
Streamlining for meaning.
Posted: February 9, 2016 Filed under: Education | Tags: advocacy, aesthetics, assessment, authenticity, beauty, competency-based assessment, design, education, educational problem, educational research, ethics, GPA, higher education, in the student's head, reflection, resources, student perspective, teaching, teaching approaches, thinking Leave a commentIn yesterday’s musings on Grade Point Average, GPA, I said:
But [GPA calculation adjustment] have to be a method of avoidance, this can be a useful focusing device. If a student did really well in, say, Software Engineering but struggled with an earlier, unrelated, stream, why can’t we construct a GPA for Software Engineering that clearly states the area of relevance and degree of information? Isn’t that actually what employers and people interested in SE want to know?
This hits at the heart of my concerns over any kind of summary calculation that obscures the process. Who does this benefit? What use it is to anyone? What does it mean? Let’s look at one of the most obvious consumers of student GPAs: the employers and industry.
Feedback from the Australian industry tells us that employers are generally happy with the technical skills that we’re providing but it’s the softer skills (interpersonal skills, leadership, management abilities) that they would like to see more of and know more about. A general GPA doesn’t tell you this but a Software Engineering focused GPA (as I mentioned above) would show you how a student performed in courses where we would expect to see these skills introduced and exercised.
Putting everything into one transcript gives people the power to assemble this themselves, yes, but this requires the assembler to know what everything means. Most employers have neither the time nor inclination to do this for all 39 or so institutions in Australia. But if a University were to say “this is a summary of performance in these graduate attributes”, where the GAs are regularly focused on the softer skills, then we start to make something more meaningful out of an arbitrary number.
But let’s go further. If we can see individual assessments, rather than coarse subject grades, we can start to construct a model of an individual across the different challenges that they have faced and overcome. Portfolios are, of course, a great way to do this but they’re more work to read than single measures and, too often, such a portfolio is weighed against simpler, apparently meaningful measures such as high GPAs and found wanting. Portfolios also struggle if placed into a context of previous failure, even if recent activity clearly demonstrates that a student has moved on from that troubled or difficult time.
I have a deep ethical and philosophical objection to curve grading, as you probably know. The reason is simple: the actions of one student should not negatively affect the outcomes of another. This same objection is my biggest problem with GPA, although in this case the action and outcomes belong to the same student at different points in her or his life. Rather than using performance in one course to determine access to the learning upon which it depends, we make these grades a permanent effect and every grade that comes afterwards is implicitly mediated through this action.

Sometimes you should be cautious regarding adding curves to address your problems.
Should Past Academic Nick have an inescapable impact on Now and Future Academic Nick’s life? When we look at all of the external influences on success, which make it clear how much totally non-academic things matter, it gets harder and harder to say “Yes, Past Academic Nick is inescapable.” Unfairness is rarely aesthetically pleasing.
An excellent comment on the previous post raised the issue of comparing GPAs in an environment where the higher GPA included some fails but the slightly lower GPA student had always passed. Which was the ‘best’ student from an award perspective? Student A fails three courses at the start of his degree, student B fails three courses at the end. Both pass with the same GPA, time to completion, and number of passes and fails. Is there even a sense of ‘better student’ here? B’s struggles are more immediate and, implicitly, concerns would be raised that these problems could still be active. A has, apparently, moved on in some way. But we’d never know this from simplistic calculations.
If we’re struggling to define ‘best’ and we’re not actually providing something that many people feel is useful, while burdening students with an inescapable past, then the least we can do is to sit down with the people who are affected by this and ask them what they really want.
And then, when they tell us, we do something about changing our systems.
Dances with GPAs
Posted: February 8, 2016 Filed under: Education | Tags: advocacy, aesthetics, assessment, authenticity, beauty, community, competency-based assessment, education, educational problem, educational research, ethics, GPA, higher education, in the student's head, resources, student perspective, teaching, thinking, tools 4 Comments
The trick to dancing with dragons is to never lose your grip on the tail.
If we are going to try and summarise a complicated, long-term process with a single number, and I don’t see such shortcuts going away anytime soon, then it helps to know:
- Exactly what the number represents.
- How it can be used.
- What the processes are that go into its construction.
We have conventions as to what things mean but, when we want to be precise, we have to be careful about our definition and our usage of the final value. As a simple example, one thing that often surprises people who are new to numerical analysis is that there is more than one way of calculating the average value of a group of numbers.
While average in colloquial language would usually mean that we take the sum of all of the numbers and divide them by their count, this is more formally referred to as the arithmetic mean. What we usually want from the average is some indication of what the typical value for this group would be. If you weigh ten bags of wheat and the average weight is 10 kilograms, then that’s what many people would expect the weight to be for future bags, unless there was clear early evidence of high variation (some 500g, some 20 kilograms, for example.)
But the mean is only one way to measure central tendency in a group of numbers. We can also measure the median, the number that separates the highest half of the data from the lowest, or the mode, the value that is the most frequently occurring value in the group.
(This doesn’t even get into the situation where we decide to aggregate the values in a different way.)
If you’ve got ten bags of wheat and nine have 10 kilograms in there, but one has only 5 kilograms, which of these ways of calculating the average is the one you want? The mode is 10kg but the mean is 9.5kg. If you tried to distribute the bags based on the expectation that everyone gets 9.5, you’re going to make nine people very happy and one person unhappy.
Most Grade Point Average calculations are based on a simple arithmetic mean of all available grades, with points allocated from 0 to an upper bound based on the grade performance. As a student adds more courses, these contributions are added to the calculation.
