
Being honest about driverless cars
Posted: January 25, 2016 Filed under: Education, Opinion | Tags: advocacy, aesthetics, authenticity, beauty, blogging, community, driverless car, education, ethics, good, higher education, resources, teaching, teaching approaches, tools, trolley problem, truth, utilitarianism Leave a commentI have been following the discussion about the ethics of the driverless car with some interest. This is close to a contemporary restatement of the infamous trolley problem but here we are instructing a trolley in a difficult decision: if I can save more lives by taking lives, should I do it? In the case of a driverless car, should the car take action that could kill the driver if, in doing so, it is far more likely to save more lives than would be lost?
While I find the discussion interesting, I worry that such discussion makes people unduly worried about driverless cars, potentially to a point that will delay adoption. Let’s look into why I think that. (I’m not going to go into whether cars, themselves, are a good or bad thing.)
Many times, the reason for a driverless car having to make such a (difficult) decision is that “a person leaps out from the kerb” or “driving conditions are bad” and “it would be impossible to stop in time.”
As noted in CACM:
The driverless cars of the future are likely to be able to outperform most humans during routine driving tasks, since they will have greater perceptive abilities, better reaction times, and will not suffer from distractions (from eating or texting, drowsiness, or physical emergencies such as a driver having a heart attack or a stroke).
In every situation where a driverless car could encounter a situation that would require such an ethical dilemma be resolved, we are already well within the period at which a human driver would, on average, be useless. When I presented the trolley problem, with driverless cars, to my students, their immediate question was why a dangerous situation had arisen in the first place? If the car was driving in a way that it couldn’t stop in time, there’s more likely to be a fault in environmental awareness or stopping-distance estimation.
If a driverless car is safe in varied weather conditions, then it has no need to be travelling at the speed limit merely because the speed limit is set. We all know the mantra of driving: drive to the conditions. In a driverless car scenario, the sensory awareness of the car is far greater than our own (and we should demand that it was) and thus we will eliminate any number of accidents before we arrived at an ethical problem.
Millions of people are killed in car accidents every year because of drink driving and speeding. In Victoria, Australia, close to 40% of accidents are tied to long distance driving and fatigue. We would eliminate most, if not all, of these deaths immediately with driverless technology adopted en masse.
What about people leaping out in front of the car? In my home city, Adelaide, South Australia, the average speed across the city is just under 30 kilometres per hour, despite the speed limit being 50 (traffic lights and congestion has a lot to do with this). The average human driver takes about 1.5 seconds to react (source), then braking deceleration is about 7 metres per second per second, less effectively in the wet. From that source, the actual stopping part of the braking, if we’re going 30km/h, is going to be less than 9 metres if it’s dry, 13 metres if wet. Other sources note that, with human reactions, the minimum overall braking is about 12 metres, 6 of which are braking. The good news is that 30km/h is already the speed at which only 10% of pedestrians are killed and, given how quickly an actively sensing car could react and safely coordinate braking without skidding, the driverless car is incredibly unlikely to be travelling fast enough to kill someone in an urban environment and still be able to provide the same average speed as we had.
The driverless car, without any ethics beyond “brake to avoid collisions”, will be causing a far lower level of injury and death. They don’t drink. They don’t sleep. They don’t speed. They will react faster than humans.
(That low urban speed thing isn’t isolated. Transport for London estimate the average London major road speed to be around 31 km/h, around 15km/h for Central London. Central Berlin is about 24 km/h, Warsaw is 26. Paris is 31 km/h and has a fraction of London’s population, about twice the size of my own city.)
Human life is valuable. Rather than focus on the impact on lives that we can see, as the Trolley Problem does, taking a longer view and looking at the overall benefits of the driverless car quickly indicates that, even if driverless cars are dumb and just slam on the brakes, the net benefit is going to exceed any decisions made because of the Trolley Problem model. Every year that goes by without being able to use this additional layer of safety in road vehicles is costing us millions of lives and millions of injuries. As noted in CACM, we already have some driverless car technologies and these are starting to make a difference but we do have a way to go.
And I want this interesting discussion of ethics to continue but I don’t want it to be a reason not to go ahead, because it’s not an honest comparison and saying that it’s important just because there’s no human in the car is hypocrisy.
I wish to apply the beauty lens to this. When we look at a new approach, we often find things that are not right with it and, given that we have something that works already, we may not adopt a new approach because we are unsure of it or there are problems. The aesthetics of such a comparison, the characteristics we wish to maximise, are the fair consideration of evidence, that the comparison be to the same standard, and a commitment to change our course if the evidence dictates that it be so. We want a better outcome and we wish to make sure that any such changes made support this outcome. We have to be honest about our technology: some things that are working now and that we are familiar with are not actually that good or they are solving a problem that we might no longer need to solve.
Human drivers do not stand up to many of the arguments presented as problems to be faced by driverless cars. The reason that the trolley problems exists in so many different forms, and the fact that it continues to be debated, shows that this is not a problem that we have moved on from. You would also have to be highly optimistic in your assessment of the average driver to think that a decision such as “am I more valuable than that evil man standing on the road” is going through anyone’s head; instead, people jam on the brakes. We are holding driverless cars to a higher standard than we accept for driving when it’s humans. We posit ‘difficult problems’ that we apparently ignore every time we drive in the rain because, if we did not, none of us would drive!
