
What do we want? Passing average or competency always?
Posted: February 4, 2016 Filed under: Education | Tags: acsw2016, advocacy, aesthetics, authenticity, community, competency, competency-based assessment, design, education, educational problem, educational research, higher education, learning, statistics, teaching, teaching approaches, thinking, tools Leave a commentI’m at the Australasian Computer Science Week at the moment and I’m dividing my time between attending amazing talks, asking difficult questions, catching up with friends and colleagues and doing my own usual work in the cracks. I’ve talked to a lot of people about my ideas on assessment (and beauty) and, as always, the responses have been thoughtful, challenging and helpful.
I think I know what the basis of my problem with assessment is, taking into account all of the roles that it can take. In an earlier post, I discussed Wolff’s classification of assessment tasks into criticism, evaluation and ranking. I’ve also made earlier (grumpy) notes about ranking systems and their arbitrary nature. One of the interesting talks I attended yesterday talked about the fragility and questionable accuracy of post-University exit surveys, which are used extensively in formal and informal rankings of Universities, yet don’t actually seem to meet many of the statistical or sensible guidelines for efficacy we already have.
But let’s put aside ranking for a moment and return to criticism and evaluation. I’ve already argued (successfully I hope) for a separation of feedback and grades from the criticism perspective. While they are often tied to each other, they can be separated and the feedback can still be useful. Now let’s focus on evaluation.
Remind me why we’re evaluating our students? Well, we’re looking to see if they can perform the task, apply the skill or knowledge, and reach some defined standard. So we’re evaluating our students to guide their learning. We’re also evaluating our students to indirectly measure the efficacy of our learning environment and us as educators. (Otherwise, why is it that there are ‘triggers’ in grading patterns to bring more scrutiny on a course if everyone fails?) We’re also, often accidentally, carrying out an assessment of the innate success of each class and socio-economic grouping present in our class, among other things, but let’s drill down to evaluating the student and evaluating the learning environment. Time for another thought experiment.
Thought Experiment 2
There are twenty tasks aligned with a particularly learning outcome. It’s an important task and we evaluate it in different ways but the core knowledge or skill is the same. Each of these tasks can receive a ‘grade’ of 0, 0.5 or 1. 0 means unsuccessful, 0.5 is acceptable, 1 is excellent. Student A attempts all tasks and is acceptable in 19, unsuccessful in 1. Student B attempts the first 10 tasks, receives excellent in all of them and stops. Student C sets up a pattern of excellent,unsuccessful, excellent, unsuccessful.. and so on to receive 10 “Excellent”s and 10 “unsuccessful”s. When we form an aggregate grade, A receives 47.5%, B receives 50% and C also receives 50%. Which of these students is the most likely to successfully complete the task?
This framing allows us to look at the evaluation of the student in a meaningful way. “Who will pass the course?” is not the question we should be asking, it’s “Who will be able to reliably demonstrate mastery of the skills or knowledge that we are imparting.” Passing the course has a naturally discrete attention focus: focus on n assignments and m exams and pass. Continual demonstration of mastery is a different goal. This framing also allows us to examine the learning environment because, without looking at the design, I can’t tell you if B and C’s behaviour is problematic or not.

A has undertaken the most tasks to an acceptable level but an artefact of grading (or bad luck) has dropped the mark below 50%, which would be a fail (aggregate less than acceptable) in many systems. B has performed excellently on every task attempted but, being aware of the marking scheme, optimising and strategic behaviour allows this student to walk away. (Many students who perform at this level wouldn’t, I’m aware, but we’re looking at the implications of this.) C has a troublesome pattern that provides the same outcome as B but with half the success rate.
Before we answer the original question (which is most likely to succeed), I can nominate C as the most likely to struggle because C has the most “unsuccessful”s. From a simple probabilistic argument, 10/20 success is worse than 19/20. It’s a bit tricker comparing 10/10 and 10/20 (because of confidence intervals) but 10/20 has an Adjusted Wald range of +/- 20% and 10/10 is -14%, so the highest possible ‘real’ measure for C is 14/20 and the lowest possible ‘real’ measure for B is (scaled) 15/20, so they don’t overlap and we can say that B appears to be more successful than C as well.
From a learning design perspective, do our evaluation artefacts have an implicit design that explains C’s pattern? Is there a difference we’re not seeing? Taking apart any ranking of likeliness to pass our evaluatory framework, C’s pattern is so unusual (high success/lack of any progress) that we learn something immediately from the pattern, whether it’s that C is struggling or that we need to review mechanisms we thought to be equivalent!
But who is more likely to succeed out of A and B? 19/20 and 10/10 are barely distinguishable in statistical terms! The question for us now is how many evaluations of a given skill or knowledge mastery are required for us to be confident of competence. This totally breaks the discrete cramming for exams and focus on assignment model because all of our science is built on the notion that evidence is accumulated through observation and the analysis of what occurred, in order to be able to construct models to predict future behaviour. In this case, our goal is to see if our students are competent.
I can never be 100% sure that my students will be able to perform a task but what is the level I’m happy with? How many times do I have to evaluate them at a skill so that I can say that x successes in y attempts constitutes a reliable outcome?
If we say that a student has to reliably succeed 90% of the time, we face the problem that just testing them ten times isn’t enough for us to be sure that they’re hitting 90%.
But the level of performance we need to be confident is quite daunting. By looking at some statistics, we can see that if we provide a student with 150 opportunities to demonstrate knowledge and they succeed at this 143 times, then it is very likely that their real success level is at least 90%.
If we say that competency is measured by a success rate that is greater than 75%, a student who achieves 10/10 has immediately met that but even succeeding at 9/9 doesn’t meet that level.
What this tells us (and reminds us) is that our learning environment design is incredibly important and it must start from a clear articulation of what success actually means, what our goals are and how we will know when our students have reached that point.
There is a grade separation between A and B but it’s artificial. I noted that it was hard to distinguish A and B statistically but there is one important difference in the lower bound of their confidence interval. A is less than 75%, B is slightly above.
Now we have to deal with the fact that A and B were both competent (if not the same) for the first ten tests and A was actually more competent than B until the 20th failed test. This has enormous implications for we structure evaluation, how many successful repetitions define success and how many ‘failures’ we can tolerate and still say that A and B are competent.
