
EduTech AU 2015, Day 2, Higher Ed Leaders, “Assessment: The Silent Killer of Learning”, #edutechau @eric_mazur
Posted: June 3, 2015 Filed under: Education | Tags: assessment, educational problem, educational research, edutech2015, edutechau, eric mazur, feedback, harvard, higher education, in the student's head, learning, peer instruction, plagiarism, student perspective, students, teaching, teaching approaches, thinking, time banking, tools, universal principles of design, workload 3 CommentsNo surprise that I’m very excited about this talk as well. Eric is a world renowned educator and physicist, having developed Peer Instruction in 1990 for his classes at Harvard as a way to deal with students not developing a working physicist’s approach to the content of his course. I should note that Eric also gave this talk yesterday and the inimitable Steve Wheeler blogged that one, so you should read Steve as well. But after me. (Sorry, Steve.)
I’m not an enormous fan of most of the assessment we use as most grades are meaningless, assessment becomes part of a carrot-and-stick approach and it’s all based on artificial timelines that stifle creativity. (But apart from that, it’s fine. Ho ho.) My pithy statement on this is that if you build an adversarial educational system, you’ll get adversaries, but if you bother to build a learning environment, you’ll get learning. One of the natural outcomes of an adversarial system is activities like cheating and gaming the system, because people start to treat beating the system as the goal itself, which is highly undesirable. You can read a lot more about my views on plagiarism here, if you like. (Warning: that post links to several others and is a bit of a wormhole.)
Now, let’s hear what Eric has to say on this! (My comments from this point on will attempt to contain themselves in parentheses. You can find the slides for his talk – all 62MB of them – from this link on his website. ) It’s important to remember that one of the reasons that Eric’s work is so interesting is that he is looking for evidence-based approaches to education.
Eric discussed the use of flashcards. A week after Flashcard study, students retain 35%. After two weeks, it’s almost gone. He tried to communicate this to someone who was launching a cloud-based flashcard app. Her response was “we only guarantee they’ll pass the test”.
*low, despairing chuckle from the audience*
Of course most students study to pass the test, not to learn, and they are not the same thing. For years, Eric has been bashing the lecture (yes, he noted the irony) but now he wants to focus on changing assessment and getting it away from rote learning and regurgitation. The assessment practices we use now are not 21st century focused, they are used for ranking and classifying but, even then, doing it badly.
So why are we assessing? What are the problems that are rampant in our assessment procedure? What are the improvements we can make?
How many different purposes of assessment can you think of? Eric gave us 90s to come up with a list. Katrina and I came up with about 10, most of which were serious, but it was an interesting question to reflect upon. (Eric snuck
- Rate and rank students
- Rate professor and course
- Motivate students to keep up with work
- Provide feedback on learning to students
- Provide feedback to instructor
- Provide instructional accountability
- Improve the teaching and learning.
Ah, but look at the verbs – they are multi-purpose and in conflict. How can one thing do so much?
So what are the problems? Many tests are fundamentally inauthentic – regurgitation in useless and inappropriate ways. Many problem-solving approaches are inauthentic as well (a big problem for computing, we keep writing “Hello, World”). What does a real problem look like? It’s an interruption in our pathway to our desired outcome – it’s not the outcome that’s important, it’s the pathway and the solution to reach it that are important. Typical student problem? Open the book to chapter X to apply known procedure Y to determine an unknown answer.
Shout out to Bloom’s! Here’s Eric’s slide to remind you.
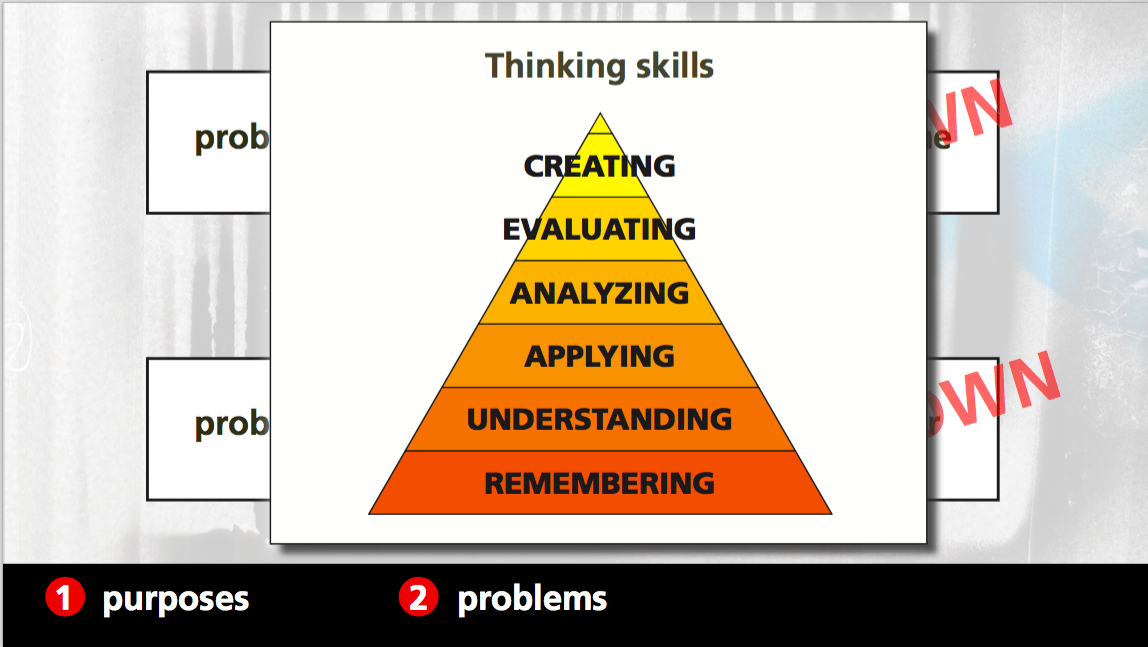
Rights reside with Eric Mazur.