Humans are capable of complex ethical reasoning. This does not mean that they employ it successfully in the 1.5 seconds of reaction time before slamming on the brakes.
We are not being fair in this assessment. This does not diminish the value of machine ethics debate but it is misleading to focus on it here as if it really matters to the long term impact of driverless cars. Truck crashes are increasing in number in the US, with over 100,000 people injured each year, and over 4,000 killed. Trucks follow established routes. They don’t go off-road. This makes them easier to bring into an automated model, even with current technology. They travel long distances and the fatigue and inattention effects upon human drivers kill people. Automating truck fleets will save over a million lives in the US alone in the first decade, reducing fleet costs due to insurance payouts, lost time, and all of those things.
We have a long way to go before we have the kind of vehicles that can replace what we have but let’s focus on what is important. Getting a reliable sensory rig that works better than a human and can brake faster is the immediate point at which any form of adoption will start saving lives. Then costs come down. Then adoption goes up. Then millions of people live happier lives because they weren’t killed or maimed by cars. That’s being fair. That’s being honest. That will lead to good.
Your driverless car doesn’t need to be prepared to kill you in order to save lives.

And you may even still be able to get your kicks.
Education is not defined by a building
Posted: January 24, 2016 Filed under: Education, Opinion | Tags: advocacy, aesthetics, art, authenticity, beauty, design, dewey, education, educational problem, educational research, ethics, good, higher education, in the student's head, learning, reflection, resources, teaching, teaching approaches, thinking, truth Leave a commentI drew up a picture to show how many people appear to think about art. Now this is not to say that this is my thinking on art but you only have to go to galleries for a while to quickly pick up the sotto voce (oh, and loud) discussions about what constitutes art. Once we move beyond representative art (art that looks like real things), it can become harder for people to identify what they consider to be art.

This is crude and bordering on satirical. Read the text before you have a go at me over privilege and cultural capital.
I drew up this diagram in response to reading early passages from Dewey’s “Art as Experience”:
“An instructive history of modern art could be written in terms of the formation of the distinctively modern institutions of museum and exhibition gallery. (p8)
[…]
The growth of capitalism has been a powerful influence in the development of the museum as the proper home for works of art, and in the promotion of the idea that they are apart from the common life. (p8)
[…]
Why is there repulsion when the high achievements of fine art are brought into connection with common life, the life that we share with all living creatures?” (p20)
Dewey’s thinking is that we have moved from a time when art was deeply integrated into everyday life to a point where we have corralled “worthy” art into buildings called art galleries and museums, generally in response to nationalistic or capitalistic drivers, in order to construct an artefact that indicates how cultured and awesome we are. But, by doing this, we force a definition that something is art if it’s the kind of thing you’d see in an art gallery. We take art out of life, making valuable relics of old oil jars and assigning insane values to collections of oil on canvas that please the eye, and by doing so we demand that ‘high art’ cannot be part of most people’s lives.
But the gallery container is not enough to define art. We know that many people resist modernism (and post-modernism) almost reflexively, whether it’s abstract, neo-primitivist, pop, or simply that the viewer doesn’t feel convinced that they are seeing art. Thus, in the diagram above, real art is found in galleries but there are many things found in galleries that are not art. To steal an often overheard quote: “my kids could do that”. (I’m very interested in the work of both Rothko and Malevich so I hear this a lot.)
But let’s resist the urge to condemn people because, after we’ve wrapped art up in a bow and placed it on a pedestal, their natural interpretation of what they perceive, combined with what they already know, can lead them to a conclusion that someone must be playing a joke on them. Aesthetic sensibilities are inherently subjective and evolve over time, in response to exposure, development of depth of knowledge, and opportunity. The more we accumulate of these guiding experiences, the more likely we are to develop the cultural capital that would allow us to stand in any art gallery in the world and perceive the art, mediated by our own rich experiences.
Cultural capital is a term used to describe the assets that we have that aren’t money, in its many forms, but can still contribute to social mobility and perception of class. I wrote a long piece on it and perception here, if you’re interested. Dewey, working in the 1930s, was reacting to the institutionalisation of art and was able to observe people who were attempting to build a cultural reputation, through the purchase of ‘art that is recognised as art’, as part of their attempts to construct a new class identity. Too often, when people who are grounded in art history and knowledge look at people who can’t recognise ‘art that is accepted as art by artists’ there is an aspect of sneering, which is both unpleasant and counter-productive. However, such unpleasantness is easily balanced by those people who stand firm in artistic ignorance and, rather than quietly ignoring things that they don’t like, demand that it cannot be art and loudly deride what they see in order to challenge everyone around them to accept the art of an earlier time as the only art that there is.
Neither of these approaches is productive. Neither support the aesthetics of real discussion, nor are they honest in intent beyond a judgmental and dismissive approach. Not beautiful. Not true. Doesn’t achieve anything useful. Not good.
If this argument is seeming familiar, we can easily apply it to education because we have, for the most part, defined many things in terms of the institutions in which we find them. Everyone else who stands up and talks at people over Power Point slides for forty minutes is probably giving a presentation. Magically, when I do it in a lecture theatre at a University, I’m giving a lecture and now it has amazing educational powers! I once gave one of my lectures as a presentation and it was, to my amusement, labelled as a presentation without any suggestion of still being a lecture. When I am a famous professor, my lectures will probably start to transform into keynotes and masterclasses.
