
First day at the new (old) job
Posted: January 5, 2026 Filed under: Education | Tags: AI, education, higher education, learning, reflection, teaching, writing Leave a commentI sit at the desk in my new office on Level 5 of the building I’ve been working in for over 10 years, as part of a different university and with a new job title. The foundation universities of the University of Adelaide and the University of South Australia are now officially merged as Adelaide University, which is now roughly the 5th largest University in Australia. I am no longer the Deputy Head of the School of Computer and Mathematical Sciences, as neither the position nor that school still exist! I am an Academic Lead in the School of Computer Science and Information Technology, with responsibilities around educational research and our education specialist staff, and now have roughly 15 staff to manage as part of our new model.
Last year was pretty successful in many ways, the ITiCSE WG delivered an amazing report with some fantastic resources, I was part of a successful grant, the CompEd WG made fantastic progress (still going into the new year as we tidy that up), and I felt like, for the first time in ages, I really had the opportunity to look into research into detail. But it was very tiring, being the last year of a long push that started during the pandemic and finishing in a year where I got so sick that my hair started falling out and my overall physical health took a 10% hit. Much better now, although my hair is still my hair! And now the universities are merged and I’m part of the brand new Adelaide University. It’s a great time to look forward and set some themes for this year. But let’s do a 50,000 foot flyover of my job.
Research: From a research perspective, the CARD WG outcome has reinforced how important it is to have learning resources and tools that lead to the outcomes that you want – this is especially true in the face of the rise of Generative AI, where it is terrifyingly easy to sidestep any cognitive or memory work totally in the production of artefacts. For years, we got away with requiring student to produce something as evidence of a process of production, which entailed cognition, learning, and application of effort over time. Artefacts like the CARD Research Cards can’t be completed with generative AI, people have to interact with them. There are opportunities to engage with something, consider it, respond to it, and develop your skills accordingly. I sketched out some ideas last year about a working group based on tools and approaches for learning that specifically could not be carried out with Generative AI, but haven’t done anything with them. I most likely can’t do any WGs this year for timing and commitment reasons but I might pitch something next year about all the ways that game-based approaches to learning and non-AI-based scalable aspects of personalised learning can be useful in the era of Generative AI. The random and reflexive aspects of the cards make the process inherently focused on the individual – but I’ll return to this thought later. More stuff needs to happen with CARD but that’s a next week thought.
Teaching: I’m teaching a couple of courses this year, mostly around the postgraduate level, working on research skill development and computational research methods. This will be the first curricular application of the CARD system, realised as both physical cards and an online version developed by our fantastic media team in the learning design space. It will be great to be back in the classroom more!
Leadership and Service: I have 15 direct reports and will be getting to know them over the next few weeks. I suspect I’ll be in three places in a given week, my old stomping ground next to the Art Gallery on North Terrace, City West campus, and Mawson Lakes Campus. Learning what they need, and how I can use my experience and knowledge to help them, is one of my highest priorities prior to the start of Semester 1. I have had an unconventional pathway to academia but I still have many lenses of privilege to acknowledge and work through when I work with anybody else. There will be a lot of listening and thinking on my part. I have a number of duties for various SIGCSE roles that I’m looking forward to getting back into now that I’m finally healthy again.
Travel: I’ve been travelling a lot and the plane trips have been frequent, long, and not the best thing for me in any sense. I’m planning to spend about three months in Finland this year as part of a visiting fellowship at University of Jyväskylä but this will involve less flying and more time concentrated in one place. I hope that this will allow me to do better work and be more present…
Speaking of presence, I think that’s my most important theme for this year: present in my personal life, present for my students, present for my research collaborators, and definitely present for my colleagues, especially those who I’m managing. Something has been showing up in my shape at various points of the year but I’m not sure how much of it has been me. Let’s see what I can do this year.
Happy new year, everyone!
ITiCSE 2025: Working Group 1 – exciting news!
Posted: February 14, 2025 Filed under: Education | Tags: computer science education research, education, games, higher education, ITiCSE, learning, play, research, teaching, technology, thinking Leave a commentTwo posts in the same year? Something must be up… and it is! After the successful presentation of Dr Rebecca Vivian and my work at Koli as both DC tool and award winning poster/demo, I looked into taking this to a working group and Dr Miranda Parker agreed to co-lead it with me, as Rebecca is currently on leave. Miranda and I have been digging into all of the aspects of this in the middle of both our day jobs and it’s been a lot of fun to work on! You think you’ve got difficult collaborators? Miranda has to listen to me pontificate about ontologies, paradigms, and philosophies!
It’s really important to recognise Rebecca’s ongoing connection with this project, as it’s still very much Rebecca’s work that got us here and she will continue to be a significant part of this, we’re just making sure we have the co-leadership of people who aren’t on leave to make it work. It’s really exciting that our Workgroup has gone to the advertisement stage!
You can see all of the WG proposals here, and sign up (maybe to ours if you like what you read here) here. We’re happy to answer questions and it’s going to be an amazing combination of serious play, serious research, and great fun.