Eric doesn’t think that many of us, including Harvard, even reach the Applying stage. He referred to a colleague in physics who used baseball problems throughout the course in assignments, until he reached the final exam where he ran out of baseball problems and used football problems. “Professor! We’ve never done football problems!” Eric noted that, while the audience were laughing, we should really be crying. If we can’t apply what we’ve learned then we haven’t actually learned i.
Eric sneakily put more audience participation into the talk with an open ended question that appeared to not have enough information to come up with a solution, as it required assumptions and modelling. From a Bloom’s perspective, this is right up the top.
Students loathe assumptions? Why? Mostly because we’ll give them bad marks if they get it wrong. But isn’t the ability to make assumptions a really important skill? Isn’t this fundamental to success?
Eric demonstrated how to tame the problem by adding in more constraints but this came at the cost of the creating stage of Bloom’s and then the evaluating and analysing. (Check out his slides, pages 31 to 40, for details of this.) If you add in the memorisation of the equation, we have taken all of the guts out of the problem, dropping down to the lowest level of Bloom’s.
But, of course, computers can do most of the hard work for that is mechanistic. Problems at the bottom layer of Bloom’s are going to be solved by machines – this is not something we should train 21st Century students for.
But… real problem solving is erratic. Riddled with fuzziness. Failure prone. Not guaranteed to succeed. Most definitely not guaranteed to be optimal. The road to success is littered with failures.
But, if you make mistakes, you lose marks. But if you’re not making mistakes, you’re very unlikely to be creative and innovative and this is the problem with our assessment practices.
Eric showed us a stress of a traditional exam room: stressful, isolated, deprived of calculators and devices. Eric’s joke was that we are going to have to take exams naked to ensure we’re not wearing smart devices. We are in a time and place where we can look up whatever we want, whenever we want. But it’s how you use that information that makes a difference. Why are we testing and assessing students under such a set of conditions? Why do we imagine that the result we get here is going to be any indicator at all of the likely future success of the student with that knowledge?
Cramming for exams? Great, we store the information in short-term memory. A few days later, it’s all gone.
Assessment produces a conflict, which Eric noticed when he started teaching a team and project based course. He was coaching for most of the course, switching to a judging role for the monthly fair. He found it difficult to judge them because he had a coach/judge conflict. Why do we combine it in education when it would be unfair or unpleasant in every other area of human endeavour? We hide between the veil of objectivity and fairness. It’s not a matter of feelings.
But… we go back to Bloom’s. The only thinking skill that can be evaluated truly objectively is remembering, at the bottom again.
But let’s talk about grade inflation and cheating. Why do people cheat at education when they don’t generally cheat at learning? But educational systems often conspire to rob us of our ownership and love of learning. Our systems set up situations where students cheat in order to succeed.
- Mimic real life in assessment practices!
Open-book exams. Information sticks when you need it and use it a lot. So use it. Produce problems that need it. Eric’s thought is you can bring anything you want except for another living person. But what about assessment on laptops? Oh no, Google access! But is that actually a problem? Any question to which the answer can be Googled is not an authentic question to determine learning!
Eric showed a video of excited students doing a statistic tests as a team-based learning activity. After an initial pass at the test, the individual response is collected (for up to 50% of the grade), and then students work as a group to confirm the questions against an IF AT scratchy card for the rest of the marks. Discussion, conversation, and the students do their own grading for you. They’ve also had the “A-ha!” moment. Assessment becomes a learning opportunity.
Eric’s not a fan of multiple choice so his Learning Catalytics software allows similar comparison of group answers without having to use multiple choice. Again, the team based activities are social, interactive and must less stressful.
- Focus on feedback, not ranking.
Objective ranking is a myth. The amount of, and success with, advanced education is no indicator of overall success in many regards. So why do we rank? Eric showed some graphs of his students (in earlier courses) plotting final grades in physics against the conceptual understanding of force. Some people still got top grades without understanding force as it was redefined by Newton. (For those who don’t know, Aristotle was wrong on this one.) Worse still is the student who mastered the concept of force and got a C, when a student who didn’t master force got an A. Objectivity? Injustice?
- Focus on skills, not content
Eric referred to Wiggins and McTighe, “Understanding by Design.” Traditional approach is course content drives assessment design. Wiggins advocates identifying what the outcomes are, formulate these as action verbs, ‘doing’ x rather than ‘understanding’ x. You use this to identify what you think the acceptable evidence is for these outcomes and then you develop the instructional approach. This is totally outcomes based.