Confused? I hope not but I hope that this is making you think about evaluation in ways that you may not have done so before.
Too big for a term? Why terms?
Posted: February 3, 2016 Filed under: Education | Tags: advocacy, aesthetics, authenticity, beauty, design, dewey, education, educational research, higher education, learning, resources, student perspective, teaching, teaching approaches, tools Leave a commentI’ve reached the conclusion that a lot of courses have an unrealistically high number of evaluations. We have too many and we pretend that we are going to achieve outcomes for which we have no supporting evidence. Worse, in many cases, we are painfully aware that we cause last-minute lemming-like effects that do anything other than encourage learning. But why do we have so many? Because we’re trying to fit them into the term or semester size that we have: the administrative limit.
One the big challenges for authenticity in Computer Science is the nature of the software project. While individual programs can be small and easy to write, a lot of contemporary programming projects are:
- Large and composed of many small programs.
- Complex to a scale that may exceed one person’s ability to visualise.
- Long-lived.
- Multi-owner.
- Built on platforms that provide core services; the programmers do not have the luxury to write all of the code in the system.
Many final year courses in Software Engineering have a large project courses, where students are forced to work with a (usually randomly assigned) group to produce a ‘large’ piece of software. In reality, this piece of software is very well-defined and can be constructed in the time available: it has been deliberately selected to be so.
Is a two month software task in a group of six people indicative of real software?

June 16: Remember to curse teammate for late delivery on June 15.
Yes and no. It does give a student experience in group management, except that they still have the safe framework of lecturers over the top. It’s more challenging than a lot of what we do because it is a larger artefact over a longer time.
But it’s not that realistic. Industry software projects live over years, with tens to hundreds of programmers ‘contributing’ updates and fixes… reversing changes… writing documentation… correcting documentation. This isn’t to say that the role of a university is to teach industry skills but these skill sets are very handy for helping programmers to take their code and make it work, so it’s good to encourage them.
I believe finally, that education must be conceived as a continuing reconstruction of experience; that the process and the goal of education are one and the same thing.
from John Dewey, “My Pedagogic Creed”, School Journal vol. 54 (January 1897)
I love the term ‘continuing reconstruction of experience’ as it drives authenticity as one of the aesthetic characteristics of good education.
Authentic, appropriate and effective learning and evaluation activities may not fit comfortably into a term. We already accept this for activities such as medical internship, where students must undertake 47 weeks of work to attain full registration. But we are, for many degrees, trapped by the convention of a semester of so many weeks, which is then connected with other semesters to make a degree that is somewhere between three to five years long.
The semester is an artefact of the artificial decomposition of the year, previously related to season in many places but now taking on a life of its own as an administrative mechanism. Jamming things into this space is not going to lead to an authentic experience and we can now reject this on aesthetic grounds. It might fit but it’s beautiful or true.
But wait! We can’t do that! We have to fit everything into neat degree packages or our students won’t complete on time!
Really?
Let’s now look at the ‘so many years degree’. This is a fascinating read and I’ll summarise the reported results for degree programs in the US, which don’t include private colleges and universities:
- Fewer than 10% of reporting institutions graduated a majority of students on time.
- Only 19% of students at public universities graduate on-time.
- Only 36% of state flagship universities graduate on-time
- 5% of community college students complete an associate degree on-time.
The report has a simple name for this: the four-year myth. Students are taking longer to do their degrees for a number of reasons but among them are poorly designed, delivered, administered or assessed learning experiences. And jamming things into semester blocks doesn’t seem to be magically translating into on-time completions (unsurprisingly).
It appears that the way we break up software into little pieces is artificial and we’re also often trying to carry out too many little assessments. It looks like a good model is to stretch our timeline out over more than one course to produce an experience that is genuinely engaging, more authentic and more supportive of long term collaboration. That way, our capstone course could be a natural end-point to a three year process… or however long it takes to get there.
Finally, in the middle of all of this, we need to think very carefully about why we keep using the semester or the term as a container. Why are degrees still three to four years long when everything else in the world has changed so much in the last twenty years?
Confessions of a CLI guy
Posted: February 2, 2016 Filed under: Education | Tags: aesthetics, authenticity, beauty, cli, community, design, education, educational problem, educational research, graphics, guis, higher education, in the student's head, resources, teaching, teaching approaches, tools, truth Leave a commentThere was a time before graphics dominated the way that you worked with computers and, back then, after punchcards and before Mac/Windows, the most common way of working with a computer was to use the Command Line Interface (CLI). Many of you will have seen this, here’s Terminal from the Mac OS X, showing a piece of Python code inside an editor.

Rather than use a rich Integrated Development Environment, where text is highlighted and all sorts of clever things are done for me, I would run some sort of program editor from the command line, write my code, close that editor and then see what worked.
At my University, we almost always taught Computer Science using command line tools, rather than rich development environments such as Eclipse or the Visual Studio tools. Why? The reasoning was that the CLI developed skills required to write code, compile it, debug it and run it, without training students into IDE-provided shortcuts. The CLI was the approach that would work anywhere. That knowledge was, as we saw it, fundamental.
But, remember that Processing example? We clearly saw where the error was. This is what a similar error looks like for the Java programming language in a CLI environment.

Same message (and now usefully on the right line because 21st Century) but it is totally divorced from the program itself. That message has to give me a line number (5) in the original program because it has no other way to point to the problem.
And here’s the problem. The cognitive load increases once we separate code and errors. Despite those Processing errors looking like the soft option, everything we know about load tells us that students will find fixing their problems easier if they don’t have to mentally or physically switch between code and error output.
Everything I said about CLIs is still true but that’s only a real consideration if my students go out into the workplace and need some CLI skills. And, today, just about every workplace has graphics based IDEs for production software. (Networking is often an exception but we’ll skip over that. Networking is special.)
The best approach for students learning to code is that we don’t make things any harder than we need to. The CLI approach is something I would like students to be able to do but my first task is to get them interested in programming. Then I have to make their first experiences authentic and effective, and hopefully pleasant and rewarding.
I have thought about this for years and I started out as staunchly CLI. But as time goes by, I really have to wonder whether a tiny advantage for a small number of graduates is worth additional load for every new programmer.