Here’s the ad as a cut and paste!
WG1 – Paradigms, Methods, and Outcomes, Oh My!: Refining and Evolving a Research Knowledge Development Activity for Computer Science Education
Leaders:
- Nick Falkner, nickolas.falkner@adelaide.edu.au
- Miranda Parker, miranda.parker@uncc.edu
Motivation:
Computer Science Education Research (CSER) combines the frequently quantitative approaches of computer science, engineering, and mathematics with the often more qualitative techniques seen in psychology, sociology, behavioural science, and education. It can be challenging to select appropriate research methods in effective and efficient ways.
Inspired by the use of card-based techniques in the classroom, the Research Alternatives Exercise (RAE) is a pack of 105 cards introducing a wide range of possible research approaches. RAE provides alternatives to a participant’s current research plans using new random lenses, leading to the sketch of a new research design. The participant refers to their own design through the lens of the randomly drawn card, working to see how well this fits, informs, or improves what they have done.
The initial version of the card deck and examples of play won best paper/demo at Koli Calling 2024 and an example “run” is shown below:
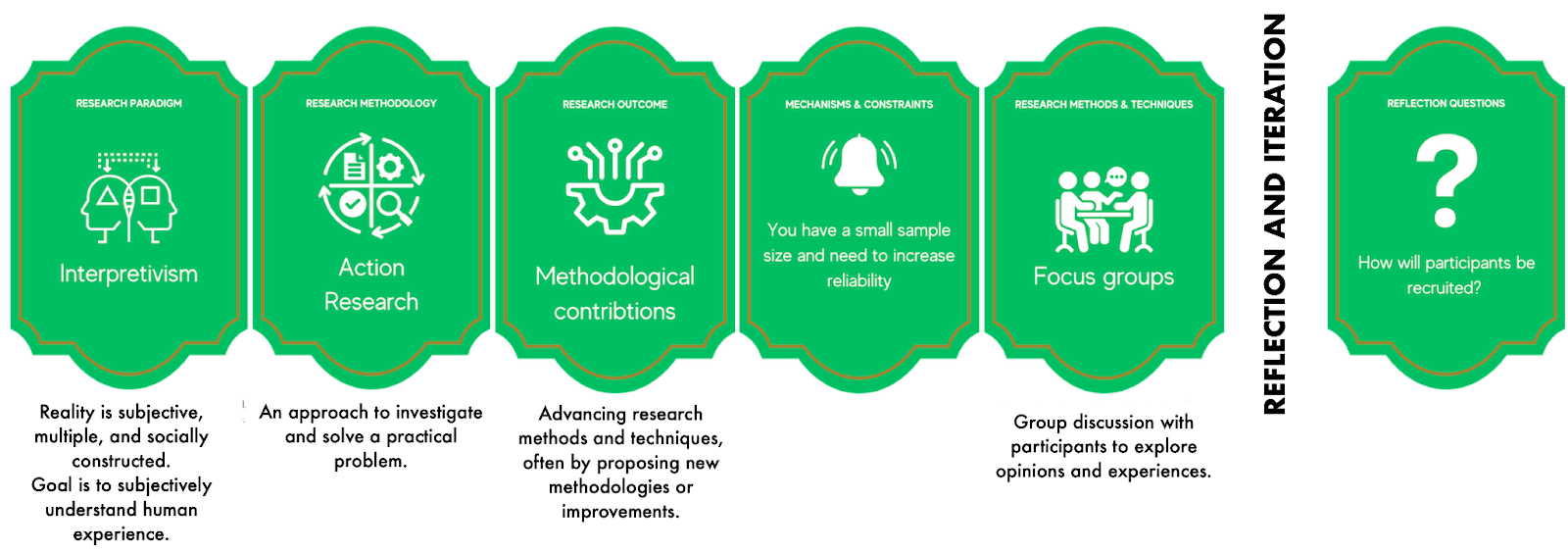
Goals:
- review and modify the existing deck through collaboration in the WG
- develop a version of the deck that can be shared and used widely across the CSER community,
- develop a concise support glossary for the cards
Methodology:
The current deck will be shared with participants, to support targeted literature review, research, and consultation to:
- refine the terminology used for categories, which are currently paradigms, methodologies, outcomes, and methods,
- refine the components within categories,
- review the existing rules for suitability,
- develop the first draft of the support glossary, and
- develop different decks and play approaches for specific purposes.
Following kickoff at the end of March, we will work on Items 1 and 3, aiming for completion by the start of May. When categories are finalized, we will undertake Item 2, where each group member will work in small groups to review each category. Findings will be presented to the whole group by the beginning of June, for further discussion and collaboration. Each sub-group will be responsible for the glossary elements of their contribution, to be completed and reviewed for the start of the in-person WG time. Each working group member will be asked to share the deck with colleagues to provide feedback.
Member Selection:
We seek at least 8-10 individuals to share the required work manageably.
