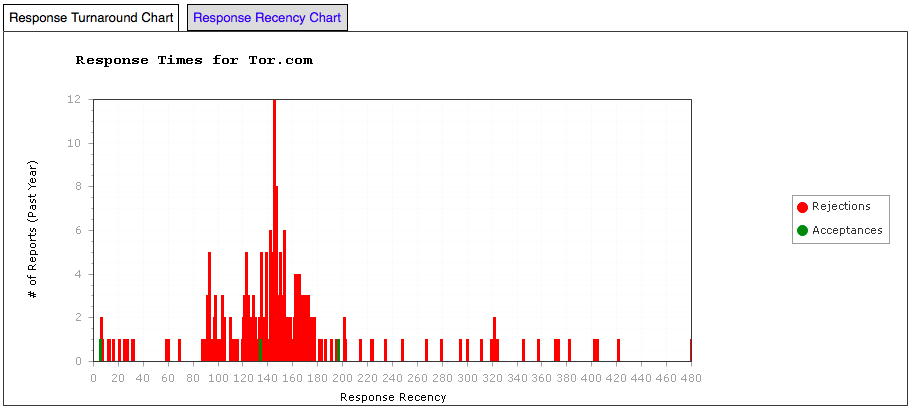
Tor.com – Response Time Graph
Tor.com pays very well and has an on-line submission system via e-mail. As a result, it is positively besieged with responses and their editorial team recently shut down new submissions for two months while they cleared backlog. What interested me in this data was the fact that the 150 day spike was roughly twice as high as the 90 and 120. Hmm – 90, 120, 150 as dominant spikes. Does that sound like a monthly editors’ meeting to anyone else? By looking at the recency graph (which shows activity relative to today) we can see that there has been an amazing flurry of activity at Tor.com in the past month. Tor.com has a five person editorial team (from their website) with reading and support from two people (plus occasional others). It’s hard for five people to reach consensus without discussion so that monthly cycle looks about right. But it will take time for 7 people to read all of that workload, which explains the relative silence until 3 months have elapsed.
What about that spike at 150? It could be the end of the initial decisions and the start of “worth another look” pile so let’s see if their web page sheds any light on it. Aha!
Have you read my story? We reply to everything we’ve finished evaluating, so if you haven’t heard from us, the answer is “probably not.” At this point the vast majority of stories greater than four months old are in our second-look pile, and we respond to almost everything within seven months.
I also wonder if we are seeing previous data where it was taking longer to get decisions made – whether we are seeing two different time management strategies of Tor.com at the same time, being the 90+120 version as well as the 150 version. Looking at the website again.
Response times have improved quite a bit with the expansion of our first reader team (emphasis mine), and we now respond to the vast majority of stories within three months. But all of the stories they like must then be read by the senior editorial staff, who are all full-time editors with a lot on our plates.
So, yes, the size of Tor.com’s slush pile and the number of editors that must agree basically mean that people are putting time aside to make these decisions, now aiming at 90 days, with a bit of spillover. It looks like we are seeing two regimes at once.
All of this information is completely anonymous in terms of the stories, the authors and any actual submission or acceptance patterns that could relate data together. But, by looking at this metadata on the actual submissions, we can now start to get an understanding of the internal operations of an organisation, which in some cases we can then verify with publicly held information.
Now think about all the people you’ve phoned, the length of time that you called them and what could be inferred about your personal organisation from those facts alone. Have a good night’s sleep!
Knowing the Tricks Helps You To Deal With Assumptions
Posted: September 10, 2014 Filed under: Education | Tags: authenticity, blogging, card shouting, collaboration, community, curriculum, data visualisation, design, education, educational problem, educational research, Heads Heads, higher education, Law of Small Numbers, random numbers, random sequence, random sequences, randomness, reflection, resources, students, teaching, teaching approaches, tools Leave a commentI teach a variety of courses, including one called Puzzle-Based Learning, where we try to teach think and problem-solving techniques through the use of simple puzzles that don’t depend on too much external information. These domain-free problems have most of the characteristics of more complicated problems but you don’t have to be an expert in the specific area of knowledge to attempt them. The other thing that we’ve noticed over time is that a good puzzle is fun to solve, fun to teach and gets passed on to other people – a form of infectious knowledge.
Some of the most challenging areas to try and teach into are those that deal with probability and statistics, as I’ve touched on before in this post. As always, when an area is harder to understand, it actually requires us to teach better but I do draw the line at trying to coerce students into believing me through the power of my mind alone. But there are some very handy ways to show students that their assumptions about the nature of probability (and randomness) so that they are receptive to the idea that their models could need improvement (allowing us to work in that uncertainty) and can also start to understand probability correctly.
We are ferociously good pattern matchers and this means that we have some quite interesting biases in the way that we think about the world, especially when we try to think about random numbers, or random selections of things.
So, please humour me for a moment. I have flipped a coin five times and recorded the outcome here. But I have also made up three other sequences. Look at the four sequences for a moment and pick which one is most likely to be the one I generated at random – don’t think too much, use your gut:
- Tails Tails Tails Heads Tails
- Tails Heads Tails Heads Heads
- Heads Heads Tails Heads Tails
- Heads Heads Heads Heads Heads
Have you done it?
I’m just going to put a bit more working in here to make sure that you’ve written down your number…
I’ve run this with students and I’ve asked them to produce a sequence by flipping coins then produce a false sequence by making subtle changes to the generated one (turns heads into tails but change a couple along the way). They then write the two together on a board and people have to vote on which one is which. As it turns out, the chances of someone picking the right sequence is about 50/50, but I engineered that by starting from a generated sequence.
This is a fascinating article that looks at the overall behaviour of people. If you ask people to write down a five coin sequence that is random, 78% of them will start with heads. So, chances are, you’ve picked 3 or 4 as you’re starting sequence. When it comes to random sequences, most of us equate random with well-shuffled, and, on the large scale, 30 times as many people would prefer option 3 to option 4. (This is where someone leaps into the comments to say “A-ha” but, it’s ok, we’re talking about overall behavioural trends. Your individual experience and approach may not be the dominant behaviour.)
From a teaching point of view, this is a great way to break up the concepts of random sequences and some inherent notion that such sequences must be disordered. There are 32 different ways of flipping 5 coins in a strict sequence like this and all of them are equally likely. It’s only when we start talking about the likelihood of getting all heads versus not getting all heads that the aggregated event of “at least one head” starts to be more likely.
How can we use this? One way is getting students to write down their sequences and then asking them to stand up, then sit down when your ‘call’ (from a script) goes the other way. If almost everyone is still standing at heads then you’ve illustrated that you know something about how their “randomisers” work. A lot of people (if your class is big enough) should still be standing when the final coin is revealed and this we can address. Why do so many people think about it this way? Are we confusing random with chaotic?
The Law of Small Numbers (Tversky and Kahneman), also mentioned in the post, which is basically that people generalise too much from small samples and they expect small samples to act like big ones. In your head, if the grand pattern over time could be resorted into “heads, tails, heads, tails,…” then small sequences must match that or they just don’t look right. This is an example of the logical fallacy called a “hasty generalisation” but with a mathematical flavour. We are strongly biassed towards the the validity of our experiences, so when we generate a random sequence (or pick a lucky door or win the first time at poker machines) then we generalise from this small sample and can become quite resistant to other discussions of possible outcomes.
If you have really big classes (367 or more) then you can start a discussion on random numbers by asking people what the chances are that any two people in the room share a birthday. Given that there are only 366 possible birthdays, the Pigeonhole principle states that two people must share a birthday as, in a class of 367, there are only 366 birthdays to go around so one must be repeated! (Note for future readers: don’t try this in a class of clones.) There are lots of other, interesting thinking examples in the link to Wikipedia that helps you to frame randomness in a way that your students might be able to understand it better.