- resolve coach/judge conflict
In his project-based course, Eric brought in external evaluators, leaving his coach role unsullied. This also validates Eric’s approach in the eyes of his colleagues. Peer- and self-evaluation are also crucial here. Reflective time to work out how you are going is easier if you can see other people’s work (even anonymously). Calibrated peer review, cpr.molsci.ucla.edu, is another approach but Eric ran out of time on this one.
If we don’t rethink assessment, the result of our assessment procedures will never actually provide vital information to the learner or us as to who might or might not be successful.
I really enjoyed this talk. I agree with just about all of this. It’s always good when an ‘internationally respected educator’ says it as then I can quote him and get traction in change-driving arguments back home. Thanks for a great talk!
ITiCSE 2014, Day 3, Session 7B, Peer Instruction, #ITiCSE2014 #ITiCSE
Posted: June 25, 2014 Filed under: Education | Tags: community, computer science education, curriculum, design, education, educational problem, educational research, flipped classroom, higher education, in the student's head, inverted classroom, ITiCSE, ITiCSE 2014, learning, peer instruction, teaching, teaching approaches, thinking Leave a commentThe first talk was “Peer Instruction: a Link to the Exam” presented by Daniel Zingaro from University of Toronto. Peer Instruction (PI) is an active learning pedagogy developed for physics and now heavily used in computing. Students complete a reading quiz prior to class and teachers use multiple-choice quizzes to assess knowledge. (You can look this one up in a number of places but I’ve discussed it here before a bit.) There’s a lot of research that shows gains between individual and group vote, with enduring improvements in student learning. (We can use isomorphic questions to reduce the likelihood of copying.) Both students and instructors value the learning.
PI appears to demonstrate improved learning outcomes on the final exam grades, as well as perceived depth of learning. (Couple of studies here from Beth Simon et al, and Daniel himself, checking Beth’s results.) But what leads to this improved outcome? The peer discussion. The class wide discussion? Both? If one part isn’t useful then we can adapt it to make it more useful to Computer Scientists. Daniel is going to use isomorphic questions to investigate relationships between PI components and final exam grades.
The isomorphic questions test the same concept with different questions, where if they get the first one right, we hope that they get the second one right – and if people learn how to do one, then that knowledge flows on to the other. (The example given was of loop complexity in nested loops depending on different variables.)
Daniel has two question modes in this experiment, which are slightly different. Both modes include the PI components, but the location of the isomorphic questions vary between the two approaches in the second question. In the Peer ℗ mode, the isomorphic question comes directly after the group vote and the second mode (Combined – C), the Q2 isomorphic questions occur direct after the instructor has had a chance to influence the class.
Are the questions really isomorphic and of the same difficulty? An external ranker was used to verity this and then the question pairs and mode were randomised. The difficulty of the questions was found to be statistically equivalent, based on the percentage of Q1 that were found to be correct.
Daniel had two hypotheses. Firstly, that peer scores will correlate to final exam scores. Secondly, that combined scores will also correlate with final exam scores, but the correlation should be stronger than for Peer, with the Combined questions representing learning from the full PI cycle. In terms of the final exam, there were three measures of the final exam grades: total exam score, score on the tracing question (similar to PI questions) and score on a code-writing question (very different to PI questions).
The implementation was a CS1 course with 3 lectures/week, with reading quizzes worthy 4% submitted prior to each lecture, clicker responses worth 5%, where the lectures on average contained three PI cycles- one cycle per lecture contained the follow-up isomorphic question. Multiple regression was used to test relationships between PI and final exam scores.
All of the results were statistically significant. For code-tracing, hat students know before exam explains 13% of their scores in the final exam. With the peer questions, it goes up to 16%. With combined as well, it goes up to 19%. Is this practically significant? Daniel raised this question because it doesn’t rise very much.
In terms of code writing, Baseline is 16%, + Peers is 22% and +Combined is 25%, so we’re starting to see more contribution from peers than instructor in this case. Are we measuring the different difficulty of a problem that peers couldn’t correct, which is why the instructor does less?
Overall? Baseline 21%, Peer 30% and then Combined is 34%. (Any questions about the stats, please read the paper. 🙂 )
Maybe adding combined questions to peer questions increases our predictive accuracy, just because we’re adding more data and this being able to produce a better model?
In discussion, PI performance related to final exam scores (as expected). Peer learning alone is important and the instructor-led discussion is important, over and above peer learning. This validates the role of the instructor in a “student-centred” classroom. Given that PI uses MCQs, we might expect it to only correlate with code-tracing but it does appear to correlate with code-writing problems as well – there may be deep conceptual similarities between PI questions and programming skills. But would the students that learned from PI also the students that would have learned from any other form of instruction? Still an open question and there’s a lot of ongoing work still to do.
The next paper was “Comparing Outcomes in Inverted and Traditional CS1” presented by Diane Horton from U Toronto. I’ve been discussing early intervention and student attendance issues in inverted/hybrid courses with Jennifer Campbell and Michelle Craig, also from U Toronto and also on this paper, as part of an attempt to get some good answers so I’d just come straight out of a lunch, discussing inverted classrooms and their outcomes. (Again, this is why we come to conferences – much of the value is in the meetings and discussion that are just so hard to have when you’re doing your day job or fitting a Skype meeting into the wee small hours to bridge the continental time gap.)