We are looking for participants with at least one of:
- Experience with a wide variety of research methodologies,
- Experience in supervising graduate students,
- Interest and knowledge in using game-based and facilitated techniques, or
- Experience with research skills development.
We actively invite applications from disciplines beyond computing for diversity in research skills development experience. We seek a diversity of experience, background, and culture, to ensure that the feedback encompasses the full range of CSER community experience. We also welcome student applications.
Successful applicants will:
- Attend fortnightly 60-90 minute online progress meetings, held from mid-late March to the end of June,
- Register for ITiCSE 2025,
- Physically attend the full duration of the working group, and
- Make significant contributions during the pre- and post-ITiCSE Working Group activities (3-4 hours a week).
The Year(s) of Replication #las17ed L@S 2017
Posted: April 22, 2017 Filed under: Education, Opinion | Tags: community, education, l@s, las17ed, learning, learning@scale, mit, replication, science, teaching, testing 6 CommentsI was at Koli Calling in 2016 and a paper was presented (“Replication in Computing Education Research: Researcher Attitudes and Experiences”) regarding the issue of replicating previous studies. Why replicate previous work? Because we have a larger number of known issues that have emerged in psychology and the medical sciences, where important work has not been able to be replicated. Perhaps the initial analysis was underpowered, perhaps the researchers had terrible bad luck in their sample, and perhaps there were… other things going on. Whatever the reason, we depend upon replication as a validation tool and being unable to replicate work puts up a red flag.

After the paper, I had follow-up discussions with Andrew Petersen, from U Toronto, and we talked about the many problems. If we do choose to replicate studies, which ones do we choose? How do we get the replication result disseminated, given that it’s fundamentally not novel work? When do we stop replicating? What the heck do we do if we invalidate an entire area of knowledge? Andrew suggested a “year of replication” as a starting point but it’s a really big job: how do we start a year of replication studies or commit to doing this as a community?
This issue was raised again at Learning@Scale 2017 by Justin Reich, from MIT, among others. One of the ideas that we discussed as part of that session was that we could start allocating space at the key conferences in the field for replication studies. The final talk as part of L@S was “Learning about Learning at Scale: Methodological Challenges and Recommendations”, which discussed general problems that span many studies and then made recommendations as to how we could make our studies better and reduce the risk of failing future replication. Justin followed up with comments (which he described as a rant but he’s being harsh) about leaving room to make it easier to replicate and being open to this kind of examination of our work: we’re now thinking about making our current studies easier to replicate and better from the outset, but how can we go back and verify all of the older work effectively?
I love the idea of setting aside a few slots in every conference for replication studies. The next challenge is picking the studies but, given each conference has an organising committee, a central theme, and reviewers, perhaps each conference could suggest a set and then the community identify which ones they’re going to have a look at. We want to minimise unnecessary duplication, after all, so some tracking is probably a good idea.
There are several problems to deal with: some political, some scheduling, some scientific, some are just related to how hard it is to read old data formats. None of them are necessarily insurmountable but we have to be professional, transparent and fair in how we manage them. If we’re doing replication studies to improve confidence in the underlying knowledge of the field, we don’t want to damage the community in doing it.
Let me put out a gentle call to action, perhaps for next year, perhaps for the year after. If you’re involved with a conference, why not consider allocating a few slots to replication studies for the key studies in your area, if they haven’t already been replicated? Even the opportunity to have a community discussion about which studies have been effectively replicated will help identify what we can accept as well as showing us what we could fix.
Does your conference have room for a single track, keynote-level session, to devote some time to replication? I’ll propose a Twitter hashtag of #replicationtrack to discuss this and, hey, if we get a single session in one conference out of this, it’s more than we had.
Our duty to the future, a letter from the 18th Century.
Posted: February 25, 2016 Filed under: Education | Tags: advocacy, education, ethics, higher education, learning, teaching, thinking 1 Comment
Official Presidential Portrait of John Adams (John Trumbull, 1792).
Extract of a letter from John Adams to Abigail Adams, posted 12 May 1780, from Paris.
I could fill Volumes with Descriptions of Temples and Palaces, Paintings, Sculptures, Tapestry, Porcelaine, &c. &c. &c. — if I could have time. But I could not do this without neglecting my duty. The Science of Government it is my Duty to study, more than all other Sciences: the Art of Legislation and Administration and Negotiation, ought to take Place, indeed to exclude in a manner all other Arts. I must study Politicks and War that my sons may have liberty to study Mathematicks and Philosophy. My sons ought to study Mathematicks and Philosophy, Geography, natural History, Naval Architecture, navigation, Commerce and Agriculture, in order to give their Children a right to study Painting, Poetry, Musick, Architecture, Statuary, Tapestry and Porcelaine.
Reflection: Why I’m stopping daily updates
Posted: February 15, 2016 Filed under: Education | Tags: aesthetics, authenticity, beauty, blogging, design, education, ethics, higher education, learning, reflection, teaching, thinking 4 CommentsI’ve written a lot in the past month and a half. Now, because I’m committed to evaluation, I have to look back at all of it and think about some difficult matters:
- Is anyone reading this?