10 pigeons into 9 boxes? Someone has a roommate.
I’ve used a lot of techniques before, including the infamous card shouting, but the new approach from the podcast is a nice and novel angle to add some interest to a class where randomness can show up.
Humanities Intensive Learning + Teaching, Day 5, Maryland Institute for Technology in the Humanities, #hilt2014
Posted: August 17, 2014 Filed under: Education | Tags: clowns, cMOOC, data visualisation, Elijah Meeks, Francis Bacon, Franco Moretti, Gephi, Google, graphs, Hamlet, Hamlet Hamlet Hamlet, HILT, HILT 2014, HITS, Horatio, map, Medicis, MITH, monkey, MOOC, Moretti, network, network visualisation, PageRank, RDF, Shakespeare, Small worlds, Tufte, visualisation, xMOOC, Zelchenko 1 CommentSorry for the delay in completing this – it has been crazy and I prefer to write directly into the live blog, which means a network feed, as I just find it easier to put things together this way. (It’s only been a week (ish) anyway.)
Today (well, then), we looked at modularity and how we could break networks into separate communities. This is important because it helps us to be able to see structure. The human eye is a great tool but it often needs help and modularity is a good way to do this. We have strong ties between components in directed networks (unidirectional) because we have taken the time to say that the link goes this way. We have weak ties in undirected networks because there is no solidity to the association form one side to the other. The more connected something is, the more strongly tied it is to the things it connects to so, when we hunt for communities, we want to take away the least number of connections to produce the largest number of connected communities.
Let’s look at the Hamlet graph (after Moretti) with some colouring added for the various communities and all the connections left in.

It’s hard to see any separation here although the communities can be seen.
Now let’s take out the intra-community links.

Bingo! Poor old Hamlet.
Now we can suddenly see, in terms of dialogue exchanges and interaction, how isolated Hamlet actually is. The members of the court are one community. The invaders are another. Horatio, the proxy for the Danish state, is deeply involved in statehood. Hamlet, however, is more heavily connected to the characters who help with his dawning realisation that something has gone awry. No wonder he goes mad, he’s the Nigel Nofriends of Medieval Denmark, with only the insane Clown Posse and a group of second-rate actors to keep him company.
After this we spent some extensive time working on producing prettier looking graphs with Gephi and using more advanced algorithms to help us to represent what’s going on. We looked at the Twitter data for the conference and came up with this:

Twitter data using the #HILT2014 tag
This shows the separate groups of Twitter user communities who used the HILT2014 hashtag. My small cluster is the small purple arrow bottomish left. We’ve also ranked the size of the data labels based on the significance of that person in the Twitter information chain, using the PageRank algorithm. So, Jim McGrath wins Twitter for HILT 2014! We also look and how important certain links were in the network by looking at edge betweenness to determine which links are used by the most shortest paths and then use this to identify important connected components.
Lots of good hands-on stuff and a very interesting course! I learned a great deal and have already started using it elsewhere.
Humanities Intensive Learning + Teaching, Day 4, Maryland Institute for Technology in the Humanities, #hilt2014
Posted: August 8, 2014 Filed under: Education | Tags: clowns, cMOOC, data visualisation, Elijah Meeks, Francis Bacon, Franco Moretti, Gephi, Google, graphs, Hamlet, Hamlet Hamlet Hamlet, HILT, HILT 2014, HITS, Horatio, map, Medicis, MITH, monkey, MOOC, Moretti, network, network visualisation, PageRank, RDF, Shakespeare, Small worlds, Tufte, visualisation, xMOOC, Zelchenko Leave a commentOr, the alternative title, “The Play Formerly Known as Hamlet”. Today had a lot of fascination discussion where the bipartite nature of our class network became apparent, in terms of the the majority of the class who were Digital Humanists and really understood a detailed close reading of Hamlet – and your humble narrator.
Today we talked about modularity, which allows you to break your network up into separate modules, which makes a lot more sense when you call those modules things like communities, groups or clusters. Can your network be split up into areas where some groups are more connected to each other than they are to adjacent nodes? By doing this, we are trying to expose structural features of the network and, in particular, unexpected aspects of network structure – is there some set of nodes that have a role in the network that we don’t understand? If we talk about this in terms of people, if our social network is made up of small communities with connections between the communities, then we would expect gossip to spread more rapidly inside a community than between the communities. Simple, eh? The approach we take depends upon comparing the structure we have with a model of a random network using the same number of links.
Once we’ve done this, we can use this in a tool, such as Gephi, to clearly illustrate the groups. Here’s a grumpy Dane in illustration.