As a reminder, in inverted teaching, some or all of the material is delivered outside the classroom. Work typically done as homework is done in the lecture with the help of instructor or TAs. There were three research questions. Would the inverted offerings have better outcomes? Would inverted teaching affect students’ behaviour or experience? Would particular subgroups respond differently, especially English-language learners and beginner programmers?
The CS1 course at Toronto is a 12 week course in Python, objects-early, classes-late, with most students in 1st year and less than half looking to major in CS. The lectures are roughly 200 students, with 5 of these lecture sections.
Before the lecture, students prepared by watching videos, from the instructors, mostly screencasts of live programming with voice over, credit for attempting quizzes embedded in videos is 0.5% per week. (It’s scary how small that fraction has to be and really rather sad, from a behavioural perspective.)
During the lecture, the instructors used a worked example and students worked on worksheet-based exercises for most of the lectures, with assistance, solo or in pairs. This was a responsive teaching approach because the instructor could draw the class together as required. There was no mark reward or penalty that depended on attendance. If you were solid on the material, it was okay to miss the lecture. The mark scheme reflected some marks for lecture preparation with an increased number of online exercises and decreased weighting on labs.
The inverted CS1 course had gone well in the pilot in January 2013, which was published in a peer at SIGCSE ’14, but it was hard to compare this with the previous class as the make-up of the cohort varies from September to January courses. The study was run again in a more similar cohort in September 2014. The data presented here is for a similar cohort with a high overlap of instructors, compared the traditional offering.
For the present study, there were pre- and post-course surveys about attitude and behaviour, competed on-paper in the lecture. Weekly lecture attendance counts were made and standard university course valuations collected. In terms of attendance, the inverted pilot was the lowest, but the inverted class had lower attendance most of the time – an effect that we have also seen under some circumstances and are still thinking about. Interestingly, students thought that the inverted lectures weren’t seen as being as useful as face-to-face lectures but the online support materials were seen to be very helpful. As a package, this seems to be an overall positive experience.
The hypothesis was that students in the inverted offering would self-report a higher quality of learning experience and greater enjoyment but this wasn’t supported in the data, nor was it for beginners in particular. However, when asked if they wanted more inverted courses, there was a very strong positive response to this question.
The authors expected that beginners would benefit more because they need more helps and the gap between beginners and experiences students would reduce – this wasn’t supported by the data. Also, there was no reduction of gaps for English language learners, either.
Would the inverted course help people stay on and pass the course? Well, however success was defined, the pass rate was remarkably consistent, even when the beginners were isolated. However, it does appear that the overall level of knowledge, as measured by the final exam grades, actually improved in the inverted offerings, across two exams of similar difficult, with a jump from an average grade of 66% to 74% between the terms. Is this just due to the inverted teaching?
Maybe students learned more in the inverted offering because they spent more time on task? Based on self-reported student time, this doesn’t appear to be true. Maybe the beginners got killed off early to reduce their numbers and raise the mark? No, the drop rates among beginners were the same. It appears that the 8 percentage point increase may be related to the inverted mode, although, obviously, more work is required.
Is it worth it? They used no additional TA resources but the development time was enormous. You may not be ready for this investment. There are other options, you don’t need to use videos and you can use pre-existing materials to reduce costs.
Future work involves looking at dropping patterns – who drops when – and student who stumble and recover. They’re also looking at a full online CS1 course for course credit.
The final talk was on “Making Group Processes Explicit to Students: A Case for Justice” presented by Ville Isomöttönen. Project courses have a very long history in Computer Science, as capstones, using authentic customer projects, and the intention is to provide a realistic experience. (Editor’s note: It’s worth noting that some of this may be coming from the “We got punished like this so you can be too.”) What do students actually learn from this? Are they learning what we want them to learn or they are learning something very different and, potentially, much darker?
(This sounds like the kind of philosophical paper I’d give, let’s see where it goes! 🙂 )
If we have tertiary students, why can’t we just place them into a workplace for work experience? They’re adults – maybe we can separate this aspect and the pedagogue. The author’s study wants to look at how to promote conceptual learning in the response of realistic course work. Parker (1999) proposes that students are spending their effort of building wiring products, rather than actually learning about and reflecting upon the professional issues we consider important. The conjecture is that just because the situation is realistic doesn’t mean that the conceptual learning is happening as we intended.
The study is based around a fairly straight forward project-based learning structure, but had a Pass/Fail grade, with no distinction grading as far as I could tell. The teaching was baed on weekly group discussions, with self/peer evaluations, also housed in a group situation, and technical supervision offered by teaching assistant. Throughout the course, students are prompted to think about their operation at a conceptual level. Hmm. I’m not sure what the speaker means by this as, without a very detailed description of what is going on, this could have many different implementations.
We then cut to a diagram of justice conceptualised – I may have missed something as I’m not quite sure how this sits with the group work. I can’t find the diagram online but it involves participation, involving and negotiating with others – fused together as the skill of justice. This sits above statuses, norms and roles. Some of the related work deals with fairness (Richards 2009) as a key attribute of successful group work, Clear 2002 uses it in diagnostic technique, and Pieterse and Thompson 2010 mentioned ‘social loafers’ and ‘diligent isolates’.