- Are the people reading this the ones who can make change?
- Is the best way to do this?
- Should I be doing something else?
There are roughly 1,000 people who see my posts, between direct subscribers who read in e-mail, Facebook and the elusive following community on Twitter.
Twitter shouldn’t count, as I know from direct experience that the click-through rate from Twitter is tiny. (My posts have been shared by people with 5-10,000 followers and it has turned into maybe 10-20 more people reading.) Now I’m down to maybe 4-500 readers.
Facebook shares a longer fragment of my ideas but the click through is still small. Perhaps this brings me down to the roughly 200 followers I have, who have (over time) contributed about 1,000 ‘Likes’. However, almost all of these positive reinforcements stem from a different phase of the blog, a time when I was blogging conferences and being useful, rather than pontificating on the nature of beauty. My readership used to be 100 people a day, or more. I can’t crack 80 today and the way that I’m blogging is unlikely to reach that larger audience, yet it’s what I want to do.
The answer to 1 is that a few other people a day are reading what I write. I’d put it as high as twenty on a good day but most days it’s under ten.
2’s a tricky question. We can all make change; that’s one of my firmest beliefs. However, there is making change and then there are change makers. I know several people in this area quite well and they read me occasionally but it’s not something that they dedicate time to do. I have people that I always read but I can’t make the changes they need. It’s frustrating. No doubt, my ideas appeal to some people but change takes will and capacity to change, not just a sympathetic ear. I don’t want people to read this and feel trapped because they can’t make change. The answer to 2 is, probably, ‘no’.
3 follows from 1 and 2. If my readership is small and my ideas have little influence then this is not the best way to do things. We face enormous challenges. We need effective mechanisms for sharing information. If I am to make change, I have to invest my time wisely. I am not a large-scale player or a change maker. I need help to do it and if that help isn’t coming from this avenue, I have to choose another.
4 is easier. I can focus on my scholarship, practice, and research, rededicating the time I’ve been spending on this blog. People read papers where they don’t read blogs. Papers drive recognition. Recognition gets you the places to speak where your voice can be heard. There is no point having written all those words in a blog if it’s rarely read. This has been a highly rewarding experience in many ways but you have to wonder why you’re doing it if very few people read it or remember what you’ve written.
I wanted people to think and to talk about the ideas shared here. For those of you who have let me know that this worked, my thanks!
I’m tempted to keep going with the daily blog but the aesthetic argument traps me here. Spending time on something that isn’t working and insisting that it’s valuable is self-deception. Investing energy into an avenue that isn’t achieving your goals isn’t good. I cannot deprive my students of the hour or so a day that I’ve been spending doing this unless I achieve more for them than I would by doing some other aspect of my job.
Students and teachers: the true focus of any aesthetic discussion of education; the most important aspects of any discussion of what we should be doing because they are people and not just machine parts. As for us, so for them.
There are more discussions to be had but they’ll show up in more formal places, most likely. I’m always happy to talk to people about ideas at conferences. I’ve already started a face-to-face discussion about taking some of these ideas further in a more traditional research sense and I’m very excited about that.
But perhaps it’s time to let this blog go, listen to the numbers, reflect on the dissemination of knowledge, and accept that I would not be following my own advice if I were to continue. I love the beauty argument. I think it’s great. I stand by everything I’ve written this year. I just don’t think that this is the way to move people towards that agenda.
Thus, the daily updates stop with this post. I’ll still post things that interest me but there’ll be fewer of them.
I’ll leave you with the message I wanted to get across this year:
- Educational philosophy is full of the aesthetics of education. Dewey and Bloom just scratch the surface of this. The late 19th and early 20th century were an incredible time of upheaval and we still haven’t addressed many of the questions raised then. To the libraries!
- Fair, equitable, well-designed and evidence-based education is at the core of any beautiful system.
- Every day, we should ask ourselves if what we are doing is beautiful, good or true, taking into account all of the difficult questions of how we balance necessities against desirabilities, being honest about which is which. If we aren’t managing this, we need to either seek to change or accept that what we are doing isn’t right.
- We should leave enough time for ourselves in all of this, as there should be no sacrificial element to beautiful education.
- Change is coming. Change is here. Pretending that it won’t happen isn’t beautiful.
I hope that you all have a fantastic learning and teaching year, with many amazing and beautiful moments and outcomes!
This year, I hope to be at several conferences and I look forward to talking to anyone about the ideas in this phase (or any other phase) of the blog.
Have a great year!

Beautiful decomposition
Posted: February 14, 2016 Filed under: Education | Tags: advocacy, aesthetics, authenticity, beauty, blogging, community, competency-based assessment, education, educational problem, educational research, ethics, higher education, in the student's head, learning, small group learning, student perspective, teaching, teaching approaches, Workgroups Leave a commentNow there’s a title that I didn’t expect to write. In this case, I’m referring to how we break group tasks down into individual elements. I’ve already noted that groups like team members who are hard-working, able to contribute and dependable, but we also have the (conflicting) elements from the ideal group where the common goal is more important than individual requirements and this may require people to perform tasks that they are either not comfortable with or ideally suited for.