In yesterday’s post, I mused on letting students control which grades go into a GPA calculation and, to explore that, I now have to explain what I mean and why that would change things.
As it stands, because a GPA is an average across all courses, any lower grades will permanently drop the GPA contribution of any higher grades. If a student gets a 7 (A+ or High Distinction) for 71 of her courses and then a single 4 (a Passing grade) for one, her GPA will be 6.875. It can never return to 7. The clear performance band of this student is at the highest level, given that just under 99% of her marks are at the highest level, yet the inclusion of all grades means that a single underperformance, for whatever reason, in three years has cost her standing for those people who care about this figure.
My partner and I discussed some possible approaches to GPA that would be better and, by better, we mean approaches that encourage students to improve, that clearly show what the GPA figure means, and that are much fairer to the student. There are too many external factors contributing to resilience and high performance for me to be 100% comfortable with the questionable representation provided by the GPA.
Before we even think about student control over what is presented, we can easily think of several ways to make a GPA reflect what you have achieved, rather than what you have survived.
- We could only count a percentage of the courses for each student. Even having 90% counted means that students who stumble a little once or twice do not have this permanently etched into a dragging grade.
- We could allow a future attempt at a course with an improved to replace the previous grade. Before we get too caught up in the possibility of ‘gaming’, remember that students would have to pay for this (even if delayed) in most systems and it will add years to their degree. If a student can reach achievement level X in a course then it’s up to us to make sure that does correspond to the achievement level!
- We could only count passes. Given that a student has to assemble sufficient passing grades to be awarded a degree, why then would we include the courses that do not count in a calculation of GPA?
- We could use the mode and report the most common mark the student receives.
- We could do away with it totally. (Not going to happen any time soon.)
- We could pair the GPA with a statistical accompaniment that tells the viewer how indicative it is.
Options 1 and 2 are fairly straight-forward. Option 3 is interesting because it compresses the measurement band to a range of (in my system) 4-7 and this then implicitly recognises that GPA measures for students who graduate are more likely to be in this tighter range: we don’t actually have the degree of separation that we’d assume from a range of 0-7. Option 4 is an interesting way to think about the problem: which grade is the student most likely to achieve, across everything? Option 5 is there for completeness but that’s another post.
Option 6 introduces the idea that we stop GPA being a number and we carefully and accurately contextualise it. A student who receives all high distinctions in first semester still has a number of known hurdles to get over. The GPA of 7 that would be present now is not as clear an indicator of facility with the academic system as a GPA of 7 at the end of a degree, whichever other GPA adjustment systems are in play.
More evidence makes it clearer what is happening. If we can accompany a GPA (or similar measure) with evidence, then we are starting to make the process apparent and we make the number mean something. However, this also allows us to let students control what goes into their calculation, from the grades that they have, as a clear measure of the relevance of that measure can be associated.
But this doesn’t have to be a method of avoidance, this can be a useful focusing device. If a student did really well in, say, Software Engineering but struggled with an earlier, unrelated, stream, why can’t we construct a GPA for Software Engineering that clearly states the area of relevance and degree of information? Isn’t that actually what employers and people interested in SE want to know?
Handing over an academic transcript seems to allow anyone to do this but human cognitive biases are powerful, subtle and pervasive. It is harder for most humans to recognise positive progress in the areas that they are interested in, if there is evidence of less stellar performance elsewhere. I cite my usual non-academic example: Everyone thought Anthony La Paglia’s American accent was too fake until he stopped telling people he was Australian.
If we have to use numbers like this, then let us think carefully about what they mean and, if they don’t mean that much, then let’s either get rid of them or make them meaningful. These should, at a fundamental level, be useful to the students first, us second.
Grades are the fossils of evaluation
Posted: February 6, 2016 Filed under: Education | Tags: advocacy, aesthetics, assessment, authenticity, competency-based assessment, design, education, educational problem, educational research, fossil, higher education, in the student's head, learning, ranking, reflection, resources, student perspective, teaching, teaching approaches, thinking, truth, Wolff 1 CommentAssessments support evaluation, criticism and ranking (Wolff). That’s what it does and, in many cases, that also constitutes a lot of why we do it. But who are we doing it for?
I’ve reflected on the dual nature of evaluation, showing a student her or his level of progress and mastery while also telling us how well the learning environment is working. In my argument to reduce numerical grades to something meaningful, I’ve asked what the actual requirement is for our students, how we measure mastery and how we can build systems to provide this.
But who are the student’s grades actually for?
In terms of ranking, grades allow people who are not the student to place the students in some order. By doing this, we can award awards to students who are in the awarding an award band (repeated word use deliberate). We can restrict our job interviews to students who are summa cum laude or valedictorian or Dean’s Merit Award Winner. Certain groups of students, not all, like to define their progress through comparison so there is a degree of self-ranking but, for the most part, ranking is something that happens to students.
Criticism, in terms of providing constructive, timely feedback to assist the student, is weakly linked to any grading system. Giving someone a Fail grade isn’t a critique as it contains no clear identification of the problems. The clear identification of problems may not constitute a fail. Often these correlate but it’s weak. A student’s grades are not going to provide useful critique to the student by themselves. These grades are to allow us to work out if the student has met our assessment mechanisms to a point where they can count this course as a pre-requisite or can be awarded a degree. (Award!)
Evaluation is, as noted, useful to us and the student but a grade by itself does not contain enough record of process to be useful in evaluating how mastery goals were met and how the learning environment succeeded or failed. Competency, when applied systematically, does have a well-defined meaning. A passing grade does not although there is an implied competency and there is a loose correlation with achievement.