I’m dreadfully sorry, dear reader, but I’m not following this properly so this may be a bit sketchy. Go and read the paper and I’ll try to get this together. Everyone else in the room appears to be getting this so I may just be tired or struggling with my (not very good) hearing and someone who is speaking rather quietly.
The underlying pedagogy comes from the social realist mindset (Moore,2000, Maton and Moore, 2010) and “avoids the dilemma between constructivist relativism and positivist absolutism”. We should also look at the Integrative Pedagogy (Tynjana (sp)), where the speaker feels that what they are describing is a realist version of this.
The course was surveyed with a preliminary small study (N=21/26, which is curious. Which one is it? Ah, 21 out of 26 enrolled, there we go.). The survey questions were… rather loose and very open to influence, unfortunately, from my quick glance at them but I will have to read the original paper.
Justice is a difficult topic to address, especially where it’s reified as a professional skill that can be developed, and discussing the notion of justice in terms of the ways that a group can work together fairly is very important. I suppose I’m not 100% convinced how much is added in this context through the use of a new term that is an apparent parent to communication and negotiation, with the desired outcome of fairness, because the amalgamation seems to obscure the individual components that would be improved upon to return to a fair state. The very small study, and a small survey, is a valid approach for a case study or phenomenographic approach, but I get the feeling that I was seeing a grounded theory argument. We do have to expose our desired processes to students if we’re going to achieve cognitive apprenticeship and there is a great deal of tension between industrial practice and key concepts, so this is a very interesting area to work in. I completely agree with the speaker that our heavy technical focus often precludes discussions of the empathic, philosophical and intangible, but I’m yet to see how this approach contributes.
The discussions mentioned as important are very important but group reports and discussion are a built-in part of many SE process models so I wonder how the justice theme amplifies this aspects. Again, getting students to engage in a dialogue that they do not expect to have in CS can be very challenging but we could be discussing issues such as critical thinking and ethics, which are often equally alien and orthogonal to the technical, without forming a compound concept that potentially obscures the underlying component mechanisms.
Simon asked a very good question: you didn’t present anything that showed a problem where the students would have needed the concept of justice. Apparently, this is in the writings that are yet to be analysed. The answer to the question ended up as an unlabelled graph on the blackboard which was focused on a skill difference with more experienced peers. I still can’t see how justice ties into this. I have to go and get my hearing checked.
ITiCSE 2014: Monday, Keynote 1, “New Technology, New Learning?” #ITiCSE2014 #ITiCSE
Posted: June 23, 2014 Filed under: Education | Tags: active learning, ambient wood, authenticity, co-creation, collaborative learning, community, computer science education, context, curriculum, education, educational problem, educational research, gamification, higher education, in the student's head, ITiCSE, ITiCSE 2014, learning, MOOC, panopticon, passive learning, peer instruction, peerwise, social media, students, teaching, teaching approaches, thinking Leave a commentThis keynote was presented by Professor Yvonne Rogers, from University College of London. The talk was discussing how we could make learning more accessible and exciting for everyone and encourage students to think, to create and share our view. Professor Rogers started by sharing a tweet by Conor Gearty on a guerrilla lecture, with tickets to be issued at 6:45pm, for LSE students. (You can read about what happened here.) They went to the crypt of Westminster Cathedral and the group, split into three smaller groups, ended up discussing the nature of Hell and what it entailed. This was a discussion on religion but, because of the way that it was put together, it was more successful than a standard approach – context shift, suspense driving excitement and engagement. (I wonder how much suspense I could get with a guerrilla lecture on polymorphism… )
Professor Rogers says that suspense matters, as the students will be wondering what is coming next, and this will hopefully make them more inquisitive and thus drive them along the path to scientific enquiry. The Ambient Wood was a woodland full of various technologies for student pairs, with technology and probes, an explorative activity. You can read about the Ambient Wood here. The periscope idea ties videos into the direction that you are looking – a bit like Google Glass without a surveillance society aspect (a Woodopticon?). (We worked on similar ideas at Adelaide for an early project in the Arts Precinct to allow student exploration to drive the experience in arts, culture and botanical science areas.) All of the probes were recorded in the virtual spatial environment matching the wood so that, after the activity, the students could then look at what they did. Thus, a group of 10-12 year olds had an amazing day exploring and discovering, but in a way that was strongly personalised, with an ability to see it from the bird’s eye view above them.
And, unsurprisingly, we moved on to MOOCs, with an excellent slide on MOOC HYSTERIA. Can we make these as engaging as the guerrilla lecture or the ambient wood?

MOOCs, as we know, are supposed to increase our reach and access to education but, as Professor Rogers noted, it is also a technology that can make the lecturer a “bit of a star”. This is one of the most honest assessments of some of the cachet that I’ve heard – bravo, Professor Rogers. What’s involved in a MOOC? Well, watching things, doing quizzes, and there’s probability a lot of passive, rather than active, learning. Over 60% of the people who sign up to do a MOOC, from the Stanford experience, have a degree – doing Stanford for free is a draw for the already-degreed. How can we make MOOCs fulfil their promise, give us good learning, give us active learning and so on? Learning analytics give us some ideas and we can data mine to try and personalise the course to the student. But this has shifted what our learning experience is and do we have any research to show the learning value of MOOCs?