Kevin was nervous. The group’s mark depended upon him coming up with a “Knock Knock joke” featuring eyes.
How do we assess this fairly? We can look at what a group produces and we can look at what a group does but, to see the individual contribution, there has to be some allocation of sub-tasks to individuals. There are several (let’s call them interesting) ways that people divide up up tasks that we set. Here are three.
- Decomposition into dependent sub-tasks.
- Decomposition into isolated sub-tasks (if possible).
- Decomposition into different roles that spread across different tasks.
Part of working with a group is knowing whether tasks can be broken down, how that can be done successfully, being able to identify dependencies and then putting the whole thing back together to produce a recognisable task at the end.
What we often do with assignment work is to give students identical assignments and they all solemnly go off and solve the same problem (and we punish them if they don’t do enough of this work by themselves). Obviously, then, a group assignment that can be decomposed to isolated sub tasks that have no dependencies and have no assembly requirement is functionally equivalent to an independent assessment, except with some semantic burden of illusory group work.
If we set assignments that have dependent sub-tasks, we aren’t distributing work pressure fairly as students early on in the process have more time to achieve their goals but potentially at the expense of later students. But if the tasks aren’t dependent then we have the problem that the group doesn’t have to perform as a group, they’re a set of people who happen to have a common deadline. Someone (or some people) may have an assembly role at the end but, for the most part, students could work separately.
The ideal way to keep the group talking and working together is to drive such behaviour through necessity, which would require role separation and involvement in a number of tasks across the lifespan of the activity. Nothing radical about that. It also happens to be the hardest form to assess as we don’t have clear task boundaries to work with. However, we also have provided many opportunities for students to demonstrate their ability and to work together, whether as mentor or mentee, to learn from each other in the process.
For me, the most beautiful construction of a group assessment task is found where groups must work together to solve the problem. Beautiful decomposition is, effectively, not a decomposition process but an identification strategy that can pinpoint key tasks while recognising that they cannot be totally decoupled without subverting the group work approach.
But this introduces grading problems. A fluid approach to task allocation can quickly blur neat allocation lines, especially if someone occupies a role that has less visible outputs than another. Does someone get equal recognition for driving ideas, facilitating, the (often dull) admin work or do you have to be on the production side to be seen as valuable?
I know some of you have just come down heavily on one side or the other reading that last line. That’s why we need to choose assessment carefully here.
If you want effective group work, you need an effective group. They have to trust each other, they have to work to individual strengths, and they must be working towards a common goal which is the goal of the task, not a grading goal.
I’m in deep opinion now but I’ve always wondered how many student groups fall apart because we jam together people who just want a pass with people who would kill a baby deer for a high distinction. How do these people have common ground, common values, or the ability to build a mutual trust relationship?
Why do people who just want to go out and practice have to raise themselves to the standards of a group of students who want to get academic honours? Why should academic honours students have to drop their standards to those of people who are happy to scrape by?
We can evaluate group work but we don’t have to get caught up on grading it. The ability to work in a group is a really useful skill. It’s heavily used in my industry and I support it being used as part of teaching but we are working against most of the things we know about the construction of useful groups by assigning grades for knowledge and skill elements that are strongly linked into the group work competency.
Look at how teams work. Encourage them to work together. Provide escape valves, real tasks, things so complex that it’s a rare person who could do it by themselves. Evaluate people, provide feedback, build those teams.
I keep coming back to the same point. So many students dislike group work, we must be doing something wrong because, later in life, many of them start to enjoy it. Random groups? They’re still there. Tight deadlines? Complex tasks? Insufficient instructions? They’re all still there. What matters to people is being treated fairly, being recognised and respected, and having the freedom to act in a way to make a contribution. Administrative oversight, hierarchical relationships and arbitrary assessment sap the will, undermine morale and impair creativity.
If your group task can be decomposed badly, it most likely will be. If it’s a small enough task that one keen person could do it, one keen person probably will because the others won’t have enough of a task to do and, unless they’re all highly motivated, it won’t be done. If a group of people who don’t know each other also don’t have a reason to talk to each other? They won’t. They might show up in the same place if you can trigger a bribe reaction with marks but they won’t actually work together that well.
The will to work together has to be fostered. It has to be genuine. That’s how good things get done by teams.
Valuable tasks make up for poor motivation. Working with a group helps to practise and develop your time management. Combine this with a feeling of achievement and there’s some powerful intrinsic motivation there.
And that’s the fuel that gets complex tasks done.
Aesthetics of group work
Posted: February 13, 2016 Filed under: Education | Tags: aesthetics, authenticity, beauty, community, competency-based assessment, design, education, educational problem, ethics, higher education, in the student's head, learning, small group learning, teaching, teaching approaches, Workgroups Leave a commentWhat are the characteristics of group work and how can we define these in terms that allow us to form a model of beauty about them? We know what most people want from their group members. They want them to be:
- Honest. They do what they say and they only claim what they do. They’re fair in their dealings with others.
