
Work and Life
Posted: January 21, 2026 Filed under: Opinion | Tags: community, higher education, personal development, reflection, social media, teaching 1 Comment
I’ve just returned from a brief holiday on the Australian East Coast and I had a chance to think about what the new leadership role at the Uni will mean. One thing I felt I had to do, although it was honestly a tough decision to make, was tidy up the work/personal aspects of my social media. This means unfriending (what a loaded term) some people who I’ve known through work for a while. It wasn’t easy to do and I’m still thinking about it. Why did I do it?
I will have new staff who don’t really know me, in a school where half of the team also don’t really know each other that well, and we are bringing together two successful, fully-formed, and slightly different academic cultures. Bringing these groups together, meeting their needs, being focused, being present, listening… all of these things are essential and they need the best of my professional aspects. I have recently found out that I have not been listening as well as I should and that’s on me to fix, to be the person I always wanted to be and claim that I am but, obviously, sometimes fall short at. (The irony is that I consider it likely that people have given me clear indications that I haven’t been seeming to listen enough to care about their input – but I haven’t noticed. Ick. I’m striving to pay attention now.)
I need to be “work Nick” primarily, because those are the skills, the focus, and the type of presence that they need. I have many interests but bringing them into the work space is not always the best use of anyone’s time and it’s certainly not what a junior teaching team academic needs when I’m managing them. To make the dividing line really clear, both for my ease of processing and for consistency, I’ve removed a number of people from my Facebook friends who are primarily work people, so that I don’t have some weird two speed situation of “I friended this person but this other one.” I’ve also had to unfriend someone from my own town who I’ve known for years but now we have a potential conflict because of our roles. I’ve had to do this before when I realised that you couldn’t friend some students and not others, even though there may have been an existing RW connection because my home town has about 1.5 degrees of separation.
(Years ago, there was even a student group “Nick Falkner won’t friend me on Facebook” and the student laser printer was part of it. No, I never added the laser printer.)
I’m unsure if removing work people was the right decision or not, as it means I can’t see what people who I met through work, and I like, are up to – but I’ve taken this decision as a good way to make it easier for me to set things up well for my new role and do the right thing by the people I’m managing. A part of me hopes that, after a year or two, when the culture is established and I’ve got to know people better, I can go back and reconnect to the other people, if they’ll have me.
I’d be really interested to know what people think and how you handle the work/personal social separation! Feel free to tell me how wrong or right you think I got it.
First day at the new (old) job
Posted: January 5, 2026 Filed under: Education | Tags: AI, education, higher education, learning, reflection, teaching, writing Leave a commentI sit at the desk in my new office on Level 5 of the building I’ve been working in for over 10 years, as part of a different university and with a new job title. The foundation universities of the University of Adelaide and the University of South Australia are now officially merged as Adelaide University, which is now roughly the 5th largest University in Australia. I am no longer the Deputy Head of the School of Computer and Mathematical Sciences, as neither the position nor that school still exist! I am an Academic Lead in the School of Computer Science and Information Technology, with responsibilities around educational research and our education specialist staff, and now have roughly 15 staff to manage as part of our new model.
Last year was pretty successful in many ways, the ITiCSE WG delivered an amazing report with some fantastic resources, I was part of a successful grant, the CompEd WG made fantastic progress (still going into the new year as we tidy that up), and I felt like, for the first time in ages, I really had the opportunity to look into research into detail. But it was very tiring, being the last year of a long push that started during the pandemic and finishing in a year where I got so sick that my hair started falling out and my overall physical health took a 10% hit. Much better now, although my hair is still my hair! And now the universities are merged and I’m part of the brand new Adelaide University. It’s a great time to look forward and set some themes for this year. But let’s do a 50,000 foot flyover of my job.