And I don’t think it is worth it. It’s not fair. It’s the opposite of equitable. And it goes against the research that we have on cognitive load and student workflows in these kinds of systems. We already know of enough load problems in graphics based environments if we make the screens large enough, without any flicking from one application to another!
You don’t have to accept my evaluation model to see this because it’s a matter of common sense that forcing someone to unnecessarily switch tasks to learn a new skill is going to make it harder. Asking someone to remember something complicated in order to use it later is not as easy as someone being able to see it when and where they need to use it.
The world has changed. CLIs still exist but graphical user interfaces (GUIs) now rule. Any of my students who needs to be a crack programmer in a text window of 80×24 will manage it, even if I teach with all IDEs for the entire degree, because all of the IDEs are made up of small windows. Students can either debug and read error messages or they can’t – a good IDE helps you but it doesn’t write or fix the code for you, in any deep way. It just helps you to write code faster, without having to wait and switch context to find silly mistakes that you could have fixed in a split second in an IDE.
When it comes to teaching programming, I’m not a CLI guy anymore.
Is an IDE an E3? Maybe an E2?
Posted: February 1, 2016 Filed under: Education | Tags: advocacy, aesthetics, authenticity, beauty, design, education, educational problem, educational research, feedback, higher education, IDEs, Processing, resources, student perspective, teaching, teaching approaches, thinking, tools 2 CommentsEarlier, I split the evaluation resources of a course into:
- E1 (the lecturer and course designer),
- E2 (human work that can be based on rubrics, including peer assessment and casual markers),
- E3 (complicated automated evaluation mechanisms)
- E4 (simple automated evaluation mechanisms, often for acceptance testing)
E1 and E2 everyone tends to understand, because the culture of Prof+TA is widespread, as is the concept of peer assessment. In a Computing Course, we can define E3 as complex marking scripts that perform amazing actions in response to input (or even carry out formal analysis if we’re being really keen), with E4 as simple file checks, program compilation and dumb scripts that jam in a set of data and see what comes out.
But let’s get back to my first year, first exposure, programming class. What I want is hands-on, concrete, active participation and constructive activity and lots of it. To support that, I want the best and most immediate feedback I can provide. Now I can try to fill a room with tutors, or do a lot of peer work, but there will come times when I want to provide some sort of automated feedback.
Given how inexperienced these students are, it could be a quite a lot to expect them to get their code together and then submit it to a separate evaluation system, then interpret the results. (Remember I noted earlier on how code tracing correlates with code ability.)
Thus, the best way to get that automated feedback is probably working with the student in place. And that brings us to the Integrated Development Environment (IDE). An IDE is an application that provides facilities to computer programmers and helps them to develop software. They can be very complicated and rich (Eclipse), simple (Processing) or aimed at pedagogical support (Scratch, BlueJ, Greenfoot et al) but they are usually made up of a place in which you can assemble code (typing or dragging) and a set of buttons or tools to make things happen. These are usually quite abstract for early programmers, built on notional machines rather than requiring a detailed knowledge of hardware.

The Processing IDE. Type in one box. Hit play. Rectangle appears.
Even simple IDEs will tell you things that provide immediate feedback. We know how these environments can have positive reception, with some demonstrated benefits, although I recommend reading Sorva et al’s “A Review of Generic Program Visualization Systems for Introductory Programming Education” to see the open research questions. In particular, people employing IDEs in teaching often worry about the time to teach the environment (as well as the language), software visualisations, concern about time on task, lack of integration and the often short lifespan of many of the simpler IDEs that are focused on pedagogical outcomes. Even for well-established systems such as BlueJ, there’s always concern over whether the investment of time in learning it is going to pay off.
In academia, time is our currency.
But let me make an aesthetic argument for IDEs, based on the feedback that I’ve already put into my beautiful model. We want to maximise feedback in a useful way for early programmers. Early programmers are still learning the language, still learning how to spell words, how to punctuate, and are building up to a grammatical understanding. An IDE can provide immediate feedback as to what the computer ‘thinks’ is going on with the program and this can help the junior programmer make immediate changes. (Some IDEs have graphical representations for object systems but we won’t discuss these any further here as the time to introduce objects is a subject of debate.)
Now there’s a lot of discussion over the readability of computer error messages but let me show you an example. What’s gone wrong in this program?

See where that little red line is, just on the end of the first line? Down the bottom there’s a message that says “missing a semicolon”. In the Processing language, almost all lines end with a “;” so that section of code should read:
size(200,200); rect(0,10,100,100);
Did you get that? That missing semicolon problem has been an issue for years because many systems report the semicolon missing on the next line, due to the way that compilers work. Here, Processing is clearly saying: Oi! Put a semi-colon on the red squiggle.
I’m an old programmer, who currently programs in Java, C++ and Processing, so typing “;” at the end of a line is second nature to me. But it’s an easy mistake for a new programmer to make because, between all of the ( and the ) and the , and the numbers and the size and the rect… what do I do with the “;”?
The Processing IDE is functioning in at least an E4 mode: simple acceptance testing that won’t let anything happen until you fix that particular problem. It’s even giving you feedback as to what’s wrong. Now this isn’t to say that it’s great but it’s certainly better than a student sitting there with her hand up for 20 minutes waiting for a tutor to have the time to come over and say “Oh, you’re missing a semicolon.”
We don’t want shotgun coding, where random fixes and bashed-in attempts are made desperately to solve a problem. We want students to get used to getting feedback on how they’re going and using this to improve what they do.
Because of Processing’s highly visual mode, I think it’s closer to E3 (complex scripting) in many ways because it can tell you if it doesn’t understand what you’re trying to do at all. Beyond just not doing something, it can clearly tell you what’s wrong.
But what if it works and then the student puts something up on the screen, a graphic of some sort and it’s not quite right? Then the student has started to become their own E2, evaluating what has happened in response to the code and using human insight to address the shortfall and make changes. Not as an expert but, with support and encouragement, a developing expertise.
Feedback is good. Immediacy is good. Student involvement is good. Code tracing is linked to coding ability. A well-designed IDE can be simple and engage the student to an extent that is potentially as high as E2, although it won’t be as rich, without using any other human evaluation resources. Even if there is no other benefit, the aesthetic argument is giving us a very strong nudge to adopt an appropriate IDE.
Maybe it’s time to hang up the command line and live in a world where IDEs can help us to get things done faster, support our students better and make our formal human evaluation resources go further.