I would be recognised as an educator, despite having no teaching qualifications, primarily because I give presentations inside the designated educational box that is a University. The converse of this is that “university education” cannot be given outside of a University, which leaves every newcomer to tertiary education, whether face-to-face or on-line, with a definitional crisis that cannot be resolved in their favour. We already know that home-schooling, while highly variable in quality and intention, is a necessity in some places where the existing educational options are lacking, is often not taken seriously by the establishment. Even if the person teaching is a qualified teacher and the curriculum taught is an approved one, the words “home schooling” construct tension with our assumption that schooling must take place in boxes labelled as schools.
What is art? We need a better definition than “things I find in art galleries that I recognise as art” because there is far too much assumption in there, too much infrastructure required and there is not enough honesty about what art is. Some of the works of art we admire today were considered to be crimes against conventional art in their day! Let me put this in context. I am an artist and I have, with 1% of the talent, sold as many works as Van Gogh did in his lifetime (one). Van Gogh’s work was simply rubbish to most people who looked at it then.
And yet now he is a genius.
What is education? We need a better definition than “things that happen in schools and universities that fit my pre-conceptions of what education should look like.” We need to know so that we can recognise, learn, develop and improve education wherever we find it. The world population will peak at around 10 billion people. We will not have schools for all of them. We don’t have schools for everyone now. We may never have the infrastructure we need for this and we’re going need a better definition if we want to bring real, valuable and useful education to everyone. We define in order to clarify, to guide, and to tell us what we need to do next.
It’s only five minutes late!
Posted: January 23, 2016 Filed under: Education | Tags: aesthetics, beauty, education, educational problem, educational research, higher education, in the student's head, learning, principles of design, resources, student perspective, teaching, teaching approaches, thinking, time, time management Leave a comment
This is an indicator of the passage of time, not an educational mechanism.
I’ve been talking about why late penalties are not only not useful but they don’t work, yet I keep talking about getting work in on time and tying it to realistic resource allocation. Does this mean I’m really using late penalties?
No, but let me explain why, starting from the underlying principle of fairness that is an aesthetic pillar of good education. One part of this is that the actions of one student should not unduly affect the learning journey of another student. That includes evaluation (and associated marks).
This is the same principle that makes me reject curve grading. It makes no sense to me that someone else’s work is judged in the context of another, when we have so little real information with which we could establish any form of equivalence of human experience and available capacity.
I don’t want to create a market economy for knowledge, where we devaluate successful demonstrations of knowledge and skill for reasons that have nothing to do with learning. Curve grading devalues knowledge. Time penalties devalue knowledge.
I do have to deal with resource constraints, in that I often have (some) deadlines that are administrative necessities, such as degree awards and things like this. I have limited human resources, both personally and professionally.
Given that I do not have unconstrained resources, the fairness principle naturally extends to say that individual students should not consume resources to the detriment of others. I know that I have a limited amount of human evaluation time, therefore I have to treat this as a constrained resource. My E1 and E2 evaluations resources must be, to a degree at least, protected to ensure the best outcome for the most students. (We can factor equity into this, and should, but this stops this from being a simple linear equivalence and makes the terms more complex than they need to be for explanation, so I’ll continue this discussion as if we’re discussing equality.)
You’ve noticed that the E3 and E4 evaluation systems are pretty much always available to students. That’s deliberate. If we can automate something, we can scale it. No student is depriving another of timely evaluation and so there’s no limitation of access to E3 and E4, unless it’s too late for it to be of use.
If we ask students to get their work in at time X, it should be on the expectation that we are ready to leap into action at second X+(prep time), or that the students should be engaged in some other worthwhile activity from X+1, because otherwise we have made up a nonsense figure. In order to be fair, we should release all of our evaluations back at the same time, to avoid accidental advantages because of the order in which things were marked. (We may wish to vary this for time banking but we’ll come back to this later.) As many things are marked in surname or student number order, the only way to ensure that we don’t accidentally keep granting an advantage is to release everything at the same time.
Remember, our whole scheme is predicated on the assumption that we have designed and planned for how long it will take to go through the work and provide feedback in time for modification before another submission. When X+(prep time) comes, we should know, roughly to the hour or day, at worst, when this will be done.
If a student hands up fifteen minutes late, they have most likely missed the preparation phase. If we delay our process to include this student, then we will delay feedback to everyone. Here is a genuine motivation for students to submit on time: they will receive rich and detailed feedback as soon as it is ready. Students who hand up late will be assessed in the next round.
That’s how the real world actually works. No-one gives you half marks for something that you do a day late. It’s either accepted or not and, often, you go to the back of the queue. When you miss the bus, you don’t get 50% of the bus. You just have to wait for the next opportunity and, most of the time, there is another bus. Being late once rarely leaves you stranded without apparent hope – unlucky Martian visitors aside.
But there’s more to this. When we have finished with the first group, we can immediately release detailed feedback on what we were expecting to see, providing the best results to students and, from that point on, anyone who submits would have the benefit of information that the first group didn’t have before their initial submission. Rather than make the first group think that they should have waited (and we know students do), we give them the best possible outcome for organising their time.
The next submission deadline is done by everyone with the knowledge gained from the first pass but people who didn’t contribute to it can’t immediately use it for their own benefit. So there’s no free-riding.
There is, of course, a tricky period between the submission deadline and the release, where we could say “Well, they didn’t see the feedback” and accept the work but that’s when we think about the message we want to send. We would prefer students to improve their time management and one part of this is to have genuine outcomes from necessary deadlines.