Grades allow us to look at all of a student’s work as if this one impression is a reflection of the student’s involvement, engagement, study, mistakes, triumphs, hopes and dreams. They are additions to a record from which we attempt to reconstruct a living, whole being.
Grades are the fossils of evaluation.
Grades provide a mechanism for us, in a proxy role as academic archaeologist, to classify students into different groups, in an attempt to project colour into grey stone, to try and understand the ecosystem that such a creature would live in, and to identify how successful this species was.
As someone who has been a student several times in my life, I’m aware that I have a fossil record that is not traditional for an academic. I was lucky to be able to place a new imprint in the record, to obscure my history as a much less successful species, and could then build upon it until I became an ACADEMIC TYRANNOSAURUS.

LIFE LONG LEARNING, ROAARRRR!
But I’m lucky. I’m privileged. I had a level of schooling and parental influence that provided me with an excellent vocabulary and high social mobility. I live in a safe city. I have a supportive partner. And, more importantly, at a crucial moment in my life, someone who knew me told me about an opportunity that I was able to pursue despite the grades that I had set in stone. A chance came my way that I never would have thought of because I had internalised my grades as my worth.
Let’s look at the fossil record of Nick.
My original GPA fossil, encompassing everything that went wrong and right in my first degree, was 2.9. On a scale of 7, which is how we measure it, that’s well below a pass average. I’m sharing that because I want you to put that fact together with what happened next. Four years later, I started a Masters program that I finished with a GPA of 6.4. A few years after the masters, I decided to go and study wine making. That degree was 6.43. Then I received a PhD, with commendation, that is equivalent to GPA 7. (We don’t actually use GPA in research degrees. Hmmm.) If my grade record alone lobbed onto your desk you would see the desiccated and dead snapshot of how I (failed to) engage with the University system. A lot of that is on me but, amazingly, it appears that much better things were possible. That original grade record stopped me from getting interviews. Stopped me from getting jobs. When I was finally able to demonstrate the skills that I had, which weren’t bad, I was able to get work. Then I had the opportunity to rewrite my historical record.
Yes, this is personal for me. But it’s not about me because I wasn’t trapped by this. I was lucky as well as privileged. I can’t emphasise that enough. The fact that you are reading this is due to luck. That’s not a good enough mechanism.
Too many students don’t have this opportunity. That impression in the wet mud of their school life will harden into a stone straitjacket from which they may never escape. The way we measure and record grades has far too much potential to work against students and the correlation with actual ability is there but it’s not strong and it’s not always reliable.
The student you are about to send out with a GPA of 2.9 may be competent and they are, most definitely, more than that number.
The recording of grades is a high-loss storage record of the student’s learning and pathway to mastery. It allows us to conceal achievement and failure alike in the accumulation of mathematical aggregates that proxy for competence but correlate weakly.
We need assessment systems that work for the student first and everyone else second.
First year course evaluation scheme
Posted: January 22, 2016 Filed under: Education, Opinion | Tags: advocacy, aesthetics, assessment, authenticity, beauty, design, education, educational problem, ethics, higher education, learning, reflection, resources, student perspective, teaching, teaching approaches, time management 2 CommentsIn my earlier post, I wrote:
Even where we are using mechanical or scripted human [evaluators], the hand of the designer is still firmly on the tiller and it is that control that allows us to take a less active role in direct evaluation, while still achieving our goals.
and I said I’d discuss how we could scale up the evaluation scheme to a large first year class. Finally, thank you for your patience, here it is.
The first thing we need to acknowledge is that most first-year/freshman classes are not overly complex nor heavily abstract. We know that we want to work concrete to abstract, simple to complex, as we build knowledge, taking into account how students learn, their developmental stages and the mechanics of human cognition. We want to focus on difficult concepts that students struggle with, to ensure that they really understand something before we go on.
In many courses and disciplines, the skills and knowledge we wish to impart are fundamental and transformative, but really quite straight-forward to evaluate. What this means, based on what I’ve already laid out, is that my role as a designer is going to be crucial in identifying how we teach and evaluate the learning of concepts, but the assessment or evaluation probably doesn’t require my depth of expert knowledge.
The model I put up previously now looks like this:
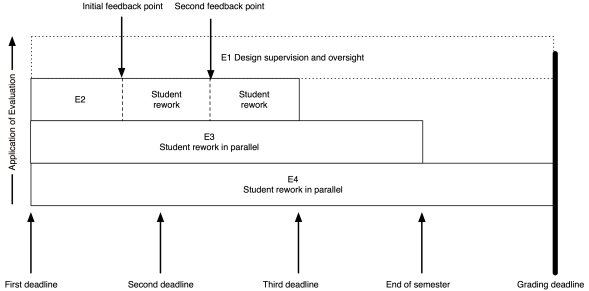
My role (as the notional E1) has moved entirely to design and oversight, which includes developing the E3 and E4 tests and training the next tier down, if they aren’t me.
As an example, I’ve put in two feedback points, suitable for some sort of worked output in response to an assignment. Remember that the E2 evaluation is scripted (or based on rubrics) yet provides human nuance and insight, with personalised feedback. That initial feedback point could be peer-based evaluation, group discussion and demonstration, or whatever you like. The key here is that the evaluation clearly indicates to the student how they are travelling; it’s never just “8/10 Good”. If this is a first year course then we can capture much of the required feedback with trained casuals and the underlying automated systems, or by training our students on exemplars to be able to evaluate each other’s work, at least to a degree.
