
ITiCSE 2014, Day 2, Session4A, Software Engineering, #ITiCSE2014 #ITiCSE
Posted: June 24, 2014 Filed under: Education | Tags: collaboration, computer science education, education, educational problem, educational research, higher education, industry, ITiCSE, ITiCSE 2014, learning, mentoring, pair programming, pedagogy, principles of design, project based learning, small group learning, student perspective, studio based learning, teaching, teaching approaches, thinking, time, time factors, time management, universal principles of design, work-life balance Leave a comment- People: learning community
teachers and learners - Process: creative , reflective
- interactions
- physical space
- collaboration
- Product: designed object – a single focus for the process
- Intra-Group Relations: Group 1 has lots of strong characters and appeared to be competent and performing well, with students in group learning about Scrum from each other. Group 2 was more introverted, with no dominant or strong characters, but learned as a group together. Both groups ended up being successful despite the different paths. Collaborative learning inside the group occurred well, although differently.
- Inter-Group Relations: There was good collaborative learning across and between groups after the middle of the semester, where initially the groups were isolated (and one group was strongly focused on winning a prize for best project). Groups learned good practices from observing each other.
ITiCSE 2014, Session 3C: Gender and Diversity, #ITiCSE2014 #ITiCSE @patitsel
Posted: June 24, 2014 Filed under: Education | Tags: advocacy, authenticity, community, computer science, design, education, educational problem, educational research, Elizabeth Patitsas, equality, ethics, gender roles, higher education, ITiCSE, ITiCSE 2014, learning, mentoring, sexism, sexism in computer science, students, teaching approaches, thinking 1 CommentThis sessions was dedicated to the very important issues of gender and diversity. The opening talk in this session was “A Historical Examination of the Social Factors Affecting Female Participation in Computing”, presented by Elizabeth Patitsas (@patitsel). This paper was a literature review of the history of the social factors affecting the old professional association of the word “computer” with female arithmeticians to today’s very male computing culture. The review spanned 73 papers, 5 books, 2 PhD theses and a Computing Educators Oral History project. The mix of sources was pretty diverse. The two big caveats were that it only looked at North America (which means that the sources tend to focus on Research Intensive universities and white people) and that this is a big picture talk, looking at social forces rather than individual experiences. This means that, of course, individuals may have had different experiences.
The story begins in the 19th Century, when computer was a job and this was someone who did computations, for scientists, labs, or for government. Even after first wave feminism, female education wasn’t universally available and the women in education tended to be women of privilege. After the end of the 19th century, women started to enter traditional universities to attempt to study PhDs (although often receiving a Bachelors for this work) but had few job opportunities on graduation, except teaching or being a computer. Whatever work was undertaken was inherently short-term as women were expected to leave the work force on marriage, to focus on motherhood.
During the early 20th Century, quantitative work was seen to be feminine and qualitative work required the rigour of a man – things have changed in perceptions, haven’t they! The women’s work was grunt work: calculating, microscopy. Then there’s men’s work: designing and analysing. The Wars of the 20th Century changed this by removing men and women stepping into the roles of men. Notably, women were stereotyped as being better coders in this role because of their computer background. Coding was clerical, performed by a woman under the direction of a male supervisor. This became male typed over time. As programming became more developed over the 50s and 60s and the perception of it as a dark art started to form a culture of asociality. Random hiring processes started to hurt female participation, because if you are hiring anyone then (quitting the speaker) if you could hire a man, why hire a woman? (Sound of grinding teeth from across the auditorium as we’re all being reminded of stupid thinking, presented very well for our examination by Elizabeth.)
CS itself stared being taught elsewhere but became its own school-discipline in the 60s and 70s, with enrolment and graduation of women matching that of physics very closely. The development of the PC and its adoption in the 80s changed CS enrolments in the 80s and CS1 became a weeder course to keep the ‘under qualified’ from going on to further studies in Computer Science. This then led to fewer non-traditional CS students, especially women, as simple changes like requiring mathematics immediately restricted people without full access to high quality education at school level.
In the 90s, we all went mad and developed hacker culture based around the gamer culture, which we already know has had a strongly negative impact on female participation – let’s face it, you don’t want to be considered part of a club that you don’t like and goes to effort to say it doesn’t welcome you. This led to some serious organisation of women’s groups in CS: Anita Borg Institute, CRA-W and the Grace Hopper Celebration.
Enrolments kept cycling. We say an enrolment boom and bust (including greater percentage of women) that matched the dot-com bubble. At the peak, female enrolment got as high as 30% and female faculty also increased. More women in academia corresponded to more investigation of the representation of women in Computer Science. It took quite a long time to get serious discussions and evidence identifying how systematic the under-representation is.
Over these different decades, women had very different experiences. The first generation had a perception that they had to give up family, be tough cookies and had a pretty horrible experience. The second generation of STEM, in 80s/90s, had female classmates and wanted to be in science AND to have families. However, first generation advisers were often very harsh on their second generation mentees as their experiences were so dissimilar. The second generation in CS doesn’t match neatly that of science and biology due to the cycles and the negative nerd perception is far, far stronger for CS than other disciplines.
Now to the third generation, starting in the 00s, outperforming their male peers in many cases and entering a University with female role models. They also share household duties with their partners, even when both are working and family are involved, which is a pretty radical change in the right direction.
If you’re running a mentoring program for incoming women, their experience may be very. very different from those of the staff that you have to mentor them. Finally, learning from history is essential. We are seeing more students coming in than, for a number of reasons, we may be able to teach. How will we handle increasing enrolments without putting on restrictions that disproportionately hurt our under-represented groups? We have to accept that most of our restrictions actually don’t apply in a uniform sense and that this cannot be allowed to continue. It’s wrong to get your restrictions in enrolment at a greater expense on one group when there’s no good reason to attack one group over another.
One of the things mentioned is that if you ask people to do something because of they are from group X, and make this clear, then they are less likely to get involved. Important note: don’t ask women to do something because they’re women, even if you have the intention to address under-representation.
The second paper, “Cultural Appropriation of Computational Thinking Acquisition Research: Seeding Fields of Diversity”, presented by Martha Serra, who is from Brazil and good luck to them in the World Cup tonight! Brazil adapted scalable game design to local educational needs, with the development of a web-ased system “PoliFacets”, seeding the reflection of IT and Educational researchers.