If we let students keep handing in later and later, we will eventually end up having these late submissions running into our requirement to give feedback. But, more importantly, we will say “You shouldn’t have bothered” to those students who did hand up on time. When you say something like this, students will learn and they will change their behaviour. We should never reinforce behaviour that is the opposite of what we consider to be valuable.
Fairness is a core aesthetic of education. Authentic time management needs to reflect the reality of lost opportunity, rather than diminished recognition of good work in some numerical reduction. Our beauty argument is clear: we can be firm on certain deadlines and remove certain tasks from consideration and it will be a better approach and be more likely to have positive outcomes than an arbitrary reduction scheme already in use.
First year course evaluation scheme
Posted: January 22, 2016 Filed under: Education, Opinion | Tags: advocacy, aesthetics, assessment, authenticity, beauty, design, education, educational problem, ethics, higher education, learning, reflection, resources, student perspective, teaching, teaching approaches, time management 2 CommentsIn my earlier post, I wrote:
Even where we are using mechanical or scripted human [evaluators], the hand of the designer is still firmly on the tiller and it is that control that allows us to take a less active role in direct evaluation, while still achieving our goals.
and I said I’d discuss how we could scale up the evaluation scheme to a large first year class. Finally, thank you for your patience, here it is.
The first thing we need to acknowledge is that most first-year/freshman classes are not overly complex nor heavily abstract. We know that we want to work concrete to abstract, simple to complex, as we build knowledge, taking into account how students learn, their developmental stages and the mechanics of human cognition. We want to focus on difficult concepts that students struggle with, to ensure that they really understand something before we go on.
In many courses and disciplines, the skills and knowledge we wish to impart are fundamental and transformative, but really quite straight-forward to evaluate. What this means, based on what I’ve already laid out, is that my role as a designer is going to be crucial in identifying how we teach and evaluate the learning of concepts, but the assessment or evaluation probably doesn’t require my depth of expert knowledge.
The model I put up previously now looks like this:
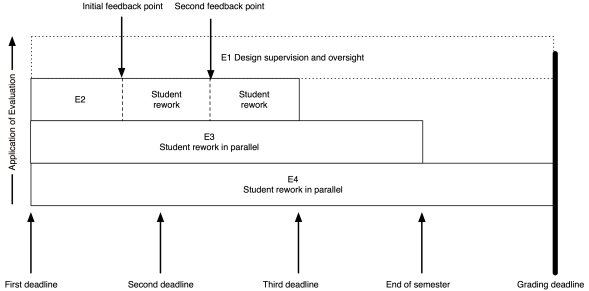
My role (as the notional E1) has moved entirely to design and oversight, which includes developing the E3 and E4 tests and training the next tier down, if they aren’t me.
As an example, I’ve put in two feedback points, suitable for some sort of worked output in response to an assignment. Remember that the E2 evaluation is scripted (or based on rubrics) yet provides human nuance and insight, with personalised feedback. That initial feedback point could be peer-based evaluation, group discussion and demonstration, or whatever you like. The key here is that the evaluation clearly indicates to the student how they are travelling; it’s never just “8/10 Good”. If this is a first year course then we can capture much of the required feedback with trained casuals and the underlying automated systems, or by training our students on exemplars to be able to evaluate each other’s work, at least to a degree.
The same pattern as before lies underneath: meaningful timing with real implications. To get access to human evaluation, that work has to go in by a certain date, to allow everyone involved to allow enough time to perform the task. Let’s say the first feedback is a peer-assessment. Students can be trained on exemplars, with immediate feedback through many on-line and electronic systems, and then look at each other’s submissions. But, at time X, they know exactly how much work they have to do and are not delayed because another student handed up late. After this pass, they rework and perhaps the next point is a trained casual tutor, looking over the work again to see how well they’ve handled the evaluation.
There could be more rework and review points. There could be less. The key here is that any submission deadline is only required because I need to allocate enough people to the task and keep the number of tasks to allocate, per person, at a sensible threshold.
Beautiful evaluation is symmetrically beautiful. I don’t overload the students or lie to them about the necessity of deadlines but, at the same time, I don’t overload my human evaluators by forcing them to do things when they don’t have enough time to do it properly.
As for them, so for us.
Throughout this process, the E1 (supervising evaluator) is seeing all of the information on what’s happening and can choose to intervene. At this scale, if E1 was also involved in evaluation, intervention would be likely last-minute and only in dire emergency. Early intervention depends upon early identification of problems and sufficient resources to be able to act. Your best agent of intervention is probably the person who has the whole vision of the course, assisted by other human evaluators. This scheme gives the designer the freedom to have that vision and allows you to plan for how many other people you need to help you.
In terms of peer assessment, we know that we can build student communities and that students can appreciate each other’s value in a way that enhances their perceptions of the course and keeps them around for longer. This can be part of our design. For example, we can ask the E2 evaluators to carry out simple community-focused activities in classes as part of the overall learning preparation and, once students are talking, get them used to the idea of discussing ideas rather than having dualist confrontations. This then leads into support for peer evaluation, with the likelihood of better results.
Some of you will be saying “But this is unrealistic, I’ll never get those resources.” Then, in all likelihood, you are going to have to sacrifice something: number of evaluations, depth of feedback, overall design or speed of intervention.