What do you think?
The shortest interval
Posted: January 30, 2016 Filed under: Education | Tags: advocacy, aesthetics, authenticity, beauty, community, design, education, educational problem, educational research, higher education, in the student's head, learning, resources, teaching, teaching approaches, tools 2 Comments
Tick tick tick
If we want to give feedback, then the time it takes to give feedback is going to determine how often we can do it. If the core of our evaluation is feedback, rather than some low-Bloom’s quiz-based approach giving a score of some sort, then we have to set our timelines to allow us to:
- Get the work when we are ready to work on it
- Undertake evaluation to the required level
- Return that feedback
- Do this at such a time that our students can learn from it and potentially use it immediately, to reinforce the learning
A commenter asked me how I actually ran large-scale assessment. The largest class I’ve run detailed feedback/evaluation on was 360 students with a weekly submission of a free-text (and graphics) solution to a puzzle. The goal was to have the feedback back within a week – prior to the next lecture where the solution would be delivered.
I love a challenge.
This scale is, obviously, impossible for one person to achieve reliably (we estimated it as at least forty hours of work). Instead, we allocated a marking team to this task, coordinated by the lead educator. (E1 and E2 model again. There was, initially, no automated capacity for this at the time although we added some later.)
Coordinating a team takes time. Even when you start with a rubric, free text answers can turn up answer themes that you didn’t anticipate and we would often carry our simple checks to make sure that things were working. But, looking at the marking time I was billed for (a good measure), I could run an entire cycle of this in three days, including briefing time, testing, marking, and oversight. But this is with a trained team, a big enough team, good conceptual design and a senior educator who’s happy to take a more executive role.
In this case, we didn’t give the students a chance to refactor their work but, if we had, we could have done this with a release 3 days after submission. To ensure that we then completed the work again by the ‘solution release’ deadline, we would have had to set the next submission deadline to only 24 hours after the feedback was released. This sounds short but, if we assume that some work has been done, then refactoring and reworking should take less time.
But then we have to think about the cost. By running two evaluation cycles we are providing early feedback but we have doubled our cost for human markers (a real concern for just about everyone these days).
My solution was to divide the work into two components. The first was quiz-based and could be automatically and immediately assessed by the Learning Management System, delivering a mark at a fixed deadline. The second part was looked at by humans. Thus, students received immediate feedback on part of the problem straight away (or a related problem) while they were waiting for humans.
But I’d be the first to admit that I hadn’t linked this properly, according to my new model. It does give us insight for a staged hybrid model where we buffer our human feedback by using either smart or dumb automated assessment component to highlight key areas and, better still, we can bring these forward to help guide time management.
I’m not unhappy with that early attempt at large-scale human feedback as the students were receiving some excellent evaluation and feedback and it was timely and valuable. It also gave me a lot of valuable information about design and about what can work, as well as how to manage marking teams.
I also realised that some courses could never be assessed the way that they claimed unless they had more people on task or only delivered at a time when the result wasn’t usable anymore.
How much time should we give students to rework things? I’d suggest that allowing a couple of days takes into account the life beyond Uni that many students have. That means that we can do a cycle in a week if we can keep our human evaluation stages under 2 days. Then, without any automated marking, we get 2 days (E1 or E2) + 2 days (student) + 2 days (second evaluation, possibly E2) + 1 day (final readjustment) and then we should start to see some of the best work that our students can produce.
Assuming, of course, that all of us can drop everything to slot into this. For me, this motivates a cycle closer to two to three weeks to allow for everything else that both groups are doing. But that then limits us to fewer than five big assessment items for a twelve week course!
What’s better? Twelve assessment items that are “submit and done” or four that are “refine and reinforce to best practice”? Is this even a question we can ask? I know which one is aesthetically pleasing, in terms of all of the educational aesthetics we’ve discussed so far but is this enough for an educator to be able to stand up to a superior and say “We’re not going to do X because it just doesn’t make any sense!”
What do you think?
Equity is the principal educational aesthetic
Posted: January 26, 2016 Filed under: Education | Tags: aesthetics, authenticity, beauty, Bloom, community, education, educational research, ethics, higher education, learning, mastery, reflection, resources, teaching, teaching approaches, time management, tools Leave a commentI’ve laid out some honest and effective approaches to the evaluation of student work that avoid late penalties and still provide high levels of feedback, genuine motivation and a scalable structure.

But these approaches have to fit into the realities of time that we have in our courses. This brings me to the discussion of mastery learning (Bloom). An early commenter noted how much my approach was heading towards mastery goals, where we use personalised feedback and targeted intervention to ensure that students have successfully mastered certain tiers of knowledge, before we move on to those that depend upon them.
A simple concept: pre-requisites must be mastered before moving on. It’s what much of our degree structure is based upon and is what determines the flow of students through courses, leading towards graduation. One passes 101 in order to go on to courses that assume such knowledge.
Within an individual course, we quickly realise that too many mastery goals starts to leave us in a precarious position. As I noted from my earlier posts, having enough time to do your job as designer or evaluator requires you to plan what you’re doing and keep careful track of your commitments. The issue that arises with mastery goals is that, if a student can’t demonstrate mastery, we offer remedial work and re-training with an eye to another opportunity to demonstrate that knowledge.
This can immediately lead to a backlog of work that must be completed prior to the student being considered to have mastered an area, and thus being ready to move on. If student A has completed three mastery goals while B is struggling with the first, where do we pitch our teaching materials, in anything approximating a common class activity, to ensure that everyone is receiving both what they need and what they are prepared for? (Bergmann and Sams’ Flipped Mastery is one such approach, where flipping and time-shifting are placed in a mastery focus – in their book “Flip Your Classroom”)
But even if we can handle a multi-speed environment (and we have to be careful because we know that streaming is a self-fulfilling prophecy) how do we handle the situation where a student has barely completed any mastery goals and the end of semester is approaching?
Mastery learning is a sound approach. It’s both ethically and philosophically pitched to prevent the easy out for a teacher of saying “oh, I’m going to fit the students I have to an ideal normal curve” or, worse, “these are just bad students”. A mastery learning approach tends to produces good results, although it can be labour intensive as we’ve noted. To me, Bloom’s approach is embodying one of my critical principles in teaching: because of the variable level of student preparation, prior experience and unrelated level of privilege, we have to adjust our effort and approach to ensure that all students can be brought to the same level wherever possible.