Hamlet and the various posses of Hamlet. Note the Insane Clown Posse.
I’ve coloured and tagged the network to show the key players in Hamlet, based on Moretti’s analysis of Hamlet, which attached unweighted connections between participants who had direct conversations. Now, we’ve made the size of the nodes reflect how relatively important (in terms of betweenness, the number of paths that must go through this person). If we did this in terms of PageRank, another measure of the relative importance of nodes, based on their connectivity, the nodes in green would jump up in size. But what you should note is that Hamlet and Horatio are roughly the same size and, while Hamlet is much more connected to everyone (quelle surprise, given the play’s named after him), the only thing that we lose if Hamlet disappears is that we no longer can hear from the Insane Clown Posse, Lucianus and the Lord. In purely connected terms he doesn’t appear to be that important. We’d obviously lose a lot of the text if he disappeared but how important is Hamlet in Hamlet?
This led to a lot of discussion in class as to the validity of the original Moretti pamphlet, much of which is core to the entire discussion of Digital Humanities. How valid is any conclusion from a network model such as this when the innate nature of the capture process (to provide the capta) may completely remove the ability to draw certain conclusions? The class discussed the impact on perceived and invisible observers, who strictly don’t have dialogue with each other but potentially have an impact upon other characters and their narrative interactions. (The Moretti pamphlet may be found here.) Moretti had a lot to say about Horatio as a proxy for the state and was very interested in the closeness of Hamlet to everyone else, but (later on) we ran some random network experiments and it turned out to be the type of connections in the network (the clustering coefficient) that was more interesting than the closeness.
We then moved on to a discussion of a number of useful metric for networks, including the clustering effects that tend to indicate intention in the system we’re studying (there’s no real reason for a random network to form a small number of unique clusters unless you tune for it.) We also discussed the Small Worlds of Watts and Strogatz (1998) where you have cliques of nodes (tightly connected clusters) linked together by a smaller number of links, characterised by a power law distribution and a higher clustering coefficient (very basically).
We generated some random graphs to see if we got the structure we saw in Hamlet as noted earlier. Why? Because looking at Hamlet and drawing out information from the structure only has validity if (1) the model is accurate and (2) the situation couldn’t have easily arisen by chance. As noted, we generated a random graph for the same number of nodes and it had a similar average path length and identical diameter – but very different clustering coefficients! So it turns out that Hamlet wasn’t written by a monkey after all.

Don’t laugh, this is Darwin’s skull!
The final part of the session was on dynamic networks. This is the study of networks that change over time and we worked with some data that showed people’s association with an area over time. We could look at this in terms of change in time or in terms of progress through a corpus (chapters are as useful as dates here). What you want is a start date and an end date for the feautres in your network – when should the feature be there and when should it not be there anymore? It turns out that Gephi is quite convenient here, because you can merge a start and end time and end up with a time interval. Not bad, Gephi, not bad. Now we can see when things are active – great if you’re looking to see when students are active in forums or activities, for example. Here’s an example of the difference in the test network between the first and second halves of 2009, with all nodes of zero degree (nodes with no links) removed.

First half of 2009

Second half of 2009
We then played around a lot with a vide variety of animations over time, including ongoing calculations, colour and shape alterations. Basically, it was rather hallucinatory by the end but that may be the Dr Pepper talking. We even got to see the sparklines (Zelchenko/Tufte) for some extra visualisation goodness!
This is one of those classic separations between the things we visualise for ourselves to help us to work out what’s interesting about a dataset and what we would visualise for presentation, especially to non-discipline people. There’s a really big difference between what scientists want to see and what other people want to see – and if we don’t realise that, then we risk either having presentations that don’t communicate enough information or we kill people with minutiae. Look at this – how useful is it for you?

Death by Sparkline!
Another good day but I think there are some very full brains!
Humanities Intensive Learning + Teaching, Day 3, Maryland Institute for Technology in the Humanities, #hilt2014
Posted: August 8, 2014 Filed under: Education | Tags: capta, cMOOC, data visualisation, Elijah Meeks, Florence, Google, graphs, HILT, HILT 2014, HITS, map, Medicis, MITH, MOOC, network, network visualisation, PageRank, RDF, visualisation, xMOOC Leave a commentToday was going to be a short day because we had the afternoon off to go and do cultural things. (I took the afternoon to write papers and catch up on work. I tend to work in both timezones when travelling because otherwise work will eat my head.) Today we explored a lot of filtering in Gephi, which was … interesting and best done in practice. Which we did. So, hooray!
We looked at Multimodal Network Projection throughout the day but I’ll come back to that. We started looking at other ways of determining the important and dependant nodes in a network, starting with the HITS algorithm, which identifies Hubs and Authorities in your network.
Then we moved into the wonderful world of PageRank, Citation networks and how all of these things work. PageRank is, fundamentally, how Google works out which pages to give you. You won’t be able to find out the details of the way that Google runs PageRank because gaming PageRank to serve up pages that you probably didn’t want to see is very big business and highly irritating. Search Engine Optimisers (SEOs) spend a lot of time trying to reverse engineer the algorithm and Google spends a lot of time tweaking it. It’s good we’ve solved all the important problems in the world so we can spend time on this.
Back to PageRank. PageRank looks at the number of links going to a node and what the quality of these links is in order to work out which the most important nodes (pages in the case of Google search) are and, hence, which ones you want. In Digital Humanities, you can use this to identify the most significant element of your model – which, by the way, quickly establishes that Hamlet is not as important as you think. Take that, Hamlet! Want more detail on PageRank? Look here.