Brazil is the B in BRICS, with nearly 200 million people and the 5th largest country in the World. Bigger than Australia! (But we try harder.) Brazil is very regionally diverse: rain forest, wetlands, drought, poverty, Megacities, industry, agriculture and, unsurprisingly, it’s very hard to deal with such diversity. 80% of youth population failed to complete basic education. Only 26% of the adult population reach full functional literacy. (My jaw just dropped.)
Scalable Game Design (SGD) is a program from the University of Colorado in Boulder, to motivate all students in Computer Science through game design. The approach uses AgentSheets and AgentsCubes as visual programming environments. (The image shown was of a very visual programming language that seemed reminiscent of Scratch, not surprising as it is accepted that Scratch picked up some characteristics from AgentSheets.)
The SGD program started as an after-school program in 2010 with a public middle school, using a Geography teacher as the program leader. In the following year, with the same school, a 12-week program ran with a Biology teacher in charge. Some of the students who had done it before had, unfortunately, forgotten things by the next year. The next year, a workshop for teachers was introduced and the PoliFacets site. The next year introduced more schools, with the first school now considered autonomous, and the teacher workshops were continued. Overall, a very positive development of sustainable change.
Learners need stimulation but teachers need training if we’re going to introduce technology – very similar to what we learned in our experience with digital technologies.
The PolFacets systems is a live documentation web-based system used to assist with the process. Live demo not available as the Brazilian corner of internet seems to be full of football. It’s always interesting to look at a system that was developed in a different era – it makes you aware how much refactoring goes into the IDEs of modern systems to stop them looking like refugees from a previous decade. (Perhaps the less said about the “Mexican Frogger” game the better…)
The final talk (for both this session and the day) was “Apps for Social Justice: Motivating Computer Science Learning with Design and Real-World Problem Solving”, presented by Sarah Van Wart. Starting with motivation, tech has diversity issues, with differential access and exposure to CS across race and gender lines. Tech industry has similar problems with recruiting and retaining more diverse candidates but there are also some really large structural issues that shadow the whole issue.
Structurally, white families have 18-20 times the wealth of Latino and African-American people, while jail population is skewed the opposite way. The schools start with the composition of the community and are supposed to solve these distribution issues, but instead they continue to reflect the composition that they inherited. US schools are highly tracked and White and Asian students tend to track into Advanced Placement, where Black and Latino students track into different (and possibly remedial) programs.
Some people are categorically under-represented and this means that certain perspectives are being categorically excluded – this is to our detriment.
The first aspect of the theoretical prestige is Conceptions of Equity. Looking at Jaime Escalante, and his work with students to do better at the AP calculus exam. His idea of equity was access, access to a high-value test that could facilitate college access and thus more highly paid careers. The next aspect of this was Funds of Knowledge, Gonzalez et al, where focusing on a white context reduces aspects of other communities and diminishes one community’s privilege. The third part, Relational Equity (Jo Boaler), reduced streaming and tracking, focusing on group work, where each student was responsible for each student’s success. Finally,Rico Gutstein takes a socio-political approach with Social Justice Pedagogy to provide authentic learning frameworks and using statistics to show up the problems.
The next parts of the theoretical perspective was Computer Science Education, and Learning Sciences (socio-cultrual perspective on learning, who you are and what it means to be ‘smart’)
In terms of learning science, Nasir and Hand, 2006, discussed Practice-linked Identities, with access to the domain (students know what CS people do), integral roles (there are many ways to contribute to a CS project) and self-expression and feeling competent (students can bring themselves to their CS practice).
The authors produced a short course for a small group of students to develop a small application. The outcome was BAYP (Bay Area Youth Programme), an App Inventor application that queried a remote database to answer user queries on local after-school program services.
How do we understand this in terms of an equity intervention? Let’s go back to Nasir and Hand.
- Access to the domain: Design and data used together is part of what CS people do, bridging students’ concepts and providing an intuitive way of connecting design to the world. When we have data, we can get categories, then schemas and so on. (This matters to CS people, if you’re not one. 🙂 )
- Integral Roles: Students got to see the importance of design, sketching things out, planning, coding, and seeing a segue from non-technical approaches to technical ones. However, one other very important aspect is that the oft-derided “liberal arts” skills may actually be useful or may be a good basis to put coding upon, as long as you understand what programming is and how you can get access to it.
- Making a unique contribution: The students felt that what they were doing was valuable and let them see what they could do.
Take-aways? CS can appeal to so many peopleif we think about how to do it. There are many pathways to help people. We have to think about what we can be doing to help people. Designing for their own community is going to be empowering for people.
Sarah finished on some great questions. How will they handle scaling it up? Apprenticeship is really hard to scale up but we can think about it. Does this make students want to take CS? Will this lead to AP? Can it be inter-leaved with a project course? Could this be integrated into a humanities or social science context? Lots to think about but it’s obvious that there’s been a lot of good work that has gone into this.
What a great session! Really thought-provoking and, while it was a reminder for many of us how far we have left to go, there were probably people present who had heard things like this for the first time.
ITiCSE 2014: Monday, Keynote 1, “New Technology, New Learning?” #ITiCSE2014 #ITiCSE
Posted: June 23, 2014 Filed under: Education | Tags: active learning, ambient wood, authenticity, co-creation, collaborative learning, community, computer science education, context, curriculum, education, educational problem, educational research, gamification, higher education, in the student's head, ITiCSE, ITiCSE 2014, learning, MOOC, panopticon, passive learning, peer instruction, peerwise, social media, students, teaching, teaching approaches, thinking Leave a commentThis keynote was presented by Professor Yvonne Rogers, from University College of London. The talk was discussing how we could make learning more accessible and exciting for everyone and encourage students to think, to create and share our view. Professor Rogers started by sharing a tweet by Conor Gearty on a guerrilla lecture, with tickets to be issued at 6:45pm, for LSE students. (You can read about what happened here.) They went to the crypt of Westminster Cathedral and the group, split into three smaller groups, ended up discussing the nature of Hell and what it entailed. This was a discussion on religion but, because of the way that it was put together, it was more successful than a standard approach – context shift, suspense driving excitement and engagement. (I wonder how much suspense I could get with a guerrilla lecture on polymorphism… )
Professor Rogers says that suspense matters, as the students will be wondering what is coming next, and this will hopefully make them more inquisitive and thus drive them along the path to scientific enquiry. The Ambient Wood was a woodland full of various technologies for student pairs, with technology and probes, an explorative activity. You can read about the Ambient Wood here. The periscope idea ties videos into the direction that you are looking – a bit like Google Glass without a surveillance society aspect (a Woodopticon?). (We worked on similar ideas at Adelaide for an early project in the Arts Precinct to allow student exploration to drive the experience in arts, culture and botanical science areas.) All of the probes were recorded in the virtual spatial environment matching the wood so that, after the activity, the students could then look at what they did. Thus, a group of 10-12 year olds had an amazing day exploring and discovering, but in a way that was strongly personalised, with an ability to see it from the bird’s eye view above them.