Equity is one of my principle educational aesthetics and I hope it’s one of yours. But now we have to mutter to ourselves that we have to think about limiting how many mastery goals there are because of administrative constraints. We cannot load up some poor student who is already struggling and pretend that we are doing anything other than delaying their ultimate failure to complete.
At the same time, we would be on shaky ground to construct a course where we could turn around at week 3 of 12 and say “You haven’t completed enough mastery goals and, because of the structure, this means that you have already failed. Stop trying.”
The core of a mastery-based approach is the ability to receive feedback, assimilate it, change your approach and then be reassessed. But, if this is to be honest, this dependency upon achievement of pre-requisites should have a near guarantee of good preparation for all courses that come afterwards. I believe that we can all name pre-requisite and dependency patterns where this is not true, whether it is courses where the pre-requisite course is never really used or dependencies where you really needed to have achieved a good pass in the pre-req to advance.
Competency-based approaches focus on competency and part of this is the ability to use the skill or knowledge where it is required, whether today or tomorrow. Many of our current approaches to knowledge and skill are very short-term-focussed, encouraging cramming or cheating in order to tick a box and move on. Mastering a skill for a week is not the intent but, unless we keep requiring students to know or use that information, that’s the message we send. This is honesty: you must master this because we’re going to keep using it and build on it! But trying to combine mastery and grades raises unnecessary tension, to the student’s detriment.
As Bloom notes:
Mastery and recognition of mastery under the present relative grading system is unattainable for the majority of students – but this is the result of the way in which we have “rigged” the educational system.
Bloom, Learning for Mastery, UCLA CSEIP Evaluation Comment, 1, 2, 1968.
Mastery learning is part and parcel of any competency based approach but, without being honest about the time constraints that are warping it, even this good approach is diminished.
The upshot of this is that any beautiful model of education adhering to the equity aesthetic has to think in a frame that is longer than a semester and in a context greater than any one course. We often talk about doing this but detailed alignment frequently escapes us, unless it is to put up our University-required ‘graduate attributes’ to tell the world how good our product will be.
We have to accept that part of our job is asking a student to do something and then acknowledging that they have done it, while continuing to build systems where what they have done is useful, provides a foundation to further learning and, in key cases, is something that they could do again in the future to the approximate level of achievement.
We have to, again, ask not only why we grade but also why we grade in such strangely synchronous containers. Why is it that a degree for almost any subject is three to five years long? How is that, despite there being nearly thirty years between the computing knowledge in the degree that I did and the one that I teach, they are still the same length? How are we able to have such similarity when we know how much knowledge is changing?
A better model of education is not one that starts from the assumption of the structures that we have. We know a lot of things that work. Why are we constraining them so heavily?
Being honest about driverless cars
Posted: January 25, 2016 Filed under: Education, Opinion | Tags: advocacy, aesthetics, authenticity, beauty, blogging, community, driverless car, education, ethics, good, higher education, resources, teaching, teaching approaches, tools, trolley problem, truth, utilitarianism Leave a commentI have been following the discussion about the ethics of the driverless car with some interest. This is close to a contemporary restatement of the infamous trolley problem but here we are instructing a trolley in a difficult decision: if I can save more lives by taking lives, should I do it? In the case of a driverless car, should the car take action that could kill the driver if, in doing so, it is far more likely to save more lives than would be lost?
While I find the discussion interesting, I worry that such discussion makes people unduly worried about driverless cars, potentially to a point that will delay adoption. Let’s look into why I think that. (I’m not going to go into whether cars, themselves, are a good or bad thing.)
Many times, the reason for a driverless car having to make such a (difficult) decision is that “a person leaps out from the kerb” or “driving conditions are bad” and “it would be impossible to stop in time.”
As noted in CACM:
The driverless cars of the future are likely to be able to outperform most humans during routine driving tasks, since they will have greater perceptive abilities, better reaction times, and will not suffer from distractions (from eating or texting, drowsiness, or physical emergencies such as a driver having a heart attack or a stroke).
In every situation where a driverless car could encounter a situation that would require such an ethical dilemma be resolved, we are already well within the period at which a human driver would, on average, be useless. When I presented the trolley problem, with driverless cars, to my students, their immediate question was why a dangerous situation had arisen in the first place? If the car was driving in a way that it couldn’t stop in time, there’s more likely to be a fault in environmental awareness or stopping-distance estimation.
If a driverless car is safe in varied weather conditions, then it has no need to be travelling at the speed limit merely because the speed limit is set. We all know the mantra of driving: drive to the conditions. In a driverless car scenario, the sensory awareness of the car is far greater than our own (and we should demand that it was) and thus we will eliminate any number of accidents before we arrived at an ethical problem.
Millions of people are killed in car accidents every year because of drink driving and speeding. In Victoria, Australia, close to 40% of accidents are tied to long distance driving and fatigue. We would eliminate most, if not all, of these deaths immediately with driverless technology adopted en masse.
What about people leaping out in front of the car? In my home city, Adelaide, South Australia, the average speed across the city is just under 30 kilometres per hour, despite the speed limit being 50 (traffic lights and congestion has a lot to do with this). The average human driver takes about 1.5 seconds to react (source), then braking deceleration is about 7 metres per second per second, less effectively in the wet. From that source, the actual stopping part of the braking, if we’re going 30km/h, is going to be less than 9 metres if it’s dry, 13 metres if wet. Other sources note that, with human reactions, the minimum overall braking is about 12 metres, 6 of which are braking. The good news is that 30km/h is already the speed at which only 10% of pedestrians are killed and, given how quickly an actively sensing car could react and safely coordinate braking without skidding, the driverless car is incredibly unlikely to be travelling fast enough to kill someone in an urban environment and still be able to provide the same average speed as we had.
The driverless car, without any ethics beyond “brake to avoid collisions”, will be causing a far lower level of injury and death. They don’t drink. They don’t sleep. They don’t speed. They will react faster than humans.
(That low urban speed thing isn’t isolated. Transport for London estimate the average London major road speed to be around 31 km/h, around 15km/h for Central London. Central Berlin is about 24 km/h, Warsaw is 26. Paris is 31 km/h and has a fraction of London’s population, about twice the size of my own city.)