You are a finite resource. Killing you with work is not beautiful. I’m writing all of this to speak to everyone in the community, to get them thinking about the ugliness of overwork, the evil nature of demanding someone have no other life, the inherent deceit in pretending that this is, in any way, a good system.
We start by changing our minds, then we change the world.
$6.9M Federal Funding for CSER Digital Technologies @cseradelaide @UniofAdelaide @birmo @cpyne @sallyannw
Posted: January 21, 2016 Filed under: Education | Tags: advocacy, community, cser, cser digital technologies, digital technologies, education, educational problem, educational research, ethics, Google, higher education, learning, outreach, resources, STEM, teaching, teaching approaches, tools Leave a commentOur research group, the Computer Science Education Research Group, has been working to support teachers involved in digital technologies for some time. The initial project was a collaboration between Google and the University of Adelaide, with amazing work from Sally-Ann Williams of Google to support us, to produce a support course that was free, open and recognised as professional development for teachers who were coming to terms with the new Digital Technologies (draft) curriculum. Today we are amazed and proud to announce $6.9 million dollars in Federal Funding over the next four years to take this project … well … just about everywhere.
You can read about what we’ve been doing here
I’ll now share Katrina’s message, slightly edited, to the rest of the school.
Today we hosted a visit from Ministers Birmingham and Pyne to announce a new funding agreement to support a national support program for Australian teachers within the Digital Technologies space.
Ministers Birmingham and Pyne confirmed that the Australian Government is providing $6.9 million over four years to the Computer Science Education Research Group at the University of Adelaide to support the roll out, on a national basis, of the teacher professional learning Massive Open Online Course (MOOC) supporting Australian primary and junior secondary teachers in developing skills in implementing the Australian Curriculum: Digital Technologies.
The CSER MOOC program provides free professional development for Australian teachers in the area of Computer Science, and supports research into the learning and teaching of Computer Science in the K-12 space. As part of this new program, we will be able to support teachers in disadvantaged schools and Indigenous schools across Australia in accessing the CSER MOOCs. We will also be able to establish a national lending library program to provide access to the most recent and best digital technologies education equipment to every school.
The Ministers, along with our Executive Dean and the Vice-Chancellor accompanied us to visit a coding outreach event for children run this morning as part of the University’s Bright Sparks STEM holiday program.
Here’s the ministerial announcement.

Senator Birmingham, Minister Pyne, Professor Bebbington (VC of the University Adelaide) and A/Prof Katrina Falkner with one of the Bright Spark participants.
Most assessment’s ugly
Posted: January 21, 2016 Filed under: Education, Opinion | Tags: aesthetics, beauty, Bloom, education, higher education, learning, teaching, thinking, time management 3 CommentsEd challenged me: distill my thinking! In three words? Ok, Ed, fine: most assessment’s ugly.
Why is that? (Three word answers. Yes, I’m cheating.)
- It’s not authentic.
- There’s little design.
- Wrong Bloom’s level.
- Weak links forward.
- Weak links backward.
- Testing not evaluating.
- Marks not feedback.
- Not learning focused.
- Deadlines are rubbish.
- Tradition dominates innovation.
How was that?

And I’m out.
The hand of an expert is visible in design
Posted: January 20, 2016 Filed under: Education | Tags: advocacy, aesthetics, arts and crafts, authenticity, beauty, community, design, dewey, education, educational problem, educational research, ethics, good, higher education, jeffrey petts, learning, morris, reflection, resources, student perspective, teaching, teaching approaches, thinking, time, time management, tools, truth 1 CommentIn yesterday’s post, I laid out an evaluation scheme that allocated the work of evaluation based on the way that we tend to teach and the availability, and expertise, of those who will be evaluating the work. My “top” (arbitrary word) tier of evaluators, the E1s, were the teaching staff who had the subject matter expertise and the pedagogical knowledge to create all of the other evaluation materials. Despite the production of all of these materials and designs already being time-consuming, in many cases we push all evaluation to this person as well. Teachers around the world know exactly what I’m talking about here.
Our problem is time. We move through it, tick after tick, in one direction and we can neither go backwards nor decrease the number of seconds it takes to perform what has to take a minute. If we ask educators to undertake good learning design, have engaging and interesting assignments, work on assessment levels well up in the taxonomies and we then ask them to spend day after day standing in front of a class and add marking on top?
Forget it. We know that we are going to sacrifice the number of tasks, the quality of the tasks or our own quality of life. (I’ve written a lot about time before, you can search my blog for time or read this, which is a good summary.) If our design was good, then sacrificing the number of tasks or their quality is going to compromise our design. If we stop getting sleep or seeing our families, our work is going to suffer and now our design is compromised by our inability to perform to our actual level of expertise!
When Henry Ford refused to work his assembly line workers beyond 40 hours because of the increased costs of mistakes in what were simple, mechanical, tasks, why do we keep insisting that complex, delicate, fragile and overwhelmingly cognitive activities benefit from us being tired, caffeine-propped, short-tempered zombies?
We’re not being honest. And thus we are not meeting our requirement for truth. A design that gets mangled for operational reasons without good redesign won’t achieve our outcomes. That’s not going to achieve our results – so that’s not good. But what of beauty?