And, unsurprisingly, we moved on to MOOCs, with an excellent slide on MOOC HYSTERIA. Can we make these as engaging as the guerrilla lecture or the ambient wood?

MOOCs, as we know, are supposed to increase our reach and access to education but, as Professor Rogers noted, it is also a technology that can make the lecturer a “bit of a star”. This is one of the most honest assessments of some of the cachet that I’ve heard – bravo, Professor Rogers. What’s involved in a MOOC? Well, watching things, doing quizzes, and there’s probability a lot of passive, rather than active, learning. Over 60% of the people who sign up to do a MOOC, from the Stanford experience, have a degree – doing Stanford for free is a draw for the already-degreed. How can we make MOOCs fulfil their promise, give us good learning, give us active learning and so on? Learning analytics give us some ideas and we can data mine to try and personalise the course to the student. But this has shifted what our learning experience is and do we have any research to show the learning value of MOOCs?
In 2014, 400 students taking a Harvard course:
- Learned in a passive way
- Just want to complete
- Take the easy option
- Were unable to apply what they learned
- Don’t reflect on or talk to their colleagues about it.
Which is not what we want? What about the Flipped Classroom? Professor Rogers attributed this to Khan but I’m not sure I agree with this as there were people, Mazur for example, who were doing this in Peer Instruction well before Khan – or at least I thought so. Corrections in the questions please! The idea of the flip is that we don’t have content delivery in lectures with the odd question – we have content beforehand and questions in class. What is the reality?
- Still based on chalk and talk.
- Is it simply a better version of a bad thing?
- Are students more motivated and more active?
- Very labour-intensive for the teacher.
So where’s the evidence? Well, it does increase interaction in class between instructors and students. It does allow for earlier identification of misconceptions. Pierce and Fox, 2012, found that it increased exam results for pharmacology students. It also fostered critical thinking in case scenarios. Maybe this will work for 10s-100s – what about classes of thousands? Can we flip to this? (Should we even have classes of this size is another good question)
Then there’s PeerWise, Paul Denny (NZ), where there is active learning in which students create questions, answer them and get feedback. Students create the questions and then they get to try other student’s questions and can then rate the question and rate the answer. (We see approaches like this, although not as advanced, in other technologies such as Piazza.)
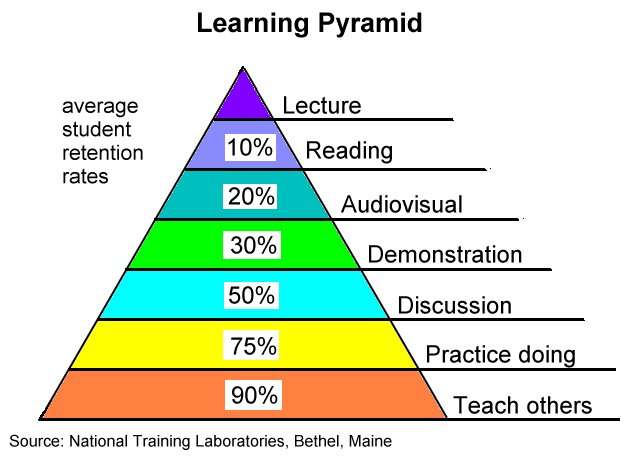
How effective is this? Performance in PeerWise correlated with exam marks (Anyadi, Green and Tang, 2013), with active student engagement. It’s used for revision before the exams, and you get hihg-quality questions and answers, while supporting peer interaction. Professor Rogers then showed the Learning Pyramid, from the National Training Laboratories, Bethel, Maine. The PeerWise system plays into the very high retention area.
Professor Rogers then moved on to her own work, showing us a picture of the serried rank nightmare of a computer-based classroom: students in rows, isolated and focused on their screens. Instead of ‘designing for one’, why don’t we design to orchestrate shared activities, with devices that link to public displays and can actively foster collaboration. One of Professor Rogers’ students is looking at ways to share simulations across tablets and screens. This included “4Decades“, a a simulation of climate management, with groups representing the different stakeholders to loo at global climate economics. We then saw a video that I won’t transcribe. The idea is that group work encourages discussion, however we facilitate it, and this tends to leading to teaching others in the sharing of ideas. Another technology that Professor Rogers’ group have developed in this space is UniPad: orchestrating collaborate activities across multiple types of devices, with one device per 6-7 students, and used in classes without many researchers present. Applications of this technology include budgeting for students (MyBank), with groups interacting and seeing the results on a public display. Given how many students operate in share houses collaboratively, this is quite an interesting approach to the problem. From studies on this, all group members participated and used the tablet as a token for discussion, taking ownership of a part of the problem. This also extended to reflection on other’s activities, including identifying selfish behaviour on the part of other people. (Everyone who has had flatmates is probably groaning at the moment. Curse you, Love Tarot Pay-By-The-Minute Telephone Number, which cost me and my flatmates a lot of dollars after a flatmate skipped out on us.)
The next aspect Professor Rogers discussed was physical creation toolkits, such as MaKey MaKey, where you can build alternative input for a computer, based on a simple printed circuit board with alligator clips and USB cables. The idea is simple: you can turn anything you like into a keyboard key. Demonstrations included a banana space bar, a play dough MarioKart gamepad, and many other things (a water bowl in front of the machine became a cat-triggered photo booth). This highlights one of the most important aspects of thinking about learning: learning for life. How can we keep people interested in learning in the face of busy, often overfull, lives when many people still think about learning as something that had to be endured on their pathway into the workforce? (Paging my climbing friends with their own climbing wall: you could make the wall play music if you wanted to. Just saying.)