From Wikipedia: The more you are pointed to by quality links, the bigger (and happier) you are. Hooray!
In Citations, we want to see how is citing which reference, which is straightforward. In Co-Citation networks, we want to measure how often two documents are cited together. There are many reasons for looking at this, but it helps to detect things like cronyism (someone citing a paper because they like someone rather than because the information is useful). As we discussed before, the Matthew Effect comes in quickly, where frequently cited papers get even more frequently cited because they must be good because they’re cited so frequently. (Tadahhh.)
We also looked at a rather complicated area of multimodal projection, which is going to need some set-up. If you have a set of authors and a set of publications, then you can associate authors with publications and vice versa. However, this means that the only way for two authors to be connected is by sharing a publication and similarly for two publications sharing an author. This is a bipartite network and is very common in this kind of modelling. Now, if we make it more complicated, by moving to a conference and having Authors, Papers and Presentation Sessions, we now have a tripartite network and this becomes very hard to visualise.
What we can do is clean up this network to make it easier to represent by hiding some of the complexity in the connections between nodes. Let’s say we want to look at Authors and Presentation Sessions. Then, while the real network is Authors connected to Papers connected to Presentation Sessions, we can hide the Papers with a network link that effectively says “connects this author via a presentation to this session” and suddenly our network looks like it’s only Authors and Sessions. This level of visual de-cluttering, which is dimensional reduction for those playing along at home, makes it easier for us to visually represent the key information and produce network statistics on these simpler graphs. It’s also a natural fit for triple-based representations like the Resource Description Framework (RDF) because the links in the network now map straight to predicates. (Don’t worry if you didn’t get that last bit, some people just got very excited.)
Finally, we looked at how we collect information. Is it stuff we just pick up from the environment (data) or is it something that we choose the way that we collect it (capta)? (Capta comes from the word for capture. Data is passive. Capta is active. Take that, Bembridge Scholars!) If you think about it, every time you put your data into a spreadsheet, you are imposing a structure upon it, even down to which column is which – it’s not technically data, it’s capta because your interpretation alters it before it even reaches the analysis stage. When it comes to the network that you draw, do you care about the Proximities of elements in your network (location, membership or attitude), the Relations in your network (role, affective, perceptual), the Interactions or the Flows? All of these are going to change what the nodes and edges (links) represent in the network.
The simple rule is that entities are connected by relationships (For those who think in tuples, think “subject, predicate, object” and get your predicate on!) However you do it, you have to pick what’s important in your data, find it, capture it, analyse it and present it in a way that either shows you cool things or supports the cool things that you already know.
A lot to cover today!
After the session, I did some work and then headed off for dinner and board games with some of the other people from the workshop. A nice relaxing night after a rather intense three days.
Humanities Intensive Learning + Teaching, Day 2, Maryland Institute for Technology in the Humanities, #hilt2014
Posted: August 8, 2014 Filed under: Education | Tags: betweenness, centrality, cMOOC, data visualisation, Elijah Meeks, Florence, graphs, HILT, HILT 2014, Medicis, MITH, MOOC, network, network measurements, network visualisation, visualisation, xMOOC Leave a commentIn Day 2, we looked at using the Gephi tool itself, along with the nature of how networks are tied together, looking at network degree and how we could calculate paths through the network. It’s probably important to talk about some of the key concepts of how we measure connectedness in a network, and the relevant importance of nodes.
The degree of a node is the number of links that connect to it. If we care about whether the links have some idea of direction associated with them then we might split this into in-degree and out-degree, being the number of links going in and the number of links going out. What do we mean by direction? Consider Facebook. If you and I are going to be Friends then we both have to agree to be Friends – I can’t be a friend unless you want to a friend to. This is an undirected arrangement and a connection between us implies that both us have an equal connection to each other. Now think about unrequited love: Duckie loves Andie but Andie loves Blane. In this case, the love is directed. Just because Duckie loves Andie, it doesn’t mean that Andie loves Duckie.