Human life is valuable. Rather than focus on the impact on lives that we can see, as the Trolley Problem does, taking a longer view and looking at the overall benefits of the driverless car quickly indicates that, even if driverless cars are dumb and just slam on the brakes, the net benefit is going to exceed any decisions made because of the Trolley Problem model. Every year that goes by without being able to use this additional layer of safety in road vehicles is costing us millions of lives and millions of injuries. As noted in CACM, we already have some driverless car technologies and these are starting to make a difference but we do have a way to go.
And I want this interesting discussion of ethics to continue but I don’t want it to be a reason not to go ahead, because it’s not an honest comparison and saying that it’s important just because there’s no human in the car is hypocrisy.
I wish to apply the beauty lens to this. When we look at a new approach, we often find things that are not right with it and, given that we have something that works already, we may not adopt a new approach because we are unsure of it or there are problems. The aesthetics of such a comparison, the characteristics we wish to maximise, are the fair consideration of evidence, that the comparison be to the same standard, and a commitment to change our course if the evidence dictates that it be so. We want a better outcome and we wish to make sure that any such changes made support this outcome. We have to be honest about our technology: some things that are working now and that we are familiar with are not actually that good or they are solving a problem that we might no longer need to solve.
Human drivers do not stand up to many of the arguments presented as problems to be faced by driverless cars. The reason that the trolley problems exists in so many different forms, and the fact that it continues to be debated, shows that this is not a problem that we have moved on from. You would also have to be highly optimistic in your assessment of the average driver to think that a decision such as “am I more valuable than that evil man standing on the road” is going through anyone’s head; instead, people jam on the brakes. We are holding driverless cars to a higher standard than we accept for driving when it’s humans. We posit ‘difficult problems’ that we apparently ignore every time we drive in the rain because, if we did not, none of us would drive!
Humans are capable of complex ethical reasoning. This does not mean that they employ it successfully in the 1.5 seconds of reaction time before slamming on the brakes.
We are not being fair in this assessment. This does not diminish the value of machine ethics debate but it is misleading to focus on it here as if it really matters to the long term impact of driverless cars. Truck crashes are increasing in number in the US, with over 100,000 people injured each year, and over 4,000 killed. Trucks follow established routes. They don’t go off-road. This makes them easier to bring into an automated model, even with current technology. They travel long distances and the fatigue and inattention effects upon human drivers kill people. Automating truck fleets will save over a million lives in the US alone in the first decade, reducing fleet costs due to insurance payouts, lost time, and all of those things.
We have a long way to go before we have the kind of vehicles that can replace what we have but let’s focus on what is important. Getting a reliable sensory rig that works better than a human and can brake faster is the immediate point at which any form of adoption will start saving lives. Then costs come down. Then adoption goes up. Then millions of people live happier lives because they weren’t killed or maimed by cars. That’s being fair. That’s being honest. That will lead to good.
Your driverless car doesn’t need to be prepared to kill you in order to save lives.

And you may even still be able to get your kicks.
Education is not defined by a building
Posted: January 24, 2016 Filed under: Education, Opinion | Tags: advocacy, aesthetics, art, authenticity, beauty, design, dewey, education, educational problem, educational research, ethics, good, higher education, in the student's head, learning, reflection, resources, teaching, teaching approaches, thinking, truth Leave a commentI drew up a picture to show how many people appear to think about art. Now this is not to say that this is my thinking on art but you only have to go to galleries for a while to quickly pick up the sotto voce (oh, and loud) discussions about what constitutes art. Once we move beyond representative art (art that looks like real things), it can become harder for people to identify what they consider to be art.

This is crude and bordering on satirical. Read the text before you have a go at me over privilege and cultural capital.
I drew up this diagram in response to reading early passages from Dewey’s “Art as Experience”:
“An instructive history of modern art could be written in terms of the formation of the distinctively modern institutions of museum and exhibition gallery. (p8)
[…]
The growth of capitalism has been a powerful influence in the development of the museum as the proper home for works of art, and in the promotion of the idea that they are apart from the common life. (p8)
[…]
Why is there repulsion when the high achievements of fine art are brought into connection with common life, the life that we share with all living creatures?” (p20)
Dewey’s thinking is that we have moved from a time when art was deeply integrated into everyday life to a point where we have corralled “worthy” art into buildings called art galleries and museums, generally in response to nationalistic or capitalistic drivers, in order to construct an artefact that indicates how cultured and awesome we are. But, by doing this, we force a definition that something is art if it’s the kind of thing you’d see in an art gallery. We take art out of life, making valuable relics of old oil jars and assigning insane values to collections of oil on canvas that please the eye, and by doing so we demand that ‘high art’ cannot be part of most people’s lives.
But the gallery container is not enough to define art. We know that many people resist modernism (and post-modernism) almost reflexively, whether it’s abstract, neo-primitivist, pop, or simply that the viewer doesn’t feel convinced that they are seeing art. Thus, in the diagram above, real art is found in galleries but there are many things found in galleries that are not art. To steal an often overheard quote: “my kids could do that”. (I’m very interested in the work of both Rothko and Malevich so I hear this a lot.)
But let’s resist the urge to condemn people because, after we’ve wrapped art up in a bow and placed it on a pedestal, their natural interpretation of what they perceive, combined with what they already know, can lead them to a conclusion that someone must be playing a joke on them. Aesthetic sensibilities are inherently subjective and evolve over time, in response to exposure, development of depth of knowledge, and opportunity. The more we accumulate of these guiding experiences, the more likely we are to develop the cultural capital that would allow us to stand in any art gallery in the world and perceive the art, mediated by our own rich experiences.
Cultural capital is a term used to describe the assets that we have that aren’t money, in its many forms, but can still contribute to social mobility and perception of class. I wrote a long piece on it and perception here, if you’re interested. Dewey, working in the 1930s, was reacting to the institutionalisation of art and was able to observe people who were attempting to build a cultural reputation, through the purchase of ‘art that is recognised as art’, as part of their attempts to construct a new class identity. Too often, when people who are grounded in art history and knowledge look at people who can’t recognise ‘art that is accepted as art by artists’ there is an aspect of sneering, which is both unpleasant and counter-productive. However, such unpleasantness is easily balanced by those people who stand firm in artistic ignorance and, rather than quietly ignoring things that they don’t like, demand that it cannot be art and loudly deride what they see in order to challenge everyone around them to accept the art of an earlier time as the only art that there is.