One of the computers stopped working during a trial of the MaKey MaKey system with adult learners and the collaboration that ensued changed the direction of the work and more people were assigned to a single kit. Professor Rogers showed a small video of a four-person fruit orchestra of older people playing Twinkle Twinkle Little Star. (MORE KIWI!) This elicited a lot of ideas, including for their grandchildren and own parent, transforming exercise to be more fun, to help people learn fundamental knowledge skills and give good feedback. We often heavily intervene in the learning experience and the reflection of the Fruit Orchestra was that intervening less in self-driven activities such as MaKey MaKey might be a better way to go, to increase autonomy and thus drive engagement.
Next was the important question: How can we gets to create and code, where coding is just part of the creating? Can we learn to code differently beyond just choosing a particular language? We have many fascinating technologies but what is the suite of tools over the top that will drive creativity and engagement in this area, to produce effective learning? The short video shown demonstrated a pop-out prefabricated system, where physical interfaces and gestures across those represented coding instructions: coding without any typing at all. (Previous readers will remember my fascination with pre-literate programming.) This early work, electronics on a sheet, is designed to be given away because the production cost is less than 3 Euros. The project is called “code me” from University College London and is designed to teach logic without people realising it: the fundamental building block of computational thinking. Future work includes larger blocks with Bluetooth input and sensors. (I can’t find a web page for this.)
What role should technology play in learning? Professor Rogers mentioned thinking about this in two ways. The inside learning using technology to think about the levels students to reach to foster attainment: personalise, monitor, motivate, flexible, adaptive. The outside learning approach is to work with other people away from the screen: collaborate, create, connect, reflect and play. Professor Rogers believes that the choice is ours but that technology should transform learning to make it active, creative, collaborative, exciting (some other things I didn’t catch) and to recognise the role of suspense in making people think.
An interesting and thought-provoking keynote.
CSEDU, Day 1, Keynote 2, “Mathematics Teaching: is the future syncretic?” (#csedu14 #csedu #AdelEd)
Posted: April 2, 2014 Filed under: Education | Tags: blogging, community, computer science education, computer supported education, csedu14, design, education, educational problem, heresy, learning, student perspective, students, syncretic, teaching approaches, thinking Leave a commentThis is an extension of the position paper that was presented this morning. I must be honest and say that I have a knee-jerk reaction when I run across titles like this. There’s always the spectre of Rand or Gene Ray in compact phrases of slightly obscure terminology. (You should probably ignore me, I also twitch every time I run across digital hermeneutics and that’s perfectly legitimate.) The speaker is Larissa Fradkin who is trying to improve the quality of mathematics teaching and overall interest in mathematics – which is a good thing and so I should probably be far more generous about “syncretic”. Let’s review the definition of syncretic:
Again, from Wikipedia, Syncretism /ˈsɪŋkrətɪzəm/ is the combining of different, often seemingly contradictory beliefs, while melding practices of various schools of thought. (The speaker specified this to religious and philosophical schools of thought.)
There’s a reference in the talk to gnosticism, which combined oriental mysticism, Judaism and Christianity. Apparently, in this talk we are going to have myths debunked regarding the Maths Wars of Myths, including traditionalist myths and constructivist myths. Then discuss the realities in the classroom.
Two fundamental theories of learning were introduced: traditionalist and constructivist. Apparently, these are drummed into poor schoolteachers and yet we academics are sadly ignorant of these. Urm. You have to be pretty confident to have a go at Piaget: “Piaget studied urchins and then tried to apply it to kids.” I’m really not sure what is being said here but the speaker has tried to tell two jokes which have fallen very flat and, regrettably, is making me think that she doesn’t quite grasp what discovery learning is. Now we are into Guided Teaching and scaffolding with Vygotsky, who apparently, as a language teacher, was slightly better than a teacher of urchins.
The first traditionalist myth is that intelligence = implicit memory (no conscious awareness) + basic pattern recognition. Oh, how nice, the speaker did a lot of IQ tests and went from 70 to 150 in 5 tests. I don’t think many people in the serious educational community places much weight on the assessment of intelligence through these sorts of test – and the objection to standardised testing is coming from the edu research community of exactly those reasons. I commented on this speaker earlier and noted that I felt that she was having an argument that was no longer contemporary. Sadly, my opinion is being reinforced. The next traditionalist myth is that mathematics should be taught using poetry, other mnemonics and coercion.
What? If the speaker is referring to the memorisation of the multiplication tables, we are taking about a definitional basis for further development that occupies a very short time in the learning phase. We are discussing a type of education that is already identified as negative as if the realisation that mindless repetition and extrinsic motivational factors are counter-productive. Yes, coercion is an old method but let’s get to what you’re proposing as an alternative.
Now we move on to the constructivist myths. I’m on the edge of my seat. We have a couple of cartoons which don’t do anything except recycle some old stereotypes. So, the first myth is “Only what students discover for themselves is truly learned.” So the problem here is based on Rebar, 2007, met study. Revelation: Child-centred, cognitively focused and open classroom approaches tend to perform poorly.
Hmm, not our experience.
The second myth is both advanced and debunked by a single paper, that there are only two separate and distinct ways to teach mathematics: conceptual understanding and drills. Revelation: Conceptual advanced are invariably built on the bedrock of technique.
Myth 3: Math concepts are best understood and mastered when presented in context, in that way the underlying math concept will follow automatically. The speaker used to teach with engineering examples but abandoned them because of the problem of having to explain engineering problems, engineering language and then the problem. Ah, another paper from Hung-Hsi Wu, UCB, “The Mathematician and Mathematics Education Reform.” No, I really can’t agree with this as a myth. Situated learning is valid and it works, providing that the context used is authentic and selected carefully.
Ok, I must confess that I have some red flags going up now – while I don’t know the work of Hung-Hsi Wu, depending on a single author, especially one whose revelatory heresy is close to 20 years old, is not the best basis for a complicated argument such as this. Any readers with knowledge in this should jump on to the comments and get us informed!
Looking at all of these myths, I don’t see myths, I see straw men. (A straw man is a deliberately weak argument chosen because it is easy to attack and based on a simplified or weaker version of the problem.)