- Dependable. They actually do all of what they say they’re going to do.
- Hard-working. They take a ‘reasonable’ time to get things done.
- Able to contribute a useful skill
- A communicator. They let the group know what’s going on.
- Positive, possibly even optimistic.
A number of these are already included in the Socratic principles of goodness and truth. Truth, in the sense of being honest and transparent, covers 1, 2 and possibly even 5. Goodness, that what we set out to do is what we do and this leads to beauty, covers 3 and 4, and I think we can stretch it to 6.
But what about the aesthetics of the group itself? What does a beautiful group look like? Let’s ignore the tasks we often use in group environments and talk about a generic group. A group should have at least some of these (from) :
- Common goals.
- Participation from every member.
- A focus on what people do rather than who they are.
- A focus on what happened rather than how people intended.
- The ability to discuss and handle difference.
- A respectful environment with some boundaries.
- The capability to work beyond authoritarianism.
- An accomodation of difference while understanding that this may be temporary.
- The awareness that what group members want is not always what they get.
- The realisation that hidden conflict can poison a group.
Note how many of these are actually related to the task itself. In fact, of all of the things I’ve listed, none of the group competencies have anything at all to do with a task and we can measure and assess these directly by observation and by peer report.
How many of these are refined by looking at some arbitrary discipline artefact? If anything, by forcing students to work together on a task ‘for their own good’, are we in direct violation of this new number 7, allowing a group to work beyond strict hierarchies?

“I’m carrying my whole team here!”
I’ve worked in hierarchical groups in the Army. The Army’s structure exists for a very specific reason: soldiers die in war. Roles and relationships are strictly codified to drive skill and knowledge training and to ensure smooth interoperation with a minimum of acclimatisation time. I think we can be bold and state that such an approach is not required for third- or fourth-year computer programming, even at the better colleges.
I am not saying that we cannot evaluate group work, nor am I saying that I don’t believe such training to be valuable for students entering the workforce. I just don’t happen to accept that mediating the value of a student’s skills and knowledge through their ability to carry out group competencies is either fair or honest. Item 9, where group members may have to adopt a role that they have identified is not optimal, is grossly unfair when final marks depend upon how the group work channel mediates the perception of your contribution.
There is a vast amount of excellent group work analysis and support being carried out right now, in many places. The problem occurs when we try to turn this into a mark that is re-contextualised into the knowledge frame. Your ability to work in groups is a competency and should be clearly identified as such. It may even be a competency that you need to display in order to receive industry-recognised accreditation. No problems with that.
The hallmarks of traditional student group work are resentment at having to do it, fear that either their own contributions won’t be recognised or someone else’s will dominate, and a deep-seated desire to get the process over with.
Some tasks are better suited to group solution. Why don’t we change our evaluation mechanisms to give students the freedom to explore the advantages of the group without the repercussions that we currently have in place? I can provide detailed evaluation to a student on their group role and tell a lot about the team. A student’s inability to work with a randomly selected team on a fake project with artificial timelines doesn’t say anything that I would be happy to allocate a failing grade to. It is, however, an excellent opportunity for discussion and learning, assuming I can get beyond the tyranny of the grade to say it.
Challenge accepted: beautiful groupwork
Posted: February 12, 2016 Filed under: Education | Tags: advocacy, aesthetics, authenticity, beauty, community, competency-based assessment, design, education, educational problem, educational research, ethics, group work, higher education, in the student's head, learning, resources, small group learning, student perspective, teaching, teaching approaches, thinking Leave a commentYou knew it was coming. The biggest challenge of any assessment model: how do we handle group-based assessment?

Come out! We know that you didn’t hand it in on-time!
There’s a joke that says a lot about how students feel when they’re asked to do group work:
When I die I want my group project members to lower me into my grave so they can let me down one more time.
Everyone has horror stories about group work and they tend to fall into these patterns:
- Group members X and Y didn’t do enough of the work.
- I did all of the work.
- We all got the same mark but we didn’t do the same work.
- Person X got more than I did and I did more.
- Person X never even showed up and they still passed!
- We got it all together but Person X handed it in late.
- Person W said that he/she would do task T but never did and I ended up having to do it.
Let’s consolidate these. People are concerned about a fair division of work and fair recognition of effort, especially where this falls into an allocation of grades. (Point 6 only matters if there are late penalties or opportunities lost by not submitting in time.)
This is totally reasonable! If someone is getting recognition for doing a task then let’s make sure it’s the right person and that everyone who contributed gets a guernsey. (Australian football reference to being a recognised team member.)
How do we make group work beautiful? First, we have to define the aesthetics of group work: which characteristics define the activity? Then we maximise those as we have done before to find beauty. But in order for the activity to be both good and true, it has to achieve the goals that define and we have to be open about what we are doing. Let’s start, even before the aesthetics, and ask about group work itself.