Time to put on some Psychedelic Furs and find the alternate ending. (Yeah, yeah, it’s not actually in the story and it’s creepy.)
ALTHOUGH IT SHOULD, JOHN HUGHES!!!
(An amusing aside for network/maths people is that, sadly, love is not transitive or “Pretty in Pink” would have been way ahead of its time.)
One of the other things that we care about in networks is the relative importance of nodes in terms of how many other nodes they are connected to and what this means in terms of the paths we take through the network. When we talk about paths, we usually mean the shortest path, where we start somewhere and go through the minimum number of intermediate points until we get to the destination. We don’t run around in circles. We don’t go one way and then go another. This is important because the paths through a network can quickly identify the important nodes and, therefore, the links between them that are the most travelled thoroughfares.
In this world, we start to worry about the centrality of a node, which indicates how important it is by looking at how many other nodes it is connected to or how many other nodes have to use it to get to other places in the network. This means that we have to talk about betweenness, which measures how many times the shortest paths that traverse a network have to go through a node. By calculating the betweenness of every node, for every path, we can work out which of the elements in our network see the most traffic.
In the case of the Medicis, from yesterday, all roads in Florence lead to the Medicis, the family with the highest betweenness rather than the family with the most money or fame. The Medicis are an extreme case because they occupy their position of importance as the only bridge (broker) between certain families.
If a network is made of highly connected elements and all of the betweenness is the same then no-one has an advantage. If your network can be effectively split into two highly connected groups, with a smaller number of high-betweenness elements linking them, then you are seeing a separation that may mean something significant in your particular network domain. From a power perspective, the high betweenness brokers now have the potential to have much more influence if they charge for transit and transform information that traverses them.
One of the things about creating a network from data is that the network we create may not necessarily model reality in a way that answers the questions we’re interested in, but by looking at the network and trying to work out if it’s got some different structure at the macro, meso and micro scale, then that might give us hints as to how to analyse it, to further develop our understanding of the area that we’re modelling with this network.
I’ve written about the difference between the real world and the model before, but let’s just say that “the map is not the territory” and move on. In terms of the structure of networks, while many people assume that the distribution of nodes and links associated with them would end up in some sort of Normal distribution, the truth is that we tend to see a hub-spoke tendency, where there are lots of nodes with few links and fewer nodes with lots of links. When we start to look at the detailed structure rather than the average structure, we can even talk about uniform the structure is. If a network looks the same across itself, such as the same number of connections between nodes, then it’s what we call assortative. If we have small clusters of highly connected nodes joined to other clusters with sparse links, then we’d thinking of it as disassortative. Suddenly, we are moving beyond some overall statistics to look at what we can really say about the structure of a network.
There’s also a phenomenon known as the Matthew Effect, where links and nodes added to a network tend to connect to better connected nodes and, as the network grows, nodes with more connections just get more connected – just like life.
Apart from a lot of Gephi, we finished the day by looking at paths in more detail, which allow us to talk about the network diameter, the size of the largest shortest path in the network. (Remembering that a shortest path contains no loops or false starts, so the largest shortest path shows you the largest number of unique nodes you can visit in the network and gives you an idea of how much time you can waste in that network. 🙂 )
There are some key concepts here, where having redundant paths in a network allows us to survive parts of a network going away (whether computer or social) and having redundant paths of the same quality allows us to endure loss without seeing a significant change in the shortest paths in the network. These are all concepts that we’re familiar with in real life but, once we start to measure them in our network models, we find out the critical components in our data model. If we’re modelling student forums, is there one person who is brokering all of the communication? What happens if she gets sick or leaves the course? Now we have numbers to discuss this – for more, tune in to the next instalment!
Humanities Intensive Learning + Teaching, Day 1, Maryland Institute for Technology in the Humanities, #hilt2014
Posted: August 6, 2014 Filed under: Education | Tags: cMOOC, data visualisation, Elijah Meeks, Florence, graphs, HILT, HILT 2014, Medicis, MITH, MOOC, network, network visualisation, visualisation, xMOOC Leave a commentI’m attending the Humanities Intensive Learning + Teaching courses at Maryland Institute for Technology in the Humanities, #hilt2014, for the second year running. Last year was Matt Jocker’s excellent course on R and this year I’m attending Elijah Meek’s course on Network Analysis and Visualisation. The first day we covered network basics and why you might want to actually carry out visualisation across graphs – and what the hell are graphs anyway?
Graphs, put simply, are a collection of things and connections between those things. Now that I’ve killed every mathematician reading this blog, let’s continue. I’ve done a lot of work on this before in the Internet Topology Zoo but it’s now looking like analysis of large-scale online education is something I have to get good at, so it seemed a great opportunity to come and see how the DH community do this and get access to some mature processes and tools.
Why is this important as a visualisation (or representation, thanks, Elijah) target? Because pictures tell stories well and we can use this to drive argument and make change.
Let’s consider the Medici, the family who dominated Florence from the 1400s to the 18th century. While not being the most wealthy and powerful families at the outset, they were (by marriage and arrangements) one of the most well connected families. In fact, the connections from some groups of families to other families had to go through the Medicis – which made them more important because of their role in the network.

Padget & Ansell’s network of marriages and economic relationships between Florentine families. (from http://www.themacroscope.org/?page_id=308)
The graph makes the relationship and the importance clear. (Insert toast about Boston, Lowells and Cabots here.)
In graphs of the Internet, everything is connected to the Internet by definition, so we don’t have any isolated elements. (We do have networks that don’t connect to the Internet, such as super-secret defence networks and some power stations – not as many as there used to be – but we’re interested in the Internet.) It is possible to analyse communities and show ways that some people/entities/organisations are not connected to each other. Sometimes they form disconnected clusters, sometimes they sit by themselves, and this is where my interest comes in, because we can use this to analyse student behaviour as a learning community.
A student who enrols in your course is notionally part of your community but this is an administrative view of the network. It’s only when they take part in any learning and teaching activity that they actually become part of the learning community. Suddenly all of the students in your network can have a range of different types of connection, which is a good start to finding categories to talk about behaviour in large on-line courses, because now we can easily separate enrolment from attendance, attendance from viewing, viewing from participation in discussion, and discussion from submission of work. I hope to have a good look into this to find some nice (convenient) mathematical descriptions of the now defunct cMOOC/xMOOC distinction and how we can encourage behaviour to get students to form robust learning networks.
As we can see from the Medicis, the Medicis used their position in order to gain power – it wasn’t in their interests to form additional connections to make the network resilient if they fell on hard times. However, learning networks don’t want a central point that can fail (central points of failure are to be avoided in most contexts!) and this is why a learning community is so important. If students are connected to many other students and their lecturing staff, then the chances of one relationship (connection) failing causing the whole network to fail is very low. Some people are, naturally, very important in a learning community: we’d hope that instructors would be, tutors would be, and key students who handle discussions or explanations also would be. However, if we have very few of these important people, then everyone else is depending upon this small number to stay connected and this puts a lot of stress on these people and makes it easy for your network to fall apart.
I’ll talk more about this tomorrow and hit you with you some definitions!
ITiCSE 2014, Monday, Session 1A, Technology and Learning, #ITiCSE2014 #ITiCSE @patitsel @guzdial
Posted: June 23, 2014 Filed under: Education | Tags: badges, computer science education, data visualisation, digital education, digital technologies, education, game development, gamification, higher education, ITiCSE, ITiCSE 2014, learning, moocs, PBL, projected based learning, SPOCs, teaching, technology, thinking, visualisation Leave a comment(The speakers are going really. really quickly so apologies for any errors or omissions that slip through.)
The chair had thanked the Spanish at the opening for the idea of long coffee breaks and long lunches – a sentiment I heartily share as it encourages discussions, which are the life blood of good conferences. The session opened with “SPOC – supported introduction to Programming” presented by Marco Piccioni. SPOCs are Small Private On-line Courses and are part of the rich tapestry of hand-crafted terminology that we are developing around digital delivery. The speaker is from ETH-Zurich and says that they took a cautious approach to go step-by-step in taking an existing and successful course and move it into the on-line environment. The classic picture from University of Bologna of the readers/scribes was shown. (I was always the guy sleeping in the third row.)