I’m in agreement with many of the outcomes that Professor Fradkin is advocating. I want teachers to guide but believe that they can do it in the constriction of learning environments that support constructivist approaches. Yes, we should limit jargon. Yes, we should move away from death-by-test. Yes, Socratic dialogue is a great way to go.
However, as always, if someone says “Socratic dialogue is the way to go but I am not doing it now” then I have to ask “Why not?” Anyone who has been to one of my sessions knows that when I talk about collaboration methods and student value generation, you will be collaborating before your seat has had a chance to warm up. It’s the cornerstone of authentic teaching that we use the methods that we advocate or explain why they are not suitable – cognitive apprenticeship requires us to expose our selves as we got through the process we’re trying to teach!
Regrettably, I think my initial reaction of cautious mistrust of the title may have been accurate. (Or I am just hopelessly biassed by an initial reaction although I have been trying to be positive.) I am trying very hard to reinterpret what has been said. But there is a lot of anecdote and dependency upon one or two “visionary debunkers” to support a series of strawmen presented as giant barriers to sensible teaching.
Yes, listening to students and adapting is essential but this does not actually require one to abandon constructivist or traditionalist approaches because we are not talking about the pedagogy here, we’re talking about support systems. (Your take on that may be different.)
There is some evidence presented at the end which is, I’m sorry to say, a little confusing although there has obviously been a great deal of success for an unlisted, uncounted number and unknown level of course – success rates improved from 30 passing to 70% passing and no-one had to be trained for the exam. I would very much like to get some more detail on this as claiming that the syncretic approach is the only way to reach 70% is essential is a big claim. Also, a 70% pass rate is not all that good – I would get called on to the carpet if I did that for a couple of offerings. (And, no, we don’t dumb down the course to improve pass rate – we try to teach better.)
Now we move into on-line techniques. Is the flipped classroom a viable approach? Can technology “humanise” the classroom? (These two statements are not connected, for me, so I’m hoping that this is not an attempt to entail one by the other.) We then moved on to a discussion of Khan, who Professor Fradkin is not a fan of, and while her criticisms of Khan are semi-valid (he’s not a teacher and it shows), her final statement and dismissal of Khan as a cram-preparer is more than a little unfair and very much in keeping with the sweeping statements that we have been assailed by for the past 45 minutes.
I really feel that Professor Fradkin is conflating other mechanisms with blended and flipped learning – flipped learning is all about “me time” to allow students to learn at their own pace (as she notes) but then she notes a “Con” of the Khan method of an absence of “me time”. What if students don’t understand the recorded lectures at all? Well… how about we improve the material? The in-class activities will immediately expose faulty concept delivery and we adapt and try again (as the speaker has already noted). We most certainly don’t need IT for flipped learning (although it’s both “Con” point 3 AND 4 as to why Khan doesn’t work), we just need to have learning occur before we have the face-to-face sessions where we work through the concepts in a more applied manner.
Now we move onto MOOCs. Yes, we’re all cautious about MOOCs. Yes, there are a lot of issues. MOOCs will get rid of teachers? That particular strawman has been set on fire, pushed out to sea, brought back, set on fire again and then shot into orbit. Where they set it on fire again. Next point? Ok, Sebastian Thrun made an overclaim that the future will have only 10 higher ed institutions in 50 years. Yup. Fire that second strawman into orbit. We’ve addressed Professor Thrun before and, after all, he was trying to excite and engage a community over something new and, to his credit, he’s been stepping back from that ever since.
Ah, a Coursera course that came from a “high-quality” US University. It is full of imprecise language, saying How and not Why, with a Monster generator approach. A quick ad hominen attack on the lecturer in the video (He looked like he had been on drugs for 10 years). Apparently, and with no evidence, Professor Fradkin can guarantee that no student picked up any idea of what a function was from this course.
Apparently some Universities are becoming more cautious about MOOCs. Really.
I’m sorry to have editorialised so badly during this session but this has been a very challenging talk to listen to as so much of the underlying material has been, to my understanding, misrepresented at least. A very disappointing talk over all and one that could have been so much better – I agree with a lot of the outcomes but I don’t really think that this is not the way to lead towards it.
Sadly, already someone has asked to translate the speaker’s slides into German so that they can send it to the government! Yes, text books are often bad and a lack of sequencing is a serious problem. Once again I agree with the conclusion but not the argument… Heresy is an important part of our development of thought, and stagnation is death, but I think that we always need to be cautious that we don’t sensationalise and seek strawmen in our desire to find new truths that we have to reach through heresy.
Education and Paying Back (#AdelEd #CSER #DigitalTechnologies #acara #SAEdu)
Posted: March 22, 2014 Filed under: Education, Opinion | Tags: ACARA, advocacy, collaboration, community, cser, cser digital technologies, curriculum, design, digital education, digital technologies, education, educational problem, educational research, Generation Why, Google, higher education, learning, MOOC, Primary school, primary school teacher, principles of design, reflection, resources, school teachers, secondary school, sharing, teaching approaches, thinking, tools 2 CommentsOn Monday, the Computer Science Education Research Group and Google (oh, like you need a link) will release their open on-line course to support F-6 Primary school teachers in teaching the new Digital Technologies curriculum. We are still taking registrations so please go the course website if you want to sign up – or just have a look! (I’ve blogged about this recently as part of Science meets Parliament but you can catch it again here.) The course is open, on-line and free, released under Creative Commons so that the only thing people can’t do is to try and charge for it. We’re very excited and it’s so close to happening, I can taste it!
Here’s that link again – please, sign up!
I’m posting today for a few reasons. If you are a primary school teacher who wants help teaching digital technologies, we’d love to see you sign up and join our community of hundreds of other people who are thinking the same thing. If you know a primary school teacher, or are a principal for a primary school, and think that this would interest people – please pass it on! We are most definitely not trying to teach teachers how to teach (apart from anything else, what presumption!) but we’re hoping that what we provide will make it easier for teachers to feel comfortable, confident and happy with the new DT curriculum requirements which will lead to better experiences all ’round.
My other reason is one that came to me as I was recording my introduction section for the on-line course. In that brief “Oh, what a surprise there’s a camera” segment, I note that I consider the role of my teachers to have been essential in getting me to where I am today. This is what I’d like to do today: explicitly name and thank a few of my teachers and hope that some of what we release on Monday goes towards paying back into the general educational community.

You know who this is for.