In 2014, 400 students taking a Harvard course:
- Learned in a passive way
- Just want to complete
- Take the easy option
- Were unable to apply what they learned
- Don’t reflect on or talk to their colleagues about it.
Which is not what we want? What about the Flipped Classroom? Professor Rogers attributed this to Khan but I’m not sure I agree with this as there were people, Mazur for example, who were doing this in Peer Instruction well before Khan – or at least I thought so. Corrections in the questions please! The idea of the flip is that we don’t have content delivery in lectures with the odd question – we have content beforehand and questions in class. What is the reality?
- Still based on chalk and talk.
- Is it simply a better version of a bad thing?
- Are students more motivated and more active?
- Very labour-intensive for the teacher.
So where’s the evidence? Well, it does increase interaction in class between instructors and students. It does allow for earlier identification of misconceptions. Pierce and Fox, 2012, found that it increased exam results for pharmacology students. It also fostered critical thinking in case scenarios. Maybe this will work for 10s-100s – what about classes of thousands? Can we flip to this? (Should we even have classes of this size is another good question)
Then there’s PeerWise, Paul Denny (NZ), where there is active learning in which students create questions, answer them and get feedback. Students create the questions and then they get to try other student’s questions and can then rate the question and rate the answer. (We see approaches like this, although not as advanced, in other technologies such as Piazza.)
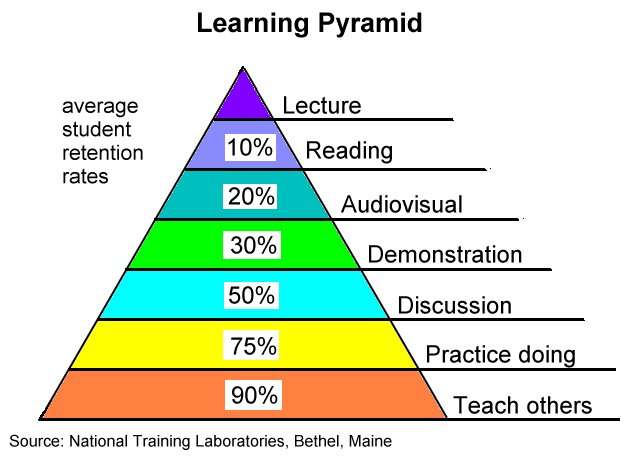
How effective is this? Performance in PeerWise correlated with exam marks (Anyadi, Green and Tang, 2013), with active student engagement. It’s used for revision before the exams, and you get hihg-quality questions and answers, while supporting peer interaction. Professor Rogers then showed the Learning Pyramid, from the National Training Laboratories, Bethel, Maine. The PeerWise system plays into the very high retention area.
Professor Rogers then moved on to her own work, showing us a picture of the serried rank nightmare of a computer-based classroom: students in rows, isolated and focused on their screens. Instead of ‘designing for one’, why don’t we design to orchestrate shared activities, with devices that link to public displays and can actively foster collaboration. One of Professor Rogers’ students is looking at ways to share simulations across tablets and screens. This included “4Decades“, a a simulation of climate management, with groups representing the different stakeholders to loo at global climate economics. We then saw a video that I won’t transcribe. The idea is that group work encourages discussion, however we facilitate it, and this tends to leading to teaching others in the sharing of ideas. Another technology that Professor Rogers’ group have developed in this space is UniPad: orchestrating collaborate activities across multiple types of devices, with one device per 6-7 students, and used in classes without many researchers present. Applications of this technology include budgeting for students (MyBank), with groups interacting and seeing the results on a public display. Given how many students operate in share houses collaboratively, this is quite an interesting approach to the problem. From studies on this, all group members participated and used the tablet as a token for discussion, taking ownership of a part of the problem. This also extended to reflection on other’s activities, including identifying selfish behaviour on the part of other people. (Everyone who has had flatmates is probably groaning at the moment. Curse you, Love Tarot Pay-By-The-Minute Telephone Number, which cost me and my flatmates a lot of dollars after a flatmate skipped out on us.)
The next aspect Professor Rogers discussed was physical creation toolkits, such as MaKey MaKey, where you can build alternative input for a computer, based on a simple printed circuit board with alligator clips and USB cables. The idea is simple: you can turn anything you like into a keyboard key. Demonstrations included a banana space bar, a play dough MarioKart gamepad, and many other things (a water bowl in front of the machine became a cat-triggered photo booth). This highlights one of the most important aspects of thinking about learning: learning for life. How can we keep people interested in learning in the face of busy, often overfull, lives when many people still think about learning as something that had to be endured on their pathway into the workforce? (Paging my climbing friends with their own climbing wall: you could make the wall play music if you wanted to. Just saying.)
One of the computers stopped working during a trial of the MaKey MaKey system with adult learners and the collaboration that ensued changed the direction of the work and more people were assigned to a single kit. Professor Rogers showed a small video of a four-person fruit orchestra of older people playing Twinkle Twinkle Little Star. (MORE KIWI!) This elicited a lot of ideas, including for their grandchildren and own parent, transforming exercise to be more fun, to help people learn fundamental knowledge skills and give good feedback. We often heavily intervene in the learning experience and the reflection of the Fruit Orchestra was that intervening less in self-driven activities such as MaKey MaKey might be a better way to go, to increase autonomy and thus drive engagement.