The same pattern as before lies underneath: meaningful timing with real implications. To get access to human evaluation, that work has to go in by a certain date, to allow everyone involved to allow enough time to perform the task. Let’s say the first feedback is a peer-assessment. Students can be trained on exemplars, with immediate feedback through many on-line and electronic systems, and then look at each other’s submissions. But, at time X, they know exactly how much work they have to do and are not delayed because another student handed up late. After this pass, they rework and perhaps the next point is a trained casual tutor, looking over the work again to see how well they’ve handled the evaluation.
There could be more rework and review points. There could be less. The key here is that any submission deadline is only required because I need to allocate enough people to the task and keep the number of tasks to allocate, per person, at a sensible threshold.
Beautiful evaluation is symmetrically beautiful. I don’t overload the students or lie to them about the necessity of deadlines but, at the same time, I don’t overload my human evaluators by forcing them to do things when they don’t have enough time to do it properly.
As for them, so for us.
Throughout this process, the E1 (supervising evaluator) is seeing all of the information on what’s happening and can choose to intervene. At this scale, if E1 was also involved in evaluation, intervention would be likely last-minute and only in dire emergency. Early intervention depends upon early identification of problems and sufficient resources to be able to act. Your best agent of intervention is probably the person who has the whole vision of the course, assisted by other human evaluators. This scheme gives the designer the freedom to have that vision and allows you to plan for how many other people you need to help you.
In terms of peer assessment, we know that we can build student communities and that students can appreciate each other’s value in a way that enhances their perceptions of the course and keeps them around for longer. This can be part of our design. For example, we can ask the E2 evaluators to carry out simple community-focused activities in classes as part of the overall learning preparation and, once students are talking, get them used to the idea of discussing ideas rather than having dualist confrontations. This then leads into support for peer evaluation, with the likelihood of better results.
Some of you will be saying “But this is unrealistic, I’ll never get those resources.” Then, in all likelihood, you are going to have to sacrifice something: number of evaluations, depth of feedback, overall design or speed of intervention.
You are a finite resource. Killing you with work is not beautiful. I’m writing all of this to speak to everyone in the community, to get them thinking about the ugliness of overwork, the evil nature of demanding someone have no other life, the inherent deceit in pretending that this is, in any way, a good system.
We start by changing our minds, then we change the world.
Four-tier assessment
Posted: January 19, 2016 Filed under: Education, Opinion | Tags: aesthetics, assessment, authenticity, beauty, community, design, dewey, education, educational problem, educational research, ethics, higher education, in the student's head, intrinsic motivation, john c. dewey, learning, motivation, resources, teaching, teaching approaches, time, time management, tools 1 CommentWe’ve looked at a classification of evaluators that matches our understanding of the complexity of the assessment tasks we could ask students to perform. If we want to look at this from an aesthetic framing then, as Dewey notes:
“By common consent, the Parthenon is a great work of art. Yet it has aesthetic standing only as the work becomes an experience for a human being.”
John Dewey, Art as Experience, Chapter 1, The Live Creature.
Having a classification of evaluators cannot be appreciated aesthetically unless we provide a way for it to be experienced. Our aesthetic framing demands an implementation that makes use of such an evaluator classification, applies to a problem where we can apply a pedagogical lens and then, finally, we can start to ask how aesthetically pleasing it is.
And this is what brings us to beauty.
A systematic allocation of tasks to these different evaluators should provide valid and reliable marking, assuming we’ve carried out our design phase correctly. But what about fairness, motivation or relevancy, the three points that we did not address previously? To be able to satisfy these aesthetic constraints, and to confirm the others, it now matters how we handle these evaluation phases because it’s not enough to be aware that some things are going to need different approaches, we have to create a learning environment to provide fairness, motivation and relevancy.
I’ve already argued that arbitrary deadlines are unfair, that extrinsic motivational factors are grossly inferior to those found within, and, in even earlier articles, that we too insist on the relevancy of the measurements that we have, rather than designing for relevancy and insisting on the measurements that we need.
To achieve all of this and to provide a framework that we can use to develop a sense of aesthetic satisfaction (and hence beauty), here is a brief description of a four-tier, penalty free, assessment.
Let’s say that, as part of our course design, we develop an assessment item, A1, that is one of the elements to provide evaluation coverage of one of the knowledge areas. (Thus, we can assume that A1 is not required to be achieved by itself to show mastery but I will come back to this in a later post.)
Recall that the marking groups are: E1, expert human markers; E2, trained or guided human markers; E3, complex automated marking; and E4, simple and mechanical automated marking.
A1 has four, inbuilt, course deadlines but rather than these being arbitrary reductions of mark, these reflect the availability of evaluation resource, a real limitation as we’ve already discussed. When the teacher sets these courses up, she develops an evaluation scheme for the most advanced aspects (E1, which is her in this case), an evaluation scheme that could be used by other markers or her (E2), an E3 acceptance test suite and some E4 tests for simplicity. She matches the aspects of the assignment to these evaluation groups, building from simple to complex, concrete to abstract, definite to ambiguous.
The overall assessment of work consists of the evaluation of four separate areas, associated with each of the evaluators. Individual components of the assessment build up towards the most complex but, for example, a student should usually have had to complete at least some of E4-evaluated work to be able to attempt E3.
Here’s a diagram of the overall pattern for evaluation and assessment.