My first thanks go to Mrs Shand from my Infant School in England. I was an early reader and, in an open plan classroom, she managed to keep me up with the other material while dealing with the fact that I was a voracious reader who would disappear to read at the drop of a hat. She helped to amplify my passion for reading, instead of trying to control it. Thank you!
In Australia, I ran into three people who were crucial to my development. Adam West was interested in everything so Grade 5 was full of computers (my first computing experience) because he arranged to borrow one and put it into the classroom in 1978, German (I can still speak the German I learnt in that class) and he also allowed us to write with nib and ink pens if we wanted – which was the sneakiest way to get someone’s handwriting and tidiness to improve that I have ever seen. Thank you, Adam! Mrs Lothian, the school librarian, also supported my reading habit and, after a while, all of the interesting books in the library often came through me very early on because I always returned them quickly and in good condition but this is where I was exposed to a whole world of interesting works: Nicholas Fisk, Ursula Le Guin and Susan Cooper not being the least of these. Thank you! Gloria Patullo (I hope I’ve spelt that correctly) was my Grade 7 teacher and she quickly worked out that I was a sneaky bugger on occasion and, without ever getting angry or raising a hand, managed to get me to realise that being clever didn’t mean that you could get away with everything and that being considerate and honest were the most important elements to alloy with smart. Thank you! (I was a pain for many years, dear reader, so this was a long process with much intervention.)
Moving to secondary school, I had a series of good teachers, all of whom tried to take the raw stuff of me and turn it into something that was happier, more useful and able to take that undirected energy in a more positive direction. I have to mention Ken Watson, Glenn Mulvihill, Mrs Batten, Dr Murray Thompson, Peter Thomas, Dr Riceman, Dr Bob Holloway, Milton Haseloff (I still have fossa, -ae, [f], ditch, burned into my brain) and, of course, Geoffrey Bean, headmaster, strong advocate of the thinking approaches of Edward de Bono and firm believer in the importance of the strength one needs to defend those who are less strong. Thank you all for what you have done, because it’s far too much to list here without killing the reader: the support, the encouragement, the guidance, the freedom to try things while still keeping a close eye, the exposure to thinking and, on occasion, the simple act of sitting me down to get me to think about what the heck I was doing and where I was going. The fact that I now work with some of them, in their continuing work in secondary education, is a wonderful thing and a reminder that I cannot have been that terrible. (Let’s just assume that, shall we? Moving on – rapidly…)
Of course, it’s not just the primary and secondary school teachers who helped me but they are the ones I want to concentrate on today, because I believe that the freedom and opportunities we offer at University are wonderful but I realise that they are not yet available to everyone and it is only by valuing, supporting and developing primary and secondary school education and the teachers who work so hard to provide it that we can go further in the University sector. We are lucky enough to be a juncture where dedicated work towards the national curriculum (and ACARA must be mentioned for all the hard work that they have done) has married up with an Industry partner who wants us all to “get” computing (Thank you, Google, and thank you so much, Sally and Alan) at a time when our research group was able to be involved. I’m a small part of a very big group of people who care about what happens in our schools and, if you have children of that age, you’ve picked a great time to send them to school. 🙂
I am delighted to have even a small opportunity to offer something back into a community which has given me so much. I hope that what we have done is useful and I can’t wait for it to start.
ASWEC 2014 – Now with Education Track
Posted: March 12, 2014 Filed under: Education | Tags: advocacy, ASWEC, blogging, community, curriculum, education, educational problem, educational research, higher education, learning, measurement, principles of design, resources, software engineering, teaching, teaching approaches, thinking Leave a commentThe Australasian Software Engineering Conference has been around for 23 years and, while there have been previous efforts to add more focus on education, this year we’re very pleased to have a full day on Education on Wednesday, the 9th of April. (Full disclosure: I’m the Chair of the program committee for the Education track. This is self-advertising of a sort.) The speakers include a number of exciting software engineering education researchers and practitioners, including Dr Claudia Szabo, who recently won the SIGCSE Best Paper Award for a paper in software engineering and student projects.
Here’s the invitation from the conference chair, Professor Alan Fekete – please pass this on as far as you can!:
- Keynote by a leader of SE research, Prof Gail Murphy (UBC, Canada) on Getting to Flow in Software Development.
- Keynote by Alan Noble (Google) on Innovation at Google.
- Sessions on Testing, Software Ecosystems, Requirements, Architecture, Tools, etc, with speakers from around Australia and overseas, from universities and industry, that bring a wide range of perspectives on software development.
- An entire day (Wed April 9) focused on SE Education, including keynote by Jean-Michel Lemieux (Atlassian) on Teaching Gap: Where’s the Product Gene?
SIGCSE Day 3, “What We Say, What They Do”, Saturday, 9-10:15am, (#SIGCSE2014)
Posted: March 9, 2014 Filed under: Education | Tags: CS1, dashboarding, data visualisation, education, EiPE, higher education, neopiaget, programming, SIGCSE2014, SOLO, students, TDD, teaching, teaching approaches, test last, test-driven development, testing, WebCAT 3 CommentsThe first paper was “Metaphors we teach by” presented by Ben Shapiro from Tufts. What are the type of metaphors that CS1 instructors use and what are the wrinkles in these metaphors. What do we mean by metaphors? Ben’s talking about conceptual metaphors, linguistic devices to allow us to understand one idea in terms o another idea that we already know. Example: love is a journey – twists and turns, no guaranteed good ending, The structure of a metaphor is that you have a thing we’re trying to explain (the target) in terms of something we already know (the source). Conceptual metaphors are explanatory devices to assist us in understanding new things.
- What metaphors do CS1 instructors use for teaching?
- What are the trying to explain?
- What are the sources that they use?
- Levels taught and number of years
- Tell me about a metahpor
- Target to source mapping
- Common questions students have
- Where the metaphor breaks down
- How to handle the breakdown in teaching.
- Which metaphors work better?
- Cognitive clinical internviews, exploring how students think with metaphors and where incorrect inferences are drawn.