What is the point of group work? This varies by discipline but, usually, we take a task that is too large or complex for one person to achieve in the time allowed and that mimics (or is) a task you’d expect graduates to perform. This task is then attacked through some sort of decomposition into smaller pieces, many of which are dependant in a strict order, and these are assigned to group members. By doing this, we usually claim to be providing an authentic workplace or task-focused assignment.
The problem that arises, for me, is when we try and work out how we measure the success of such a group activity. Being able to function in a group has a lot of related theory (psychological, behavioural, and sociological, at least) but we often don’t teach that. We take a discipline task that we believe can be decomposed effectively and we then expect students to carve it up. Now the actual group dynamics will feature in the assessment but we often measure the outputs associate with the task to determine how effective group formation and management was. However, the discipline task has a skill and knowledge dimension, while the group activity elements have a competency focus. What’s more problematic is that unsuccessful group work can overshadow task achievement and lead to a discounting of skill and knowledge success, through mechanisms that are associated but not necessarily correlated.
Going back to competency-based assessment, we assess competency by carrying out direct observation, indirect measures and through professional reports and references. Our group members’ reports on us (and our reports on them) function in the latter area and are useful sources of feedback, identifying group and individual perceptions as well as work progress. But are these inherently markable? We spend a lot of time trying to balance peer feedback, minimise bullying, minimise over-claiming, and get a realistic view of the group through such mechanisms but adding marks to a task does not make it more cognitively beneficial. We know that.
For me, the problem with most group work assessment is that we are looking at the output of the task and competency based artefacts associated with the group and jamming them together as if they mean something.
Much as I argue against late penalties changing the grade you received, which formed a temporal market for knowledge, I’m going to argue against trying to assess group work through marking a final product and then dividing those grades based on reported contributions.
We are measuring different things. You cannot just add red to melon and divide it by four to get a number and, yet, we are combining different areas, with different intentions, and dragging it into one grade that is more likely to foster resentment and negative association with the task. I know that people are making this work, at least to an extent, and that a lot of great work is being done to address this but I wonder if we can channel all of the energy spent in making it work into getting more amazing things done?
Just about every student I’ve spoken to hates group work. Let’s talk about how we can fix that.
Grades are the fossils of evaluation
Posted: February 6, 2016 Filed under: Education | Tags: advocacy, aesthetics, assessment, authenticity, competency-based assessment, design, education, educational problem, educational research, fossil, higher education, in the student's head, learning, ranking, reflection, resources, student perspective, teaching, teaching approaches, thinking, truth, Wolff 1 CommentAssessments support evaluation, criticism and ranking (Wolff). That’s what it does and, in many cases, that also constitutes a lot of why we do it. But who are we doing it for?
I’ve reflected on the dual nature of evaluation, showing a student her or his level of progress and mastery while also telling us how well the learning environment is working. In my argument to reduce numerical grades to something meaningful, I’ve asked what the actual requirement is for our students, how we measure mastery and how we can build systems to provide this.
But who are the student’s grades actually for?
In terms of ranking, grades allow people who are not the student to place the students in some order. By doing this, we can award awards to students who are in the awarding an award band (repeated word use deliberate). We can restrict our job interviews to students who are summa cum laude or valedictorian or Dean’s Merit Award Winner. Certain groups of students, not all, like to define their progress through comparison so there is a degree of self-ranking but, for the most part, ranking is something that happens to students.
Criticism, in terms of providing constructive, timely feedback to assist the student, is weakly linked to any grading system. Giving someone a Fail grade isn’t a critique as it contains no clear identification of the problems. The clear identification of problems may not constitute a fail. Often these correlate but it’s weak. A student’s grades are not going to provide useful critique to the student by themselves. These grades are to allow us to work out if the student has met our assessment mechanisms to a point where they can count this course as a pre-requisite or can be awarded a degree. (Award!)
Evaluation is, as noted, useful to us and the student but a grade by itself does not contain enough record of process to be useful in evaluating how mastery goals were met and how the learning environment succeeded or failed. Competency, when applied systematically, does have a well-defined meaning. A passing grade does not although there is an implied competency and there is a loose correlation with achievement.
Grades allow us to look at all of a student’s work as if this one impression is a reflection of the student’s involvement, engagement, study, mistakes, triumphs, hopes and dreams. They are additions to a record from which we attempt to reconstruct a living, whole being.
Grades are the fossils of evaluation.
Grades provide a mechanism for us, in a proxy role as academic archaeologist, to classify students into different groups, in an attempt to project colour into grey stone, to try and understand the ecosystem that such a creature would live in, and to identify how successful this species was.
As someone who has been a student several times in my life, I’m aware that I have a fossil record that is not traditional for an academic. I was lucky to be able to place a new imprint in the record, to obscure my history as a much less successful species, and could then build upon it until I became an ACADEMIC TYRANNOSAURUS.