William Morris: Snakeshead Textile
What are the aesthetics of good work? In Petts’ essay on the Arts and Crafts movement, he speaks of William Morris, Dewey and Marx (it’s a delightful essay) and ties the notion of good work to work that is authentic, where such work has aesthetic consequences (unsurprisingly given that we were aiming for beauty), and that good (beautiful) work can be the result of human design if not directly the human hand. Petts makes an interesting statement, which I’m not sure Morris would let pass un-challenged. (But, of course, I like it.)
It is not only the work of the human hand that is visible in art but of human design. In beautiful machine-made objects we still can see the work of the “abstract artist”: such an individual controls his labor and tools as much as the handicraftsman beloved of Ruskin.
Jeffrey Petts, Good Work and Aesthetic Education: William Morris, the Arts and Crafts Movement, and Beyond, The Journal of Aesthetic Education, Vol. 42, No. 1 (Spring, 2008), page 36
Petts notes that it is interesting that Dewey’s own reflection on art does not acknowledge Morris especially when the Arts and Crafts’ focus on authenticity, necessary work and a dedication to vision seems to be a very suitable framework. As well, the Arts and Crafts movement focused on the rejection of the industrial and a return to traditional crafting techniques, including social reform, which should have resonated deeply with Dewey and his peers in the Pragmatists. However, Morris’ contribution as a Pragmatist aesthetic philosopher does not seem to be recognised and, to me, this speaks volumes of the unnecessary separation between cloister and loom, when theory can live in the pragmatic world and forms of practice can be well integrated into the notional abstract. (Through an Arts and Crafts lens, I would argue that there is are large differences between industrialised education and the provision, support and development of education using the advantages of technology but that is, very much, another long series of posts, involving both David Bowie and Gary Numan.)
But here is beauty. The educational designer who carries out good design and manages to hold on to enough of her time resources to execute the design well is more aesthetically pleasing in terms of any notion of creative good works. By going through a development process to stage evaluations, based on our assessment and learning environment plans, we have created “made objects” that reflect our intention and, if authentic, then they must be beautiful.
We now have a strong motivating factor to consider both the often over-looked design role of the educator as well as the (easier to perceive) roles of evaluation and intervention.

I’ve revisited the diagram from yesterday’s post to show the different roles during the execution of the course. Now you can clearly see that the course lecturer maintains involvement and, from our discussion above, is still actively contributing to the overall beauty of the course and, we would hope, it’s success as a learning activity. What I haven’t shown is the role of the E1 as designer prior to the course itself – but that’s another post.
Even where we are using mechanical or scripted human markers, the hand of the designer is still firmly on the tiller and it is that control that allows us to take a less active role in direct evaluation, while still achieving our goals.
Do I need to personally look at each of the many works all of my first years produce? In our biggest years, we had over 400 students! It is beyond the scale of one person and, much as I’d love to have 40 expert academics for that course, a surplus of E1 teaching staff is unlikely anytime soon. However, if I design the course correctly and I continue to monitor and evaluate the course, then the monster of scale that I have can be defeated, if I can make a successful argument that the E2 to E4 marker tiers are going to provide the levels of feedback, encouragement and detailed evaluation that are required at these large-scale years.
Tomorrow, we look at the details of this as it applies to a first-year programming course in the Processing language, using a media computation approach.
Four-tier assessment
Posted: January 19, 2016 Filed under: Education, Opinion | Tags: aesthetics, assessment, authenticity, beauty, community, design, dewey, education, educational problem, educational research, ethics, higher education, in the student's head, intrinsic motivation, john c. dewey, learning, motivation, resources, teaching, teaching approaches, time, time management, tools 1 CommentWe’ve looked at a classification of evaluators that matches our understanding of the complexity of the assessment tasks we could ask students to perform. If we want to look at this from an aesthetic framing then, as Dewey notes:
“By common consent, the Parthenon is a great work of art. Yet it has aesthetic standing only as the work becomes an experience for a human being.”
John Dewey, Art as Experience, Chapter 1, The Live Creature.
Having a classification of evaluators cannot be appreciated aesthetically unless we provide a way for it to be experienced. Our aesthetic framing demands an implementation that makes use of such an evaluator classification, applies to a problem where we can apply a pedagogical lens and then, finally, we can start to ask how aesthetically pleasing it is.
And this is what brings us to beauty.
A systematic allocation of tasks to these different evaluators should provide valid and reliable marking, assuming we’ve carried out our design phase correctly. But what about fairness, motivation or relevancy, the three points that we did not address previously? To be able to satisfy these aesthetic constraints, and to confirm the others, it now matters how we handle these evaluation phases because it’s not enough to be aware that some things are going to need different approaches, we have to create a learning environment to provide fairness, motivation and relevancy.
I’ve already argued that arbitrary deadlines are unfair, that extrinsic motivational factors are grossly inferior to those found within, and, in even earlier articles, that we too insist on the relevancy of the measurements that we have, rather than designing for relevancy and insisting on the measurements that we need.
To achieve all of this and to provide a framework that we can use to develop a sense of aesthetic satisfaction (and hence beauty), here is a brief description of a four-tier, penalty free, assessment.
Let’s say that, as part of our course design, we develop an assessment item, A1, that is one of the elements to provide evaluation coverage of one of the knowledge areas. (Thus, we can assume that A1 is not required to be achieved by itself to show mastery but I will come back to this in a later post.)
Recall that the marking groups are: E1, expert human markers; E2, trained or guided human markers; E3, complex automated marking; and E4, simple and mechanical automated marking.