- Constant – even time a goal achieve, you got a hint (Consistently rewards target behaviour)
- Delayed – Hints when earned, at most one hint per hour (less inceptive for hammering the system)
- Random – 50% chance of hints when goal is met. (Should reduce dependency on extrinsic behaviours)
SIGCSE Day 2, “Software Engineering: Courses”, Thursday, 1:45-3:00pm, (#SIGCSE2014)
Posted: March 8, 2014 Filed under: Education | Tags: design, education, higher education, Java, Jose Benedetto, learning, open source, principles of design, Robert McCartney, SIGCSE2014, software engineering, students, teaching, teaching approaches Leave a commentRegrettably, despite best efforts, I was a bit late getting back from the lunch and I missed the opening session, so my apologies to Andres Neyem, Jose Benedetto and Andres Chacon, the authors of the first paper. From the discussion I heard, their course sounds interesting so I have to read their paper!
The next paper was “Selecting Open Source Software Projects to Teach Software Engineering” presented by Robert McCartney from University of Connecticut. The overview is why would we do this, the characteristics of the students, the projects and the course, finding good protects, what we found, how well it worked and what the conclusions were.
In terms of motivation, most of their SE course is in project work. The current project approach emphasises generative aspects. However, in most of SE, the effort involves maintenance and evolution. (Industry SE’s regularly tweak and tune, rather than build from the bottom.) The authors wanted to change focus to software maintenance and evolution, have the students working on an existing system, understanding it, adding enhancements, implementing, testing and documenting their changes. But if you’re going to do this, where do you get code from?
There are a lot of open source projects, available on0line, in a variety of domains and languages and at different stages of development. There should* be a project that fits every group. (*should not necessarily valid in this Universe.) The students are not actually being embedded in the open source community, the team is forking the code and not planning to reintegrate it. The students themselves are in 2nd and 3rd year, with courses in OO and DS in Java, some experience with UML diagrams and Eclipse.
For each team of students, they get to pick a project from a set, try to understand the code, propose enhancements, describe and document all o their plans, build their enhancements and present the results back. This happens over about 14 weeks. The language is Java and the code size has to be challenging but not impossible (so about 10K lines). The build time had to fit into a day or two of reasonable effort (which seems a little low to me – NF). Ideally, it should be a team-based project, where multiple developed could work in parallel. An initial look at the open source repositories on these criteria revealed a lot of issues: not many Java programs around 10K but Sourceforge showed promise. Interestingly, there were very few multi-developer projects around 10K lines. Choosing candidate projects located about 1000 candidates, where 200 actually met the initial size criterion. Having selected some, they added more criteria: had to be cool, recent, well documented, modular and have capacity to be built (no missing jar files, which turned out to be a big problem). Final number of projects: 19, size range 5.2-11 k lines.
That’s not a great figure. The takeaway? If you’re going to try and find projects for students, it’s going to take a while and the final yield is about 2%. Woo. The class ended up picking 16 projects and were able to comprehend the code (with staff help). Most of the enhancements, interestingly, involved GUIs. (Thats not so great, in my opinion, I’d always prefer to see functional additions first and shiny second.)
In concluding, Robert said that it’s possible to find OSS projects but it’s a lot of work. A search capability for OSS repositories would be really nice. Oh – now he’s talking about something else. Here it comes!
Small projects are not built and set up to the same standard as larger projects. They are harder to build, less-structured and lower quality documentation, most likely because it’s one person building it and they don’t notice the omissions. Thes second observation is that running more projects is harder for the staff. The lab supervisor ends up getting hammered. The response in later offerings was to offer fewer but larger projects (better design and well documented) and the lab supervisor can get away with learning fewer projects. On the next offering, they increased the project size (40-100K lines), gave the students the build information that was required (it’s frustrating without being amazingly educational). Overall, even with the same projects, teams produced different enhancements but with a lot less stress on the lab instructor.
Rather unfortunately, I had to duck out so I didn’t see Claudia’s final talk! I’ll write it up as a separate post later. (Claudia, you should probably re-present it at home. 🙂 )
SIGCSE Keynote #1 – Computational Thinking For All, Robert M. Panoff, Shodor Education Foundation
Posted: March 7, 2014 Filed under: Education | Tags: bob panoff, education, higher education, keynote, learning, robert panoff, sigcse, SIGCSE2014, teaching, teaching approaches, thinking 2 CommentsBob Panoff is the wonder of the 2014 SIGCSE Award for Outstanding Contribution to Computer Science Education and so he gets to give a keynote, which is a really good way to do it rather than delaying the award winners to the next year.
Bob kicked off with good humour, most of which I won’t be able to capture, but the subtext of hits talk is “The Power and the Peril”, which is a good start to the tricky problem of Comp thinking for all. What do we mean by computational thinking? Well, it’s not teaching programming, we can teach programming to enhance computational thinking but thinking is the key word here. (You can find his slides here: http://shodor.org/talks/cta/)
Bob has faced the same problem we all have: that of being able to work on education when your institution’s focus is research. So he went to start an independent foundation where CS Ed where such activities could be supported. Bob then started talking about expectation management, noting that satisfaction is reality divided by expectations – so if you lower your expectations. (I like that and will steal it.)
Where did the name Shodor come from? Bob asked us if we knew and then moved to put us through a story, which would answer this question. As it turns out, he name came from a student’s ungenerous pattern characterisation of Bob, whose name he couldn’t remember, as “short and kinda dorky looking”.
I need to go and look at the Shodor program in detail because they have a lawyered apprenticeship model, teaching useful thinking and applied skills, to high schoolers, which fills in the missing math and 21st century skills that might prevent them from going further in education. Many of the Shodor apprentices end up going on as first-in-family to college, which is a great achievement.
Now, when we say Computational Science Education, is it Computational (Science Education) or (Computational Science) Education? (This is the second slide in the pack). The latter talks about solving the right problem, getting the problem solved in the right way and actually being right.
Right Answer = Wrong Answer + Corrections
This is one of the key issues in modelling over finite resources, because we have to take shortcuts in most systems to produce a model that will fit. Computationally, if we have a slightly wrong answer (because of digital approximations or so on), then many iterations will make it more and more wrong. If we remember to adjust for the corrections, we can still be right. How helpful is it to have an exact integral that you can’t evaluate, especially when approximations make that exact integral exceedingly unreliable? (The size of the Universe is not 17cm, for example.)