The first deadline for the assignment is where all evaluation is available. If students provide their work by this time, the E1 will look at the work, after executing the automated mechanisms, first E4 then E3, and applying the E2 rubrics. If the student has actually answered some E1-level items, then the “top tier” E1 evaluator will look at that work and evaluate it. Regardless of whether there is E1 work or not, human-written feedback from the lecturer on everything will be provided if students get their work in at that point. This includes things that would be of help for all other levels. This is the richest form of feedback, it is the most useful to the students and, if we are going to use measures of performance, this is the point at which the most opportunities to demonstrate performance can occur.
This feedback will be provided in enough time that the students can modify their work to meet the next deadline, which is the availability of E2 markers. Now TAs or casuals are marking instead or the lecturer is now doing easier evaluation from a simpler rubric. These human markers still start by running the automated scripts, E4 then E3, to make sure that they can mark something in E2. They also provide feedback on everything in E2 to E4, sent out in time for students to make changes for the next deadline.
Now note carefully what’s going on here. Students will get useful feedback, which is great, but because we have these staggered deadlines, we can pass on important messages as we identify problems. If the class is struggling with key complex or more abstract elements, harder to fix and requiring more thought, we know about it quickly because we have front-loaded our labour.
Once we move down to the fully automated systems, we’re losing opportunities for rich and human feedback to students who have not yet submitted. However, we have a list of students who haven’t submitted, which is where we can allocate human labour, and we can encourage them to get work in, in time for the E3 “complicated” script. This E3 marking script remains open for the rest of the semester, to encourage students to do the work sometime ahead of the exam. At this point, the discretionary allocation of labour for feedback is possible, because the lecturer has done most of the hard work in E1 and E2 and should, with any luck, have far fewer evaluation activities for this particular assignment. (Other things may intrude, including other assignments, but we have time bounds on this one, which is better than we often have!)
Finally, at the end of the teaching time (in our parlance, a semester’s teaching will end then we will move to exams), we move the assessment to E4 marking only, giving students the ability (if required) to test their work to meet any “minimum performance” requirements you may have for their eligibility to sit the exam. Eventually, the requirement to enter a record of student performance in this course forces us to declare the assessment item closed.
This is totally transparent and it’s based on real resource limitations. Our restrictions have been put in place to improve student feedback opportunities and give them more guidance. We have also improved our own ability to predict our workload and to guide our resource requests, as well as allowing us to reuse some elements of automated scripts between assignments, without forcing us to regurgitate entire assignments. These deadlines are not arbitrary. They are not punitive. We have improved feedback and provided supportive approaches to encourage more work on assignments. We are able to get better insight into what our students are achieving, against our design, in a timely fashion. We can now see fairness, intrinsic motivation and relevance.
I’m not saying this is beautiful yet (I think I have more to prove to you) but I think this is much closer than many solutions that we are currently using. It’s not hiding anything, so it’s true. It does many things we know are great for students so it looks pretty good.
Tomorrow, we’ll look at whether such a complicated system is necessary for early years and, spoilers, I’ll explain a system for first year that uses peer assessment to provide a similar, but easier to scale, solution.
At least they’re being honest
Posted: January 13, 2016 Filed under: Education, Opinion | Tags: advocacy, assessment, authenticity, community, competency-based assessment, education, educational research, ethics, higher education, learning, reflection, student perspective, teaching, teaching approaches, thinking, time banking, time management, tools 2 CommentsI was inspired to write this by a comment about using late penalties but dealing slightly differently with students when they owned up to being late. I have used late penalties extensively (it’s school policy) and so I have a lot of experience with the many ways students try to get around them.

Like everyone, I have had students who have tried to use honesty where every other possible way of getting the assignment in on time (starting early, working on it before the day before, miraculous good luck) has failed. Sometimes students are puzzled that “Oh, I was doing another assignment from another lecturer” isn’t a good enough excuse. (Genuine reasons for interrupted work, medical or compassionate, are different and I’m talking about the ambit extension or ‘dog ate my homework’ level of bargaining.)
My reasoning is simple. In education, owning up to something that you did knowing that it would have punitive consequences of some sort should not immediately cause things to become magically better. Plea bargaining (and this is an interesting article of why that’s not a good idea anywhere) is you agreeing to your guilt in order to reduce your sentence. But this is, once again, horse-trading knowledge on the market. Suddenly, we don’t just have a temporal currency, we have a conformal currency, where getting a better deal involves finding the ‘kindest judge’ among the group who will give you the ‘lightest sentence’. Students optimise their behaviour to what works or, if they’re lucky, they have a behaviour set that’s enough to get them to a degree without changing much. The second group aren’t mostly who we’re talking about and I don’t want to encourage the first group to become bargain-hunting mark-hagglers.
I believe that ‘finding Mr Nice Lecturer’ behaviour is why some students feel free to tell me that they thought someone else’s course was more important than mine, because I’m a pretty nice person and have a good rapport with my students, and many of my colleagues can be seen (fairly or not) as less approachable or less open.
We are not doing ourselves or our students any favours. At the very least, we risk accusations of unfairness if we extend benefits to one group who are bold enough to speak to us (and we know that impostor syndrome and lack of confidence are rife in under-represented groups). At worst, we turn our students into cynical mark shoppers, looking for the easiest touch and planning their work strategy based on what they think they can get away with instead of focusing back on the learning. The message is important and the message must be clearly communicated so that students try to do the work for when it’s required. (And I note that this may or may not coincide with any deadlines.)
We wouldn’t give credit to someone who wrote ‘True’ and then said ‘Oh, but I really meant False’. The work is important or it is not. The deadline is important or it is not. Consequences, in a learning sense, do not have to mean punishments and we do not need to construct a Star Chamber in our offices.