A1 has four, inbuilt, course deadlines but rather than these being arbitrary reductions of mark, these reflect the availability of evaluation resource, a real limitation as we’ve already discussed. When the teacher sets these courses up, she develops an evaluation scheme for the most advanced aspects (E1, which is her in this case), an evaluation scheme that could be used by other markers or her (E2), an E3 acceptance test suite and some E4 tests for simplicity. She matches the aspects of the assignment to these evaluation groups, building from simple to complex, concrete to abstract, definite to ambiguous.
The overall assessment of work consists of the evaluation of four separate areas, associated with each of the evaluators. Individual components of the assessment build up towards the most complex but, for example, a student should usually have had to complete at least some of E4-evaluated work to be able to attempt E3.
Here’s a diagram of the overall pattern for evaluation and assessment.

The first deadline for the assignment is where all evaluation is available. If students provide their work by this time, the E1 will look at the work, after executing the automated mechanisms, first E4 then E3, and applying the E2 rubrics. If the student has actually answered some E1-level items, then the “top tier” E1 evaluator will look at that work and evaluate it. Regardless of whether there is E1 work or not, human-written feedback from the lecturer on everything will be provided if students get their work in at that point. This includes things that would be of help for all other levels. This is the richest form of feedback, it is the most useful to the students and, if we are going to use measures of performance, this is the point at which the most opportunities to demonstrate performance can occur.
This feedback will be provided in enough time that the students can modify their work to meet the next deadline, which is the availability of E2 markers. Now TAs or casuals are marking instead or the lecturer is now doing easier evaluation from a simpler rubric. These human markers still start by running the automated scripts, E4 then E3, to make sure that they can mark something in E2. They also provide feedback on everything in E2 to E4, sent out in time for students to make changes for the next deadline.
Now note carefully what’s going on here. Students will get useful feedback, which is great, but because we have these staggered deadlines, we can pass on important messages as we identify problems. If the class is struggling with key complex or more abstract elements, harder to fix and requiring more thought, we know about it quickly because we have front-loaded our labour.
Once we move down to the fully automated systems, we’re losing opportunities for rich and human feedback to students who have not yet submitted. However, we have a list of students who haven’t submitted, which is where we can allocate human labour, and we can encourage them to get work in, in time for the E3 “complicated” script. This E3 marking script remains open for the rest of the semester, to encourage students to do the work sometime ahead of the exam. At this point, the discretionary allocation of labour for feedback is possible, because the lecturer has done most of the hard work in E1 and E2 and should, with any luck, have far fewer evaluation activities for this particular assignment. (Other things may intrude, including other assignments, but we have time bounds on this one, which is better than we often have!)
Finally, at the end of the teaching time (in our parlance, a semester’s teaching will end then we will move to exams), we move the assessment to E4 marking only, giving students the ability (if required) to test their work to meet any “minimum performance” requirements you may have for their eligibility to sit the exam. Eventually, the requirement to enter a record of student performance in this course forces us to declare the assessment item closed.
This is totally transparent and it’s based on real resource limitations. Our restrictions have been put in place to improve student feedback opportunities and give them more guidance. We have also improved our own ability to predict our workload and to guide our resource requests, as well as allowing us to reuse some elements of automated scripts between assignments, without forcing us to regurgitate entire assignments. These deadlines are not arbitrary. They are not punitive. We have improved feedback and provided supportive approaches to encourage more work on assignments. We are able to get better insight into what our students are achieving, against our design, in a timely fashion. We can now see fairness, intrinsic motivation and relevance.
I’m not saying this is beautiful yet (I think I have more to prove to you) but I think this is much closer than many solutions that we are currently using. It’s not hiding anything, so it’s true. It does many things we know are great for students so it looks pretty good.
Tomorrow, we’ll look at whether such a complicated system is necessary for early years and, spoilers, I’ll explain a system for first year that uses peer assessment to provide a similar, but easier to scale, solution.
Joi Ito on Now-ists
Posted: January 18, 2016 Filed under: Education, Opinion | Tags: advocacy, blogging, community, design, education, educational problem, educational research, ethics, futurist, higher education, joi ito, learning, now-ist, resources, student perspective, teaching, teaching approaches, thinking Leave a commentThis is a great TED talk. Joi Ito, director of the MIT media lab, talks about the changes that technological innovation have made to the ways that we can work on problems and work together.
I don’t agree with everything, especially the pejorative cast on education, but I totally agree that the way that we construct learning environments has to take into the way that our students will work, rather than trying to prepare them for the world that we (or our parents) worked in. Pretending that many of our students will have to construct simple things by hand, when that is what we were doing fifty years ago, takes up time that we could be using for more authentic and advanced approaches that cover the same material. Some foundations are necessary. Some are tradition. Being a now-ist forces us to question which is which and then act on that knowledge.
Your students will be able to run enterprises from their back rooms that used to require the resources of multinational companies. It’s time to work out what they actually need to get from us and, once we know that, deliver it. There is a place for higher education but it may not be the one that we currently have.
A lot of what I talk about on this blog looks as if I’m being progressive but, really, I’m telling you what we already know to be true right now. And what we have known to be true for decades, if not centuries. I’m not a futurist, at all. I’m a now-ist with a good knowledge of history who sees a very bleak future if we don’t get better at education.