Neither of these approaches is productive. Neither support the aesthetics of real discussion, nor are they honest in intent beyond a judgmental and dismissive approach. Not beautiful. Not true. Doesn’t achieve anything useful. Not good.
If this argument is seeming familiar, we can easily apply it to education because we have, for the most part, defined many things in terms of the institutions in which we find them. Everyone else who stands up and talks at people over Power Point slides for forty minutes is probably giving a presentation. Magically, when I do it in a lecture theatre at a University, I’m giving a lecture and now it has amazing educational powers! I once gave one of my lectures as a presentation and it was, to my amusement, labelled as a presentation without any suggestion of still being a lecture. When I am a famous professor, my lectures will probably start to transform into keynotes and masterclasses.
I would be recognised as an educator, despite having no teaching qualifications, primarily because I give presentations inside the designated educational box that is a University. The converse of this is that “university education” cannot be given outside of a University, which leaves every newcomer to tertiary education, whether face-to-face or on-line, with a definitional crisis that cannot be resolved in their favour. We already know that home-schooling, while highly variable in quality and intention, is a necessity in some places where the existing educational options are lacking, is often not taken seriously by the establishment. Even if the person teaching is a qualified teacher and the curriculum taught is an approved one, the words “home schooling” construct tension with our assumption that schooling must take place in boxes labelled as schools.
What is art? We need a better definition than “things I find in art galleries that I recognise as art” because there is far too much assumption in there, too much infrastructure required and there is not enough honesty about what art is. Some of the works of art we admire today were considered to be crimes against conventional art in their day! Let me put this in context. I am an artist and I have, with 1% of the talent, sold as many works as Van Gogh did in his lifetime (one). Van Gogh’s work was simply rubbish to most people who looked at it then.
And yet now he is a genius.
What is education? We need a better definition than “things that happen in schools and universities that fit my pre-conceptions of what education should look like.” We need to know so that we can recognise, learn, develop and improve education wherever we find it. The world population will peak at around 10 billion people. We will not have schools for all of them. We don’t have schools for everyone now. We may never have the infrastructure we need for this and we’re going need a better definition if we want to bring real, valuable and useful education to everyone. We define in order to clarify, to guide, and to tell us what we need to do next.
First year course evaluation scheme
Posted: January 22, 2016 Filed under: Education, Opinion | Tags: advocacy, aesthetics, assessment, authenticity, beauty, design, education, educational problem, ethics, higher education, learning, reflection, resources, student perspective, teaching, teaching approaches, time management 2 CommentsIn my earlier post, I wrote:
Even where we are using mechanical or scripted human [evaluators], the hand of the designer is still firmly on the tiller and it is that control that allows us to take a less active role in direct evaluation, while still achieving our goals.
and I said I’d discuss how we could scale up the evaluation scheme to a large first year class. Finally, thank you for your patience, here it is.
The first thing we need to acknowledge is that most first-year/freshman classes are not overly complex nor heavily abstract. We know that we want to work concrete to abstract, simple to complex, as we build knowledge, taking into account how students learn, their developmental stages and the mechanics of human cognition. We want to focus on difficult concepts that students struggle with, to ensure that they really understand something before we go on.
In many courses and disciplines, the skills and knowledge we wish to impart are fundamental and transformative, but really quite straight-forward to evaluate. What this means, based on what I’ve already laid out, is that my role as a designer is going to be crucial in identifying how we teach and evaluate the learning of concepts, but the assessment or evaluation probably doesn’t require my depth of expert knowledge.
The model I put up previously now looks like this:
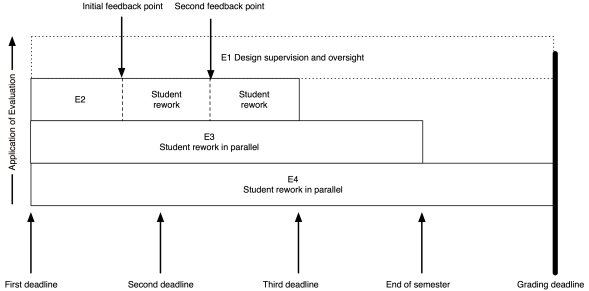
My role (as the notional E1) has moved entirely to design and oversight, which includes developing the E3 and E4 tests and training the next tier down, if they aren’t me.
As an example, I’ve put in two feedback points, suitable for some sort of worked output in response to an assignment. Remember that the E2 evaluation is scripted (or based on rubrics) yet provides human nuance and insight, with personalised feedback. That initial feedback point could be peer-based evaluation, group discussion and demonstration, or whatever you like. The key here is that the evaluation clearly indicates to the student how they are travelling; it’s never just “8/10 Good”. If this is a first year course then we can capture much of the required feedback with trained casuals and the underlying automated systems, or by training our students on exemplars to be able to evaluate each other’s work, at least to a degree.
The same pattern as before lies underneath: meaningful timing with real implications. To get access to human evaluation, that work has to go in by a certain date, to allow everyone involved to allow enough time to perform the task. Let’s say the first feedback is a peer-assessment. Students can be trained on exemplars, with immediate feedback through many on-line and electronic systems, and then look at each other’s submissions. But, at time X, they know exactly how much work they have to do and are not delayed because another student handed up late. After this pass, they rework and perhaps the next point is a trained casual tutor, looking over the work again to see how well they’ve handled the evaluation.
There could be more rework and review points. There could be less. The key here is that any submission deadline is only required because I need to allocate enough people to the task and keep the number of tasks to allocate, per person, at a sensible threshold.
Beautiful evaluation is symmetrically beautiful. I don’t overload the students or lie to them about the necessity of deadlines but, at the same time, I don’t overload my human evaluators by forcing them to do things when they don’t have enough time to do it properly.
As for them, so for us.
Throughout this process, the E1 (supervising evaluator) is seeing all of the information on what’s happening and can choose to intervene. At this scale, if E1 was also involved in evaluation, intervention would be likely last-minute and only in dire emergency. Early intervention depends upon early identification of problems and sufficient resources to be able to act. Your best agent of intervention is probably the person who has the whole vision of the course, assisted by other human evaluators. This scheme gives the designer the freedom to have that vision and allows you to plan for how many other people you need to help you.