Yes, I do feel strongly about this. I completely understand why people do this and I have also done this before. But after thinking about it at length, I changed my practice so that being honest about something that shouldn’t have happened was appreciated but it didn’t change what occurred unless there was a specific procedural difference in handling. I am not a judge. I am not a jury. I want to change the system so that not only do I not have to be but I’m not tempted to be.
EduTech AU 2015, Day 2, Higher Ed Leaders, “Assessment: The Silent Killer of Learning”, #edutechau @eric_mazur
Posted: June 3, 2015 Filed under: Education | Tags: assessment, educational problem, educational research, edutech2015, edutechau, eric mazur, feedback, harvard, higher education, in the student's head, learning, peer instruction, plagiarism, student perspective, students, teaching, teaching approaches, thinking, time banking, tools, universal principles of design, workload 3 CommentsNo surprise that I’m very excited about this talk as well. Eric is a world renowned educator and physicist, having developed Peer Instruction in 1990 for his classes at Harvard as a way to deal with students not developing a working physicist’s approach to the content of his course. I should note that Eric also gave this talk yesterday and the inimitable Steve Wheeler blogged that one, so you should read Steve as well. But after me. (Sorry, Steve.)
I’m not an enormous fan of most of the assessment we use as most grades are meaningless, assessment becomes part of a carrot-and-stick approach and it’s all based on artificial timelines that stifle creativity. (But apart from that, it’s fine. Ho ho.) My pithy statement on this is that if you build an adversarial educational system, you’ll get adversaries, but if you bother to build a learning environment, you’ll get learning. One of the natural outcomes of an adversarial system is activities like cheating and gaming the system, because people start to treat beating the system as the goal itself, which is highly undesirable. You can read a lot more about my views on plagiarism here, if you like. (Warning: that post links to several others and is a bit of a wormhole.)
Now, let’s hear what Eric has to say on this! (My comments from this point on will attempt to contain themselves in parentheses. You can find the slides for his talk – all 62MB of them – from this link on his website. ) It’s important to remember that one of the reasons that Eric’s work is so interesting is that he is looking for evidence-based approaches to education.
Eric discussed the use of flashcards. A week after Flashcard study, students retain 35%. After two weeks, it’s almost gone. He tried to communicate this to someone who was launching a cloud-based flashcard app. Her response was “we only guarantee they’ll pass the test”.
*low, despairing chuckle from the audience*
Of course most students study to pass the test, not to learn, and they are not the same thing. For years, Eric has been bashing the lecture (yes, he noted the irony) but now he wants to focus on changing assessment and getting it away from rote learning and regurgitation. The assessment practices we use now are not 21st century focused, they are used for ranking and classifying but, even then, doing it badly.
So why are we assessing? What are the problems that are rampant in our assessment procedure? What are the improvements we can make?
How many different purposes of assessment can you think of? Eric gave us 90s to come up with a list. Katrina and I came up with about 10, most of which were serious, but it was an interesting question to reflect upon. (Eric snuck
- Rate and rank students
- Rate professor and course
- Motivate students to keep up with work
- Provide feedback on learning to students
- Provide feedback to instructor
- Provide instructional accountability
- Improve the teaching and learning.
Ah, but look at the verbs – they are multi-purpose and in conflict. How can one thing do so much?
So what are the problems? Many tests are fundamentally inauthentic – regurgitation in useless and inappropriate ways. Many problem-solving approaches are inauthentic as well (a big problem for computing, we keep writing “Hello, World”). What does a real problem look like? It’s an interruption in our pathway to our desired outcome – it’s not the outcome that’s important, it’s the pathway and the solution to reach it that are important. Typical student problem? Open the book to chapter X to apply known procedure Y to determine an unknown answer.
Shout out to Bloom’s! Here’s Eric’s slide to remind you.
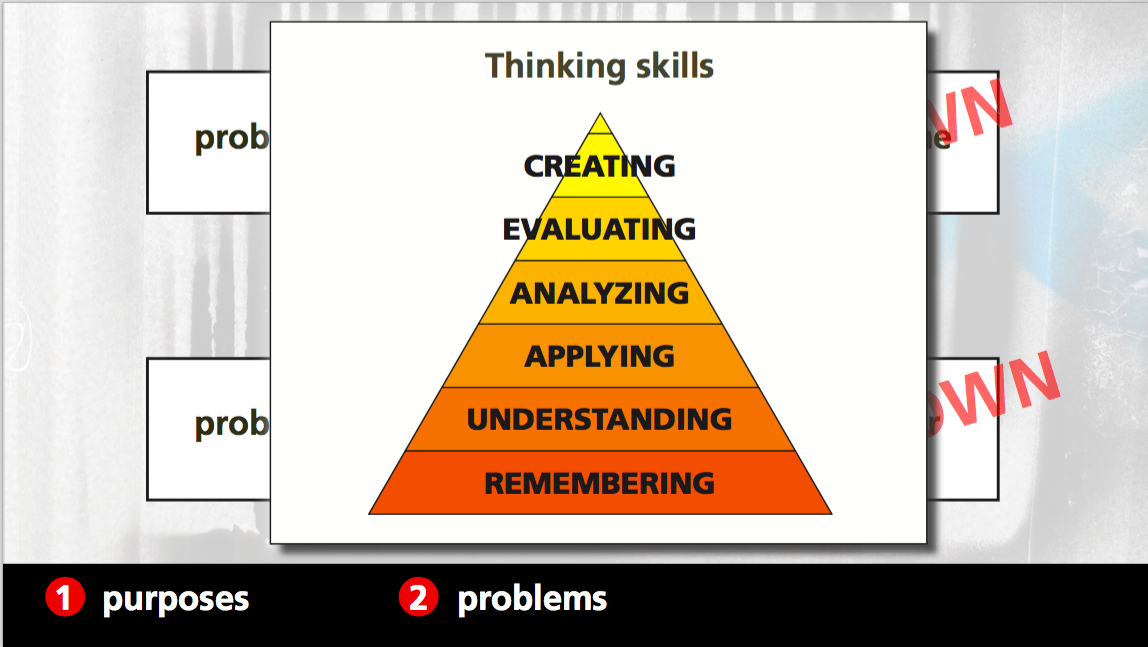
Rights reside with Eric Mazur.