Next was the important question: How can we gets to create and code, where coding is just part of the creating? Can we learn to code differently beyond just choosing a particular language? We have many fascinating technologies but what is the suite of tools over the top that will drive creativity and engagement in this area, to produce effective learning? The short video shown demonstrated a pop-out prefabricated system, where physical interfaces and gestures across those represented coding instructions: coding without any typing at all. (Previous readers will remember my fascination with pre-literate programming.) This early work, electronics on a sheet, is designed to be given away because the production cost is less than 3 Euros. The project is called “code me” from University College London and is designed to teach logic without people realising it: the fundamental building block of computational thinking. Future work includes larger blocks with Bluetooth input and sensors. (I can’t find a web page for this.)
What role should technology play in learning? Professor Rogers mentioned thinking about this in two ways. The inside learning using technology to think about the levels students to reach to foster attainment: personalise, monitor, motivate, flexible, adaptive. The outside learning approach is to work with other people away from the screen: collaborate, create, connect, reflect and play. Professor Rogers believes that the choice is ours but that technology should transform learning to make it active, creative, collaborative, exciting (some other things I didn’t catch) and to recognise the role of suspense in making people think.
An interesting and thought-provoking keynote.
SIGCSE 2014: Research: Concept Inventories and Neo-Piagetian Theory, Thursday 1:45-3:00pm (#SIGCSE2014)
Posted: March 7, 2014 Filed under: Education | Tags: concept inventory, education, education research, higher education, learning, peer instruction, SIGCSE2014, teaching, thinking Leave a commentThe first talk was “Developing a Pre- and Post- Course Concept Inventory to Gauge Operating Systems Learning” presented by Kevin Webb.
Kevin opened by talking about the difficulties we have in sharing our comparison of student learning behaviour and performance. Assessment should be practical, technical, comprehensive, and, most critically, comparable so you can compare these results across instructors, courses and institutions. It is, as we know, difficult to compare homework and lab assignments, student surveys and exam results, for a wide range of reasons. Concept inventories, according to Kevin, give us a mechanism for combining the technical and comparable aspects.
Concept inventories are short, standardised exempts to deal with high-levbe conceptual take-awaks to reveal systematic misconceptions, MCQ format, deployed before and after courses. You can supplement your courses with the small exam to see how student learning is progressing and you can use this to compare performance and learning between classes. The one you’ve probably heard of is the Physics Force Concept Inventory, which Mazur talks about a lot as it was the big motivator for Peer Instruction to address shallow conceptual learning.
There are two Concept Inventories for CS but they’re not publicly available or even maintained anymore but, when they were run, students were less successful than expected – 40-60% of the course was concepts were successfully learned AFTER the course. If your students were struggling with 40% of the key concepts, wouldn’t you like to know?
This work hopes to democratise CI development, using open source principles. (There is an ITiCSE paper coming soon, apparently.) This work has some preliminary development of a CI for Operating Systems.
Goals and challenges included dealing with the diversity of OS courses and trading off which aspects would best fit into the CI. The researchers also wanted it to be transparent and flexible to make questions available immediately and provide a path (via GitHub) for collaboration and iteration. From an accessibility perspective, developing questions for a universal pre-test is hard, and the work is based in the real world where possible.
An example of this is paging/caching replacement, because of the limited capacity of some of these storage mechanism, so the key concept is locality, with an “evict oldest” policy. What happens if the students don’t have the vocabulary of a page table or staleness yet? How about an example of books on your desk, via books on a shelf, via books in the library? (We used similar examples in our new course to explain memory structures in C++ with a supermarket and the various shelves.)
Results so far indicate that taking the OS course improved performance (good) but not all concepts showed an equal increase – some concepts appear to be less intuitive than others. Student confidence increased, even where they weren’t getting the right answers. Scenario “word problems” appear to be challenging to students and opted for similar, less efficient solutions. (This may be related to the “long document hard to read” problem that we’ve observed locally.)
The next example was on indirection with pointers where simplifying the pointer chain was something students intuitively did, even where the resulting solution was sub-optimal. This was tested by asking two similar questions on the exam, where the first was neutrally stated as a “should we” and the second asked them to justify the complexity of something, which gave them a tip as to where the correct answer lay.
Another example, using input/output and polling, presenting the device without a name deprived the students of the ability to use a common pattern. When, in an exam, the device was named (as a disk) then the correct answer was chosen, but the reasoning behind the answer was still lacking – so they appear to be pattern matching, rather than thinking to the answer. From some more discussion, students unsurprisingly appear to choose solutions that match what they have already seen – so they will apply mutexes even in applications where it’s not needed because we drown them in locks. Presenting the same problem without “constricting” names as a code examples, the students could then solve the problem correctly, without locks, despite almost all of them wanting to use locks earlier.
Interesting talk with a fair bit to think about. I need to read the paper! The concept inventory can be found at https://github.com/osconceptinventory” and the group welcome collaboration so go and … what’s the verb for “concept inventory” – inventorise? Anyway, go and do it! (There was a good reminder in question time to mine your TAs for knowledge about what students come to talk to them about – those areas of uncertainty might be ripe for redevelopment!)