In terms of peer assessment, we know that we can build student communities and that students can appreciate each other’s value in a way that enhances their perceptions of the course and keeps them around for longer. This can be part of our design. For example, we can ask the E2 evaluators to carry out simple community-focused activities in classes as part of the overall learning preparation and, once students are talking, get them used to the idea of discussing ideas rather than having dualist confrontations. This then leads into support for peer evaluation, with the likelihood of better results.
Some of you will be saying “But this is unrealistic, I’ll never get those resources.” Then, in all likelihood, you are going to have to sacrifice something: number of evaluations, depth of feedback, overall design or speed of intervention.
You are a finite resource. Killing you with work is not beautiful. I’m writing all of this to speak to everyone in the community, to get them thinking about the ugliness of overwork, the evil nature of demanding someone have no other life, the inherent deceit in pretending that this is, in any way, a good system.
We start by changing our minds, then we change the world.
The hand of an expert is visible in design
Posted: January 20, 2016 Filed under: Education | Tags: advocacy, aesthetics, arts and crafts, authenticity, beauty, community, design, dewey, education, educational problem, educational research, ethics, good, higher education, jeffrey petts, learning, morris, reflection, resources, student perspective, teaching, teaching approaches, thinking, time, time management, tools, truth 1 CommentIn yesterday’s post, I laid out an evaluation scheme that allocated the work of evaluation based on the way that we tend to teach and the availability, and expertise, of those who will be evaluating the work. My “top” (arbitrary word) tier of evaluators, the E1s, were the teaching staff who had the subject matter expertise and the pedagogical knowledge to create all of the other evaluation materials. Despite the production of all of these materials and designs already being time-consuming, in many cases we push all evaluation to this person as well. Teachers around the world know exactly what I’m talking about here.
Our problem is time. We move through it, tick after tick, in one direction and we can neither go backwards nor decrease the number of seconds it takes to perform what has to take a minute. If we ask educators to undertake good learning design, have engaging and interesting assignments, work on assessment levels well up in the taxonomies and we then ask them to spend day after day standing in front of a class and add marking on top?
Forget it. We know that we are going to sacrifice the number of tasks, the quality of the tasks or our own quality of life. (I’ve written a lot about time before, you can search my blog for time or read this, which is a good summary.) If our design was good, then sacrificing the number of tasks or their quality is going to compromise our design. If we stop getting sleep or seeing our families, our work is going to suffer and now our design is compromised by our inability to perform to our actual level of expertise!
When Henry Ford refused to work his assembly line workers beyond 40 hours because of the increased costs of mistakes in what were simple, mechanical, tasks, why do we keep insisting that complex, delicate, fragile and overwhelmingly cognitive activities benefit from us being tired, caffeine-propped, short-tempered zombies?
We’re not being honest. And thus we are not meeting our requirement for truth. A design that gets mangled for operational reasons without good redesign won’t achieve our outcomes. That’s not going to achieve our results – so that’s not good. But what of beauty?

William Morris: Snakeshead Textile
What are the aesthetics of good work? In Petts’ essay on the Arts and Crafts movement, he speaks of William Morris, Dewey and Marx (it’s a delightful essay) and ties the notion of good work to work that is authentic, where such work has aesthetic consequences (unsurprisingly given that we were aiming for beauty), and that good (beautiful) work can be the result of human design if not directly the human hand. Petts makes an interesting statement, which I’m not sure Morris would let pass un-challenged. (But, of course, I like it.)
It is not only the work of the human hand that is visible in art but of human design. In beautiful machine-made objects we still can see the work of the “abstract artist”: such an individual controls his labor and tools as much as the handicraftsman beloved of Ruskin.
Jeffrey Petts, Good Work and Aesthetic Education: William Morris, the Arts and Crafts Movement, and Beyond, The Journal of Aesthetic Education, Vol. 42, No. 1 (Spring, 2008), page 36
Petts notes that it is interesting that Dewey’s own reflection on art does not acknowledge Morris especially when the Arts and Crafts’ focus on authenticity, necessary work and a dedication to vision seems to be a very suitable framework. As well, the Arts and Crafts movement focused on the rejection of the industrial and a return to traditional crafting techniques, including social reform, which should have resonated deeply with Dewey and his peers in the Pragmatists. However, Morris’ contribution as a Pragmatist aesthetic philosopher does not seem to be recognised and, to me, this speaks volumes of the unnecessary separation between cloister and loom, when theory can live in the pragmatic world and forms of practice can be well integrated into the notional abstract. (Through an Arts and Crafts lens, I would argue that there is are large differences between industrialised education and the provision, support and development of education using the advantages of technology but that is, very much, another long series of posts, involving both David Bowie and Gary Numan.)
But here is beauty. The educational designer who carries out good design and manages to hold on to enough of her time resources to execute the design well is more aesthetically pleasing in terms of any notion of creative good works. By going through a development process to stage evaluations, based on our assessment and learning environment plans, we have created “made objects” that reflect our intention and, if authentic, then they must be beautiful.
We now have a strong motivating factor to consider both the often over-looked design role of the educator as well as the (easier to perceive) roles of evaluation and intervention.
I’ve revisited the diagram from yesterday’s post to show the different roles during the execution of the course. Now you can clearly see that the course lecturer maintains involvement and, from our discussion above, is still actively contributing to the overall beauty of the course and, we would hope, it’s success as a learning activity. What I haven’t shown is the role of the E1 as designer prior to the course itself – but that’s another post.
Even where we are using mechanical or scripted human markers, the hand of the designer is still firmly on the tiller and it is that control that allows us to take a less active role in direct evaluation, while still achieving our goals.
Do I need to personally look at each of the many works all of my first years produce? In our biggest years, we had over 400 students! It is beyond the scale of one person and, much as I’d love to have 40 expert academics for that course, a surplus of E1 teaching staff is unlikely anytime soon. However, if I design the course correctly and I continue to monitor and evaluate the course, then the monster of scale that I have can be defeated, if I can make a successful argument that the E2 to E4 marker tiers are going to provide the levels of feedback, encouragement and detailed evaluation that are required at these large-scale years.
Tomorrow, we look at the details of this as it applies to a first-year programming course in the Processing language, using a media computation approach.