LIFE LONG LEARNING, ROAARRRR!
But I’m lucky. I’m privileged. I had a level of schooling and parental influence that provided me with an excellent vocabulary and high social mobility. I live in a safe city. I have a supportive partner. And, more importantly, at a crucial moment in my life, someone who knew me told me about an opportunity that I was able to pursue despite the grades that I had set in stone. A chance came my way that I never would have thought of because I had internalised my grades as my worth.
Let’s look at the fossil record of Nick.
My original GPA fossil, encompassing everything that went wrong and right in my first degree, was 2.9. On a scale of 7, which is how we measure it, that’s well below a pass average. I’m sharing that because I want you to put that fact together with what happened next. Four years later, I started a Masters program that I finished with a GPA of 6.4. A few years after the masters, I decided to go and study wine making. That degree was 6.43. Then I received a PhD, with commendation, that is equivalent to GPA 7. (We don’t actually use GPA in research degrees. Hmmm.) If my grade record alone lobbed onto your desk you would see the desiccated and dead snapshot of how I (failed to) engage with the University system. A lot of that is on me but, amazingly, it appears that much better things were possible. That original grade record stopped me from getting interviews. Stopped me from getting jobs. When I was finally able to demonstrate the skills that I had, which weren’t bad, I was able to get work. Then I had the opportunity to rewrite my historical record.
Yes, this is personal for me. But it’s not about me because I wasn’t trapped by this. I was lucky as well as privileged. I can’t emphasise that enough. The fact that you are reading this is due to luck. That’s not a good enough mechanism.
Too many students don’t have this opportunity. That impression in the wet mud of their school life will harden into a stone straitjacket from which they may never escape. The way we measure and record grades has far too much potential to work against students and the correlation with actual ability is there but it’s not strong and it’s not always reliable.
The student you are about to send out with a GPA of 2.9 may be competent and they are, most definitely, more than that number.
The recording of grades is a high-loss storage record of the student’s learning and pathway to mastery. It allows us to conceal achievement and failure alike in the accumulation of mathematical aggregates that proxy for competence but correlate weakly.
We need assessment systems that work for the student first and everyone else second.
How does competency based assessment work?
Posted: February 5, 2016 Filed under: Education | Tags: aesthetics, authenticity, Bloom, competency-based assessment, education, educational problem, educational research, higher education, learning, resources, student perspective, teaching, teaching approaches, thinking, tools Leave a commentFrom the previous post, I asked how many times a student has to perform a certain task, and to which standard, that we become confident that they can reliably perform the task. In the Vocational Education and Training world this is referred to as competence and this is defined (here, from the Western Australian documentation) as:
In VET, individuals are considered competent when they are able to consistently apply their knowledge and skills to the standard of performance required in the workplace.
How do we know if someone has reached that level of competency?
We know whether an individual is competent after they have completed an assessment that verifies that all aspects of the unit of competency are held and can be applied in an industry context.
The programs involved are made up of units that span the essential knowledge and are assessed through direct observation, indirect measurements (such as examination) and in talking to employers or getting references. (And we have to be careful that we are directly measuring what we think we are!)

A direct measurement of your eyesight or your ability to memorise Czech eye-charts.
But it’s not enough just to do these tasks as you like, the specification is quite clear in this:
It can be demonstrated consistently over time, and covers a sufficient range of experiences (including those in simulated or institutional environments).
I’m sure that some of you are now howling that many of the things that we teach at University are not just something that you do, there’s a deeper mode of thinking or something innately non-Vocational about what is going on.
And, for some of you, that’s true. Any of you who are asking students to do anything in the bottom range of Bloom’s taxonomy… I’m not convinced. Right now, many assessments of concepts that we like to think of as abstract are so heavily grounded in the necessities of assessment that they become equivalent to competency-based training outcomes.
The goal may be to understand Dijkstra’s algorithm but the task is to write a piece of code that solves the algorithm for certain inputs, under certain conditions. This is, implicitly, a programming competency task and one that must be achieved before you can demonstrate any ability to show your understanding of the algorithm. But the evaluator’s perspective of Dijkstra is mediated through your programming ability, which means that this assessment is a direct measure of programming ability in language X but an indirect measure of Dijkstra. Your ability to apply Dijkstra’s algorithm would, in a competency-based frame, be located in a variety of work-related activities that could verify your ability to perform the task reliably.
All of my statistical arguments on certainty from the last post come back to a simple concept: do I have the confidence that the student can reliably perform the task under evaluation? But we add to this the following: Am I carrying out enough direct observation of the task in question to be able to make a reliable claim on this as an evaluator?
There is obvious tension, at modern Universities, between what we see as educational and what we see as vocational. Given that some of what we do falls into “workplace skills” in a real sense, although we may wish to be snooty about the workplace, why are we not using the established approaches that allow us to actually say “This student can function as an X when they leave here?”
If we want to say that we are concerned with a more abstract education, perhaps we should be teaching, assessing and talking about our students very, very differently. Especially to employers.