The next talk was “Misconceptions and Concept Inventory Questions for Hash Tables and Binary Search Trees” presented by Kuba Karpierz ( a senior Computer Science student at the University of British Columbia). Kuba reviewed the concept inventory concept for newcomers to the room. (Poor Kuba was slightly interrupted by a machine shutdown that nearly broke his presentation but carried on with little evidence of problem and recovered it well.) The core properties of concept inventories are that they must be brief and multiple choice at least.
Students found hash table resizing to be difficult so this was nominated as a CI question. Students would sketch the wrong graph for resizing, ignoring the resize cost and exaggerating the curve shape of what should be a linear increase.The team used think aloud exercises to explain why students picked the wrong solution. Regrettably, the technical problems continued and made it harder to follow the presentation.
A large number of students had no idea how to resize the hash table (for reasons I won’t explain) but this was immediately obvious after the concept inventory exam, rather than having to dig it out of the exams. The next example was on Binary Search Trees and the misconception that they are are always balanced. (It turns out that students are conflating them with heaps.) Looking at the CI MCQs for this, it’s apparent that we were teaching with these exemplars in lectures, but not as an MCQ short exam. Food for thought. The example shown did make me think because it was deliberately ambiguous. I wondered if it would be better if it were slightly less challenging and the students could pick the right answer. Apparently they are looking at this in a different question.
The final talk was “Neo-Piagetian Theory as a Guide to Curriculum Analysis”, presented by Claudia Szabo, from our Computer Science Education Research group. This is the work that we’re using as the basis for the course redesign of our local Object Oriented Programming course so I know this work quite well! (It’s nice to see theory being put into practice, though, isn’t it?)
Claudia started with a discussion of curriculum analyse – the systematic processes that we use to guide teachers to identify instructional goals and learning objectives. We develop, we teach, we observe and we refine, but this refinement may lead to diversion from the originally stated goals. The course loses focus and structure, and possibly even lose its scaffolding. Claudia’s paper has lots of good references for the various theory areas so I won’t reproduce it here but, to get back to the talk, Claudia covered the Piagetian stages of cognitive development in the child: sensorimotor, pre-operational, concrete operational and formal operational. In short, you can handle concepts in pre-, can perform logic and solve for specific situations in concrete but only get to abstract thought and true problem-sovling in the formal operational mode. (Pre-operations is ages 2-7, concrete is 7-11 and formal is 11-15 by the time it is achieved. This is not a short process but also explains why we teach things differently at different age groups.)
Fundamentally, Neo-Piagetian theory starts from the premise that the cognitive developmental stages that humans go through during childhood are seen again as we learn very new and different concepts in new contexts, including mathematics and computer science, exhibited in the same stages. Ultimately, this means places limitations on the amount of abstraction versus concrete reasoning that students can apply. (Without trying to start an Internet battle, neo-Piagetian theory is one of the theories in this space, with the other two that I generally associate being Threshold Concepts and Learning Edge Momentum – we’re going to hold a workshop in Australia shortly to talk about how these intersect, conflict and agree, but I digress.)
So this peer is looking to analyse learning and teaching activities to determine the level at which we are teaching it and the level at which we are assessing it – this should allow us to determine prerequisite concepts (concept is tested before being taught) and assessment leaps (concept is assessed at a level higher than we taught it). The approach uses an ACM CS curriculum basis, combined with course-secific materials, and a neo-Piaget taxonomy to classify teaching activities to work out if we have not provided the correct pre-requisite material or whether we are assessing at a higher level than we taught students (or we provided a learning environment for them to reach that level, if we’re being precise). There’s a really good write-up in the paper to show you how conceptual handling and abstraction changes over the developmental stages.
For example, in representational systems a concrete explanation of memory allocation is “memory allocation is when you use the keyword new to create a variable”. In a familiar Single Abstraction, we could rely upon knowledge of the programming language and the framework to build upon the memory allocation knowledge to explain how memory allocation dynamically requests memory from the free store, initialises it and returns a pointer to the allocated space. If the student was able to carry out Single Abstraction on the global level, they would be able to map their knowledge of memory allocation in C++ into a new language such as Java. As the student developed, they can map abstractions to a global level, so class hierarchies in C++ can be mapped into similar understanding in Java, for example.
The course that was analysed, Object Oriented Programming, had a high failure rate, and students were struggling in the downstream course with fundamental concepts that we thought we had covered in OOP. So a concept definition document was produced to give a laundry list of concepts (Pro tip: concept inventories get big quickly. Be ruthless in your trimming.) For the selected concepts, the authors looked to see where it was taught, how it was taught and then how it was assessed. This quickly identified problems that needed to be fixed. One example is that the important C++ concept of Strings, assessment had been carried out before the concrete operational teaching had taken place! We start to see why the failure rate had been creeping up over time.
As the developer, in association with the speaker, of the new OOP course, this framework is REALLY handy because you are aways thinking “How am I teaching this? Can I assess it at this level yet?” If you do this up front then you can design a much better course, in my opinion, as you can move around the course to get things in the right order at the right time and have enough time to rewrite materials to match the levels. It doesn’t actually take that long to run over the course and it clearly visualises where our pitfalls are.
Next on the table is looking at second and third year courses and improving the visualisation – but I suspect I may have to get involved in that one, personally.
Good session! Lots of great information. Seriously, if you’re not at SIGCSE, why aren’t you here?