Eric doesn’t think that many of us, including Harvard, even reach the Applying stage. He referred to a colleague in physics who used baseball problems throughout the course in assignments, until he reached the final exam where he ran out of baseball problems and used football problems. “Professor! We’ve never done football problems!” Eric noted that, while the audience were laughing, we should really be crying. If we can’t apply what we’ve learned then we haven’t actually learned i.
Eric sneakily put more audience participation into the talk with an open ended question that appeared to not have enough information to come up with a solution, as it required assumptions and modelling. From a Bloom’s perspective, this is right up the top.
Students loathe assumptions? Why? Mostly because we’ll give them bad marks if they get it wrong. But isn’t the ability to make assumptions a really important skill? Isn’t this fundamental to success?
Eric demonstrated how to tame the problem by adding in more constraints but this came at the cost of the creating stage of Bloom’s and then the evaluating and analysing. (Check out his slides, pages 31 to 40, for details of this.) If you add in the memorisation of the equation, we have taken all of the guts out of the problem, dropping down to the lowest level of Bloom’s.
But, of course, computers can do most of the hard work for that is mechanistic. Problems at the bottom layer of Bloom’s are going to be solved by machines – this is not something we should train 21st Century students for.
But… real problem solving is erratic. Riddled with fuzziness. Failure prone. Not guaranteed to succeed. Most definitely not guaranteed to be optimal. The road to success is littered with failures.
But, if you make mistakes, you lose marks. But if you’re not making mistakes, you’re very unlikely to be creative and innovative and this is the problem with our assessment practices.
Eric showed us a stress of a traditional exam room: stressful, isolated, deprived of calculators and devices. Eric’s joke was that we are going to have to take exams naked to ensure we’re not wearing smart devices. We are in a time and place where we can look up whatever we want, whenever we want. But it’s how you use that information that makes a difference. Why are we testing and assessing students under such a set of conditions? Why do we imagine that the result we get here is going to be any indicator at all of the likely future success of the student with that knowledge?
Cramming for exams? Great, we store the information in short-term memory. A few days later, it’s all gone.
Assessment produces a conflict, which Eric noticed when he started teaching a team and project based course. He was coaching for most of the course, switching to a judging role for the monthly fair. He found it difficult to judge them because he had a coach/judge conflict. Why do we combine it in education when it would be unfair or unpleasant in every other area of human endeavour? We hide between the veil of objectivity and fairness. It’s not a matter of feelings.
But… we go back to Bloom’s. The only thinking skill that can be evaluated truly objectively is remembering, at the bottom again.
But let’s talk about grade inflation and cheating. Why do people cheat at education when they don’t generally cheat at learning? But educational systems often conspire to rob us of our ownership and love of learning. Our systems set up situations where students cheat in order to succeed.
- Mimic real life in assessment practices!
Open-book exams. Information sticks when you need it and use it a lot. So use it. Produce problems that need it. Eric’s thought is you can bring anything you want except for another living person. But what about assessment on laptops? Oh no, Google access! But is that actually a problem? Any question to which the answer can be Googled is not an authentic question to determine learning!
Eric showed a video of excited students doing a statistic tests as a team-based learning activity. After an initial pass at the test, the individual response is collected (for up to 50% of the grade), and then students work as a group to confirm the questions against an IF AT scratchy card for the rest of the marks. Discussion, conversation, and the students do their own grading for you. They’ve also had the “A-ha!” moment. Assessment becomes a learning opportunity.
Eric’s not a fan of multiple choice so his Learning Catalytics software allows similar comparison of group answers without having to use multiple choice. Again, the team based activities are social, interactive and must less stressful.
- Focus on feedback, not ranking.
Objective ranking is a myth. The amount of, and success with, advanced education is no indicator of overall success in many regards. So why do we rank? Eric showed some graphs of his students (in earlier courses) plotting final grades in physics against the conceptual understanding of force. Some people still got top grades without understanding force as it was redefined by Newton. (For those who don’t know, Aristotle was wrong on this one.) Worse still is the student who mastered the concept of force and got a C, when a student who didn’t master force got an A. Objectivity? Injustice?
- Focus on skills, not content
Eric referred to Wiggins and McTighe, “Understanding by Design.” Traditional approach is course content drives assessment design. Wiggins advocates identifying what the outcomes are, formulate these as action verbs, ‘doing’ x rather than ‘understanding’ x. You use this to identify what you think the acceptable evidence is for these outcomes and then you develop the instructional approach. This is totally outcomes based.
- resolve coach/judge conflict
In his project-based course, Eric brought in external evaluators, leaving his coach role unsullied. This also validates Eric’s approach in the eyes of his colleagues. Peer- and self-evaluation are also crucial here. Reflective time to work out how you are going is easier if you can see other people’s work (even anonymously). Calibrated peer review, cpr.molsci.ucla.edu, is another approach but Eric ran out of time on this one.