No paper aeroplanes?
We want our teaching to be interesting and effective so there’s an obis out motivation to get away from this older approach. ETH has an interesting approach where the exam is 10 months after the lecture, which leads to interesting learning strategies for students who can’t solve the instrumentality problem of tying work now into success in the future. Also, ETH had to create an online platform to get around all of the “my machine doesn’t work” problems that would preclude the requirement to install an IDE. The final point of motivation was to improve their delivery.
The first residential version of the course ran in 2003, with lectures and exercise sessions. The lectures are in German and the exercise sessions are in English and German, because English is so dominant in CS. There are 10 extensive home assignments including programming and exercise sessions groups formed according to students’ perceived programming proficiency level. (Note on the last point: Hmmm, so people who can’t program are grouped together with other people who can’t program? I believe that the speaker clarifies this as “self-perceived” ability but I’m still not keen on this kind of streaming. If this worked effectively, then any master/apprentice model should automatically fail) Groups were able to switch after a week, for language or not working with the group.
The learning platform for the activity was Moodle and their experience with it was pretty good, although it didn’t do everything that they wanted. (They couldn’t put interactive sessions into a lecture, so they produced a lecture-quiz plug-in for Moodle. That’s very handy.) This is used in conjunction with a programming assessment environment, in the cloud, which ties together the student performance at programming with the LMS back-end.
The SPOC components are:
- lectures, with short intros and video segments up to 17 minutes. (Going to drop to 10 minutes based on student feedback),
- quizzes, during lectures, testing topic understanding immediately, and then testing topic retention after the lecture,
- programming exercises, with hands-on practice and automatic feedback
Feedback given to the students included the quizzes, with a badge for 100% score (over unlimited attempts so this isn’t as draconian as it sounds), and a variety of feedback on programming exercises, including automated feedback (compiler/test suite based on test cases and output matching) and a link to a suggested solution. The predefined test suite was gameable (you could customise your code for the test suite) and some students engineered their output to purely match the test inputs. This kind of cheating was deemed to be not a problem by ETH but it was noted that this wouldn’t scale into MOOCs. Note that if someone got everything right then they got to see the answer – so bad behaviour then got you the right answer. We’re all sadly aware that many students are convinced that having access to some official oracle is akin to having the knowledge themselves so I’m a little cautious about this as a widespread practice: cheat, get right answer, is a formula for delayed failure.
Reporting for each student included their best attempt and past attempts. For the TAs, they had a wider spread of metrics, mostly programmatic and mark-based.
On looking at the results, the attendance to on-line lectures was 71%, where the live course attendance remained stable. Neither on-line quizzes nor programming exercises counted towards the final grade. Quiz attempts were about 5x the attendance and 48% got 100% and got the badge, significantly more than the 5-10% than would usually do this.
Students worked on 50% of the programming exercises. 22% of students worked on 75-100% of the exercises. (There was a lot of emphasis on the badge – and I’m really not sure if there’s evidence to support this.)
The lessons learned summarised what I’ve put above: shortening video lengths, face-to-face is important, MCQs can be creative, ramification, and better feedback is required on top of the existing automatic feedback.
The group are scaling from SPOC to MOOC with a Computing: Art, Magic, Science course on EdX launching later on in 2014.
I asked a question about the badges because I was wondering if putting in the statement “100% in the quiz is so desirable that I’ll give you a badge” was what had led to the improved performance. I’m not sure I communicated that well but, as I suspected, the speaker wants to explore this more in later offerings and look at how this would scale.
The next session was “Teaching and learning with MOOCs: Computing academics’ perspectives and engagement”, presented by Anna Eckerdal. The work was put together by a group composed from Uppsala, Aalto, Maco and Monash – which illustrates why we all come to conferences as this workgroup was put together in a coffee-shop discussion in Uppsala! The discussion stemmed from the early “high hype” mode of MOOCs but they were highly polarising as colleagues either loved it or hated it. What was the evidence to support either argument? Academics’ experience and views on MOOCs were sought via a questionnaire sent out to the main e-mail lists, to CS and IT people.
The study ran over June-JUly 2013, with 236 responses, over > 90 universities, and closed- and open-ended questions. What were the research questions: What are the community views on MOOC from a teaching perspective (positive and negative) and how have people been incorporating them into their existing courses? (Editorial note: Clearly defined study with a precise pair of research questions – nice.)
Interestingly, more people have heard concern expressed about MOOCs, followed by people who were positive, then confused, the negative, then excited, then uninformed, then uninterested and finally, some 10% of people who have been living in a time-travelling barrel in Ancient Greece because in 2013 they have heard no MOOC discussion.
Several themes were identified as prominent themes in the positive/negative aspects but were associated with the core them of teaching and learning. (The speaker outlined the way that the classification had been carried out, which is always interesting for a coding problem.) Anna reiterated the issue of a MOOC as a personal power enhancer: a MOOC can make a teacher famous, which may also be attractive to the Uni. The sub themes were pedagogy and learning env, affordance of MOOCs, interaction and collaboration, assessment and certificates, accessibility.
Interestingly, some of the positive answers included references to debunked approaches (such as learning styles) and the potential for improvements. The negatives (and there were many of them) referred to stone age learning and ack of relations.
On affordances of MOOCs, there were mostly positive comments: helping students with professional skills, refresh existing and learn new skills, try before they buy and the ability to transcend the tyranny of geography. The negatives included the economic issues of only popular courses being available, the fact that not all disciplines can go on-line, that there is no scaffolding for identity development in the professional sense nor support development of critical thinking or teamwork. (Not sure if I agree with the last two as that seems to be based on the way that you put the MOOC together.)
I’m afraid I missed the slide on interaction and collaboration so you’ll (or I’ll) have to read the paper at some stage.
There was nothing positive about assessment and certificates: course completion rates are low, what can reasonably be assessed, plagiarism and how we certify this. How does a student from a MOOC compete with a student from a face-to-face University.
1/3 of the respondents answered about accessibility, with many positive comments on “Anytime. anywhere, at one’s own pace”. We can (somehow) reach non-traditional student groups. (Note: there is a large amount of contradictory evidence on this one, MOOCs are even worse than traditional courses. Check out Mark Guzdial’s CACM blog on this.) Another answer was “Access to world class teachers” and “opportunity to learn from experts in the field.” Interesting, given that the mechanism (from other answers) is so flawed that world-class teachers would barely survive MOOC ification!
On Academics’ engagement with MOOCs, the largest group (49%) believed that MOOCs had had no effect at all, about 15% said it had inspired changes, roughly 10% had incorporated some MOOCs. Very few had seen MOOCs as a threat requiring change: either personally or institutionally. Only one respondent said that their course was a now a MOOC, although 6% had developed them and 12% wanted to.
For the open-ended question on Academics’ engagement, most believed that no change was required because their teaching was superior. (Hmm.) A few reported changes to teaching that was similar to MOOCs (on line materials or automated assessment) but wasn’t influenced by them.
There’s still no clear vision of the role of MOOCs in the future: concerned is as prominent as positive. There is a lot of potential but many concerns.