(Side note: yes, this is over twelve minutes long. Watch our around the three minute mark for someone reading documents on an iPad up the back, rather than watching him talk. I think this is a little long and staged, when it could have been tighter, but that’s the TED format for you. You know what you’re getting into and, because it’s not being formally evaluated, it doesn’t matter as much if you recall high-level rather than detail.)
Four tiers of evaluators
Posted: January 18, 2016 Filed under: Education, Opinion | Tags: aesthetics, beauty, community, design, education, educational problem, educational research, ethics, feedback, higher education, learning, marking, resources, student perspective, teaching, teaching approaches, thinking, tools 1 CommentWe know that we can, and do, assess different levels of skill and knowledge. We know that we can, and do, often resort to testing memorisation, simple understanding and, sometimes, the application of the knowledge that we teach. We also know that the best evaluation of work tends to come from the teachers who know the most about the course and have the most experience, but we also know that these teachers have many demands on their time.
The principles of good assessment can be argued but we can probably agree upon a set much like this:
- Valid, based on the content. We should be evaluating things that we’ve taught.
- Reliable, in that our evaluations are consistent and return similar results for different evaluators, that re-evaluating would give the same result, that we’re not unintentionally raising or lowering difficulty.
- Fair.
- Motivating, in that we know how much influence feedback and encouragement have on students, so we should be maximising the motivation and, we hope, this should drive engagement.
- Finally, we want our assessment to be as relevant to us, in terms of being able to use the knowledge gained to improve or modify our courses, as it is to our student. Better things should come from having run this assessment.
Notice that nothing here says “We have to mark or give a grade”, yet we can all agree on these principles, and any scheme that adheres to them, as being a good set of characteristics to build upon. Let me label these as aesthetics of assessment, now let’s see if I can make something beautiful. Let me put together my shopping list.
- Feedback is essential. We can see that. Let’s have lots of feedback and let’s put it in places where it can be the most help.
- Contextual relevance is essential. We’re going to need good design and work out what we want to evaluate and then make sure we locate our assessment in the right place.
- We want to encourage students. This means focusing on intrinsics and support, as well as well-articulated pathways to improvement.
- We want to be fair and honest.
- We don’t want to overload either the students or ourselves.
- We want to allow enough time for reliable and fair evaluation of the work.
What are the resources we have?
- Course syllabus
- Course timetable
- The teacher’s available time
- TA or casual evaluation time, if available
- Student time (for group work or individual work, including peer review)
- Rubrics for evaluation.
- Computerised/automated evaluation systems, to varying degree.
Wait, am I suggesting automated marking belongs in a beautiful marking system? Why, yes, I think it has a place, if we are going to look at those things we can measure mechanistically. Checking to see if someone has ticked the right box for a Bloom’s “remembering” level activity? Machine task. Checking to see if an essay has a lot of syntax or grammatical errors? Machine task. But we can build on that. We can use human markers and machine markers, in conjunction, to the best of their strengths and to overcome each other’s weaknesses.

We’ve come a long, in terms of machine-based evaluation. It doesn’t have to be steam-driven.
If we think about it, we really have four separate tiers of evaluators to draw upon, who have different levels of ability. These are:
- E1: The course designers and subject matter experts who have a deep understanding of the course and could, possibly with training, evaluate work and provide rich feedback.
- E2: Human evaluators who have received training or are following a rubric provided by the E1 evaluators. They are still human-level reasoners but are constrained in terms of breadth of interpretation. (It’s worth noting that peer assessment could fit in here, as well.)
- E3: High-level machine evaluation includes machine-based evaluation of work, which could include structural, sentiment or topic analysis, as well as running complicated acceptance tests that look for specific results, coverage of topics or, in the case of programming tasks, certain output in response to given input. The E3 evaluation mechanisms will require some work to set up but can provide evaluation of large classes in hours, rather than days.
- E4: Low-level machine evaluation, checking for conformity in terms of length of assignment, names, type of work submitted, plagiarism detection. In the case of programming assignments, E4 would check that the filenames were correct, that the code compiled and also may run some very basic acceptance tests. E4 evaluation mechanisms should be quick to set up and very quick to execute.
This separation clearly shows us a graded increase of expertise that corresponds to an increase of time spent and, unfortunately, a decrease in time available. E4 evaluation is very easy to set up and carry out but it’s not fantastic for detailed feedback or higher Bloom’s level. Yet we have an almost infinite amount of this marking time available. E1 markers will (we hope) give the best feedback but they take a long time and this immediately reduces the amount of time to be spent on other things. How do we handle this and select the best mix?
While we’re thinking about that, let’s see if we are meeting the aesthetics.
- Valid? Yes. We’ve looked at our design (we appear to have a design!) and we’ve specifically set up evaluation into different areas while thinking about outcomes, levels and areas that we care about.
- Reliable? Looks like it. E3 and E4 are automated and E2 has a defined marking rubric. E1 should also have guidelines but, if we’ve done our work properly in design, the majority of marks, if not all of them, are going to be assigned reliably.
- Fair? We’ve got multiple stages of evaluation but we haven’t yet said how we’re going to use this so we don’t have this one yet.
- Motivating? Hmm, we have the potential for a lot of feedback but we haven’t said how we’re using that, either. Don’t have this one either.
- Relevant to us and the students. No, for the same reasons as 3 and 4, we haven’t yet shown how this can be useful to us.
It looks like we’re half-way there. Tomorrow, we finish the job.