If we don’t rethink assessment, the result of our assessment procedures will never actually provide vital information to the learner or us as to who might or might not be successful.
I really enjoyed this talk. I agree with just about all of this. It’s always good when an ‘internationally respected educator’ says it as then I can quote him and get traction in change-driving arguments back home. Thanks for a great talk!
Workshop report: ALTC Workshop “Assessing student learning against the Engineering Accreditation Competency Standards: A practical approach”
Posted: October 12, 2012 Filed under: Education | Tags: assessment, community, curriculum, education, educational problem, educational research, feedback, Generation Why, higher education, jeff froyd, learning, principles of design, reflection, teaching, teaching approaches, thinking, time banking, tools, universal principles of design, wageeh boles Leave a commentI was fortunate to be able to attend a 3 hour workshop today presented by Professor Wageeh Boles, Queensland University of Technology, and Professor Jeffrey (Jeff) Froyd, Texas A&M, on how we could assess student learning against the accreditation competency standards in Engineering. I’ve seen Wageeh present before in his capacity as an Australian Learning and Teaching Council ALTC National Teaching Fellowship and greatly enjoyed it, so I was looking forward to today. (Note: the ALTC has been replaced with the Office for Learning and Teaching, OLT, but a number of schemes are still labelled under the old title. Fortunately, I speak acronym.)
Both Wageeh and Jeff spoke at length about why we were undertaking assessment and we started by looking at the big picture: University graduate capabilities and the Engineers Australia accreditation criteria. Like it or not, we live in a world where people expect our students to be able to achieve well-defined things and be able to demonstrate certain skills. To focus on the course, unit, teaching and learning objectives and assessment alone, without framing this in the national and University expectations is to risk not producing the students that are expected or desired. Ultimately if the high level and local requirements aren’t linked then they should be because otherwise we’re probably not pursuing the right objectives. (Is it too soon to mention pedagogical luck again?)
We then discussed three types of assessment:
- Assessment FOR Learning: Which is for teachers and allows them to determine the next steps in advancing learning.
- Assessment AS Learning: Which is for students and allows them to monitor and reflect upon their own progress (effectively formative).
- Assessment OF Learning: Which is used to assess what the students have learned and is most often characterised as summative learning.
But, after being asked about the formative/summative approach, this was recast into a decision making framework. We carry out assessment of all kinds to allow people to make better decisions and the people, in this situation, are Educators and Students. When we see the results of the summative assessment we, as teachers, can then ask “What decisions do we need to make for this class?” to improve the levels of knowledge demonstrated in the summative. When the students see the result of formative assessment, we then have the question “What decisions do students need to make” to improve their own understanding. The final aspect, Assessment FOR Learning, is going to cover those areas of assessment that help both educators and students to make better decisions by making changes to the overall course in response to what we’re seeing.
This is a powerful concept as it identifies assessment in terms of responsible groups: this assessment involves one group, the other or both and this is why you need to think about the results. (As an aside, this is why I strongly subscribe to the idea that formative assessment should never have an extrinsic motivating aspect, like empty or easy submission marks, because it stops the student focussing on the feedback, which will help their decisions, and makes it look summative, which suddenly starts to look like the educator’s problem.)
One point that came out repeatedly was that our assessment methods should be varied. If your entire assessment is based on a single exam, of one type of question, at the end of the semester then you really only have a single point of data. Anyone who has ever drawn a line on a graph knows that a single point tells you nothing about the shape of the line and, ultimately, the more points that yo can plot accurately, the more you can work out what is actually happening. However, varying assessment methods doesn’t mean replicating or proxying the exam, it means providing different assessment types, varying questions, changing assessment over time. (Yes, this was stressed: changing assessment from offering to offering is important and is much a part of varying assessment as any other component.)
All delightful music to my ears, which was just was well as we all worked very hard, talking, discussing and sharing ideas throughout the groups. We had a range of people who were mostly from within the Faculty and, while it was a small group and full of the usual faces, we all worked well, had an open discussion and there were some first-timers who obviously learned a lot.
What I found great about this was that it was very strongly practical. We worked on our own courses, looked for points for improvement and I took away four points of improvement that I’m currently working on: a fantastic result for a three-hour investment. Our students don’t need to just have done assessment that makes it look like they know their stuff, they have to actually know their stuff and be confident with it. Job ready. Able to stand up and demonstrate their skills. Ready for reality.
As was discussed in the workshop, assessment of learning occurs when Lecturers:
- Use evidence of student learning
- to make judgements on student achievement
- against goals and standards
And this identifies some of our key problems. We often gather all of the evidence, whether it’s final grades or Student Evaluations, at a point when the students have left, or are just about to leave, the course. How can we change this course for that student? We are always working one step in the past. Even if we do have the data, do we have the time and the knowledge to make the right judgement? If so, is it defensible, fair and meeting the standards that we should be meeting? We can’t apply standards from 20 years ago because that’s what we’re used to. The future, in Australia, is death by educational acronyms (AQF, TEQSA, EA, ACS, OLT…) but these are the standards by which we are accredited and these are the yardsticks by which our students will be judged. If we want to change those then, sure, we can argue this at the Government level but until then, these have to be taken into account, along with all of our discipline, faculty and University requirements.
I think that this will probably spill over in a second post but, in short, if you get a chance to see Wageeh and Jeff on the road with this workshop then, please, set aside the time to go and leave time for a chat afterwards. This is one of the most rewarding and useful activities that I’ve done this year – and I’ve had a very good year for thinking about CS Education.