The authors had several recommendations of concern: focusing on active learning, we need a lot more search in automatic assessment and feedback methods, and there is a need for lots of good policy from the Universities regarding certification and the role of on-site and MOOC curricula. Uppsala have started the process of thinking about policy.
The first question was “how much of what is seen here would apply to any new technology being introduced” with an example of the similar reactions seen earlier to “Second Life”. Anna, in response, wondered why MOOC has such a global identity as a game-changer, given its similarity to previous technologies. The global discussion leads to the MOOC topic having a greater influence, which is why answering these questions is more important in this context. Another issue raised in questions included the perceived value of MOOCs, which means that many people who have taken MOOCs may not be advertising it because of the inherent ranking of knowledge.
@patitsel raised the very important issue that under-represented groups are even more under-represented in MOOCs – you can read through Mark’s blog to find many good examples of this, from cultural issues to digital ghettoisation.
The session concluded with “Augmenting PBL with Large Public Presentations: A Case Study in Interactive Graphics Pedagogy”. The presenter was a freshly graduated student who had completed the courses three weeks ago so he was here to learn and get constructive criticism. (Ed’s note: he’s in the right place. We’re very inquisitive.)
Ooh, brave move. He’s starting with anecdotal evidence. This is not really the crowd for that – we’re happy with phenomenographic studies and case studies to look at the existence of phenomena as part of a study, but anecdotes, even with pictures, are not the best use of your short term in front of a group of people. And already a couple of people have left because that’s not a great way to start a talk in terms of framing.
I must be honest, I slightly lost track of the talk here. EBL was defined as project-based learning augmented with constructively aligned public expos, with gamers as the target audience. The speaker noted that “gamers don’t wait” as a reason to have strict deadlines. Hmm. Half Life 3 anyone? The goal was to study the pedagogical impact of this approach. The students in the study had to build something large, original and stable, to communicate the theory, work as a group, demonstrate in large venues and then collaborate with a school of communication. So, it’s a large-scale graphics-based project in teams with a public display.
…
Grading was composed of proposals, demos, presentation and open houses. Two projects (50% and 40%) and weekly assignments (10%) made up the whole grading scheme. The second project came out after the first big Game Expo demonstration. Project 1 had to be interactive groups, in groups of 3-4. The KTH visualisation studio was an important part of this and it is apparently full of technology, which is nice and we got to hear about a lot of it. Collaboration is a strong part of the visualisation studio, which was noted in response to the keynote. The speaker mentioned some of the projects and it’s obvious that they are producing some really good graphics projects.
I’ll look at the FaceUp application in detail as it was inspired by the idea to make people look up in the Metro rather than down at their devices. I’ll note that people look down for a personal experience in shared space. Projecting, even up, without capturing the personalisation aspect, is missing the point. I’ll have to go and look at this to work out if some of these issues were covered in the FaceUp application as getting people to look up, rather than down, needs to have a strong motivating factor if you’re trying to end digitally-inspired isolation.
The experiment was to measure the impact on EXPOs on ILOs, using participation, reflection, surveys and interviews. The speaker noted that doing coding on a domain of knowledge you feel strongly about (potentially to the point of ownership) can be very hard as biases creep in and I find it one of the real challenges in trying to do grounded theory work, personally. I’m not all that surprised that students felt that the EXPO had a greater impact than something smaller, especially where the experiment was effectively created with a larger weight first project and a high-impact first deliverable. In a biological human sense, project 2 is always going to be at risk of being in the refectory period, the period after stimulation during which a nerve or muscle is less able to be stimulated. You can get as excited about the development, because development is always going to be very similar, but it’s not surprising that a small-scale pop is not as exciting as a giant boom, especially when the boom comes first.
How do we grade things like this? It’s a very good question – of course the first question is why are we grading this? Do we need to be able to grade this sort of thing or just note that it’s met a professional standard? How can we scale this sort of thing up, especially when the main function of the coordinator is as a cheerleader and relationships are essential. Scaling up relationships is very, very hard. Talking to everyone in a group means that the number of conversations you have is going to grow at an incredibly fast rate. Plus, we know that we have an upper bound on the number of relationships we can actually have – remember Dunbar’s number of 120-150 or so? An interesting problem to finish on.
SIGCSE Day 3, “What We Say, What They Do”, Saturday, 9-10:15am, (#SIGCSE2014)
Posted: March 9, 2014 Filed under: Education | Tags: CS1, dashboarding, data visualisation, education, EiPE, higher education, neopiaget, programming, SIGCSE2014, SOLO, students, TDD, teaching, teaching approaches, test last, test-driven development, testing, WebCAT 3 CommentsThe first paper was “Metaphors we teach by” presented by Ben Shapiro from Tufts. What are the type of metaphors that CS1 instructors use and what are the wrinkles in these metaphors. What do we mean by metaphors? Ben’s talking about conceptual metaphors, linguistic devices to allow us to understand one idea in terms o another idea that we already know. Example: love is a journey – twists and turns, no guaranteed good ending, The structure of a metaphor is that you have a thing we’re trying to explain (the target) in terms of something we already know (the source). Conceptual metaphors are explanatory devices to assist us in understanding new things.
- What metaphors do CS1 instructors use for teaching?
- What are the trying to explain?
- What are the sources that they use?
- Levels taught and number of years
- Tell me about a metahpor
- Target to source mapping
- Common questions students have
- Where the metaphor breaks down
- How to handle the breakdown in teaching.
- Which metaphors work better?
- Cognitive clinical internviews, exploring how students think with metaphors and where incorrect inferences are drawn.
- Constant – even time a goal achieve, you got a hint (Consistently rewards target behaviour)
- Delayed – Hints when earned, at most one hint per hour (less inceptive for hammering the system)
- Random – 50% chance of hints when goal is met. (Should reduce dependency on extrinsic behaviours)
Enemies, Friends and Frenemies: Distance, Categorisation and Fun.
Posted: January 29, 2014 Filed under: Education | Tags: curriculum, data visualisation, design, education, educational problem, games, higher education, in the student's head, learning, principles of design, resources, student perspective, teaching, teaching approaches, thinking, tools Leave a commentAs Mario Puzo and Francis Ford Coppola wrote in “The Godfather Part II”:
… keep your friends close but your enemies closer.
(I bet you thought that was Sun Tzu, the author of “The Art of War”. So did I but this movie is the first use.)
I was thinking about this the other day and it occurred to me that this is actually a simple modelling problem. Can I build a model which will show the space around me and where I would expect to find friends and enemies? Of course, you might be wondering “why would you do this?” Well, mostly because it’s a little bit silly and it’s a way of thinking that has some fun attached to it. When I ask students to build models of the real world, where they think about how they would represent all of the important aspects of the problem and how they would simulate the important behaviours and actions seen with it, I often give them mathematical or engineering applications. So why not something a little more whimsical?
From looking at the quote, we would assume that there is some distance around us (let’s call it a circle) where we find everyone when they come up to talk to us, friend or foe, and let’s also assume that the elements “close” and “closer” refer to how close we let them get in conversation. (Other interpretations would have us living in a neighbourhood of people who hate us, while we have to drive to a different street to sit down for dinner with people who like us.) So all of our friends and enemies are in this circle, but enemies will be closer. That looks like this:

I have more friends than enemies because I’m popular!
So now we have a visual model of what is going on and, if we wanted to, we could build a simple program that says something like “if you’re in this zone, then you’re an enemy, but if you’re in that zone then you’re a friend” where we define the zones in terms of nested circular regions. But, as we know, friend always has your back and enemies stab you in the back, so now we need to add something to that “ME” in the middle – a notion of which way I’m facing – and make sure that I can always see my enemies. Let’s make the direction I’m looking an arrow. (If I could draw better, I’d put glasses on the front. If you’re doing this in the classroom, an actual 3D dummy head shows position really well.) That looks like this:

Same numbers but now I can keep an eye on those enemies!
Now our program has to keep track of which way we’re facing and then it checks the zones, on the understanding that either we’re going to arrange things to turn around if an enemy is behind us, or we can somehow get our enemies to move (possibly by asking nicely). This kind of exercise can easily be carried out by students and it raises all sorts of questions. Do I need all of my enemies to be closer than my friends or is it ok if the closest person to me is an enemy? What happens if my enemies are spread out in a triangle around me? Is they won’t move, do I need to keep rotating to keep an eye on them or is it ok if I stand so that they get as much of my back as they can? What is an acceptable solution to this problem? You might be surprised how much variation students will suggest in possible solutions, as they tell you what makes perfect sense to them for this problem.
When we do this kind of thing with real problems, we are trying to specify the problem to a degree that we remove all of the unasked questions that would otherwise make the problem ambiguous. Of course, even the best specification can stumble if you introduce new information. Some of you will have heard of the term ‘frenemy’, which apparently:
can refer to either an enemy pretending to be a friend or someone who really is a friend but is also a rival (from Wikipedia and around since 1953, amazingly!)
What happens if frenemies come into the mix? Well, in either case, we probably want to treat them like an enemy. If they’re an enemy pretending to be a friend, and we know this, then we don’t turn our back on them and, even in academia, it’s never all that wise to turn your back on a rival, either. (Duelling citations at dawn can be messy.) In terms of our simple model, we can deal with extending the model because we clearly understand what the important aspects are of this very simple situation. It would get trickier if frenemies weren’t clearly enemies and we would have to add more rules to our model to deal with this new group.
This can be played out with students of a variety of ages, across a variety of curricula, with materials as simple as a board, a marker and some checkers. Yet this is a powerful way to explain models, specification and improvement, without having to write a single line of actual computer code or talk about mathematics or bridges! I hope you found it useful.