Elegant view of science: Expectation, Observation and Reflection. What do you expect to see? What do you see? What does it actually mean Programming is a useful thought amplifier because we can get a computer to do something BUT before you get to the computer, what do you expect the code to work and how will you now what it’s doing? Verification and validation are important job skills, along with testing, QA and being able to read design documents. Why? Because then you have to be able to Expect, Observe and Reflect. Keyboard skills do not teach you any of this and some programming ‘tests’ are more keyboard skills than anything else.
(If you ever have a chance to see Bob talk, get there. He’s a great speaker and very clever and funny at the same time.)

Oh dear.
Can we reformable the scientific method and change the way that we explain science to people? What CAN I observe? What DO I observe? How do I know that it’s right? How am I sure? Why should I care? A lot of early work was driven by wonder (Hey, that’s cool) rather than hypothesis driven (which is generally what we’re supposed to be doing.) (As a very bad grounded theorist, this appeals.)
How do we produce and evaluate models? Well, we can have an exact solution to an exact model, an exact solution to an approximate model (not real but assessable), an approximate solution to an exact model and an approximate solution to an approximate model. Some of the approximation in the model is the computing itself, with human frailty thrown into the mix.
What does Computational Thinking allow you to? To build and explore a new world where new things are true and other things are false, because this new universe is interesting to us. “The purpose of computing is insight, not numbers” — R. Hamming, “If you can’t trust the numbers, you won’t get much insight” — R. Panoff. Because the computer is dumb, we have to do more work and more thinking to make up for the fast and accurate moron that does what we order it to do.
“Killing off the big lie” – every Math class you have, you see something on page 17 showing a graph and an equation which has “as you can see from the graph” starting it. Bob’s lament is that he CAN’T see from the graph and not many other people can either. We just say that but, many times, it’s a big lie. Pattern recognition and characterisation are more important than purely manipulating numbers. (All of this is on the Shodor website) Make something dynamic and interactive and student can explore, which allows them to think about what happens when they change things – set an expectation, observe and reflect, change conditions and do it again.
Going to teachers, they know that teaching mathematics is frequently teaching information repetitively with false rules so that simple assessment can be carried out. (Every histogram must have 10 bars and so many around the mean, etc) Using computing to host these sorts of problems allows us to change the world and then see what happens. Rather than worry about how long it takes students to produce one histogram on paper, they can make one in an on-line environment and play with it. There are better and worse ways to represent data so let’s use computational resources to allow everyone to do this, even when they’re learning. This all comes down to different models as well as different representations. (There is value to making kids work up a histogram by hand but there are many ways to do this and we can change the question and the support and remove the tedium of having to use paper and pen to do one, when we could use computing to do the dull stuff.)
Bob emphasised the importance of drawing pictures and telling stories, they hand-waving that communicates site complicated concepts to people. “What’s this?” “I don’t know but here comes a whole herd of them!”
The four things we need for computational thinking are: Quantitative Reasoning, Algorithm Thinking, Analogic Thinking, and Multi-scale Modelling. Bob showed an interesting example of calculating a known result when you don’t know the elements by calculating the relative masses of the Earth and Pluto using Google and just typing “mass of the earth / mass of pluto” Is this right? What is our reason for believing it? You would EXPECT things to be well-know but what do you OBSERVE? Hmm, time to REFLECT. (As the example, the earth mass value varies dramatically between sources – Google tells you where it gets the information but a little digging reveals that things don’t align AND the values may change over time. The answer varies depends upon the model you use and how you measure it. All of the small differences add up.)
The next example is the boiling point of Radium, given as 1,140C by Google, but the matching source doesn’t even agree with this! If you can’t trust the numbers then this is yet another source of uncertainty and error in our equations.
Even “=” has different interpretations – F = ma is the statement that force occurs as mass accelerates. In nRT = PV, we are saying that energy is conserved in these reactions. dR/dT = bR – the number of rabbits having bunnies will affect the rate of change of rabbits. No wonder students have trouble with what “s=3” means, on occasion. Speaking of meaning, Bob played this as an audio clip, but I attach the text here:
The missile knows where it is at all times. It knows this because it knows where it isn’t. By subtracting where it is from where it isn’t, or where it isn’t from where it is (whichever is greater), it obtains a difference, or deviation. The guidance subsystem uses deviations to generate corrective commands to drive the missile from a position where it is to a position where it isn’t, and arriving at a position where it wasn’t, it now is. Consequently, the position where it is, is now the position that it wasn’t, and it follows that the position that it was, is now the position that it isn’t.
In the event that the position that it is in is not the position that it wasn’t, the system has acquired a variation, the variation being the difference between where the missile is, and where it wasn’t. If variation is considered to be a significant factor, it too may be corrected by the GEA. However, the missile must also know where it was.
The missile guidance computer scenario works as follows. Because a variation has modified some of the information the missile has obtained, it is not sure just where it is. However, it is sure where it isn’t, within reason, and it knows where it was. It now subtracts where it should be from where it wasn’t, or vice-versa, and by differentiating this from the algebraic sum of where it shouldn’t be, and where it was, it is able to obtain the deviation and its variation, which is called error.
Try reading that out loud! Bob then went on to show us some more models to see how we can experiment with factors (parameters) in a dynamic visualisations in a way that allows us to problem solve. So schoolkids can reduce differential equations to simple statements relating change and then experiment – without having to know HOW to solve differential equations (what you have now is what you had then, modified by change). This is model building without starting with programming, it’s starting with modelling, showing what they can do and then exposing how this approach can be limited – which provides a motivation to learn how to program so you can fix the problems in this model.
Overall, an excellent talk about an interesting project attacking the core issue of getting students to think in the right way, instead of just getting them to conform to some dry mechanistic programming approaches. The National Computer Science Institute is doing work across the US (if they come and do a workshop, you have to give them a mug and they have a lot of mugs). NCSI are looking for summer workshop hosts so, if you’re interested, you should contact them (not me!) Here’s one of the quotes from the end:
“It was once conjectured that a million monkeys typing on a million typewriters could eventually produce all of the works of Shakespeare. Now, thanks to the Internet, we know that this is not true” (Bob Willinsky (possible attribution, spelling may be wrong))
What would happen if the Internet went away? That’s a big question and, sadly, Bob started to run out of time. Our world runs in parallel so we need to have be able to think in parallel as well. Distributed computation requires us to think in different ways and that gets hard, quickly.
Bob wrapped it up by saying that Shodor was a village, a lot of fun and was built upon a lot of funding. Great talk!