Research: From a research perspective, the CARD WG outcome has reinforced how important it is to have learning resources and tools that lead to the outcomes that you want – this is especially true in the face of the rise of Generative AI, where it is terrifyingly easy to sidestep any cognitive or memory work totally in the production of artefacts. For years, we got away with requiring student to produce something as evidence of a process of production, which entailed cognition, learning, and application of effort over time. Artefacts like the CARD Research Cards can’t be completed with generative AI, people have to interact with them. There are opportunities to engage with something, consider it, respond to it, and develop your skills accordingly. I sketched out some ideas last year about a working group based on tools and approaches for learning that specifically could not be carried out with Generative AI, but haven’t done anything with them. I most likely can’t do any WGs this year for timing and commitment reasons but I might pitch something next year about all the ways that game-based approaches to learning and non-AI-based scalable aspects of personalised learning can be useful in the era of Generative AI. The random and reflexive aspects of the cards make the process inherently focused on the individual – but I’ll return to this thought later. More stuff needs to happen with CARD but that’s a next week thought.
Teaching: I’m teaching a couple of courses this year, mostly around the postgraduate level, working on research skill development and computational research methods. This will be the first curricular application of the CARD system, realised as both physical cards and an online version developed by our fantastic media team in the learning design space. It will be great to be back in the classroom more!
Leadership and Service: I have 15 direct reports and will be getting to know them over the next few weeks. I suspect I’ll be in three places in a given week, my old stomping ground next to the Art Gallery on North Terrace, City West campus, and Mawson Lakes Campus. Learning what they need, and how I can use my experience and knowledge to help them, is one of my highest priorities prior to the start of Semester 1. I have had an unconventional pathway to academia but I still have many lenses of privilege to acknowledge and work through when I work with anybody else. There will be a lot of listening and thinking on my part. I have a number of duties for various SIGCSE roles that I’m looking forward to getting back into now that I’m finally healthy again.
Travel: I’ve been travelling a lot and the plane trips have been frequent, long, and not the best thing for me in any sense. I’m planning to spend about three months in Finland this year as part of a visiting fellowship at University of Jyväskylä but this will involve less flying and more time concentrated in one place. I hope that this will allow me to do better work and be more present…
Speaking of presence, I think that’s my most important theme for this year: present in my personal life, present for my students, present for my research collaborators, and definitely present for my colleagues, especially those who I’m managing. Something has been showing up in my shape at various points of the year but I’m not sure how much of it has been me. Let’s see what I can do this year.
Happy new year, everyone!
2025 ACM Global Computing Education Conference in Botswana, 21-22 October – Another Working Group!
Posted: May 8, 2025 Filed under: Education | Tags: botswana, community, comped, education, higher education, research, working groups Leave a commentWell, well, a third post in the year? Who made me research active? (I have not yet really been made research rigorous, despite some valiant attempts) I’m very excited to announce that we’ve got a working group advertised for the 2025 ACM Global Computing Education Conference in Botswana and we’d love to get more people involved. The Main conference runs Oct 23-25, Working Groups Oct 21-22 and Doctoral Consortium Oct 22.
You can join A/Prof Claudia Szabo, me, Dr. Munienge Mbodila, and Prof Judy Sheard as we work to assess impact, analyse the effects on higher ed institutions, and identify the challenges, with a focus on the Global South.
Brief motivation
This ACM working group, fitting within the broader remit of an ACM Task Force, aims to investigate the ethical and societal impacts of Generative AI tools within the higher computing education landscape within the Global South and to provide guidelines for the ethical incorporation of AI into teaching and assessment in CS1, CS2 and CS3, considering the desired learning outcomes at each level, student learning behaviour, validity of assessment and academic integrity, and local ethical frameworks. This working group will conduct a landscape analysis on Global South ethical questions related to the use of Generative AI tools in higher education contexts, identifying promising principles, challenges, and ways to navigate the implementation of Generative AI in ethical and principled ways. This working group builds on the ITiCSE working group with a similar name, and is developed under the guidance of two of that working group’s leaders, namely Alison Clear and Tony Clear. It focuses the lens on the Global South and specifically on CS1-3 perspectives within this space.
Get Involved!
If you want to read more or apply, please follow the link to the WG page and fill out your application before the end of May 9, anywhere around the world! There are excellent travel grants available to support this so check those out, too!
ITiCSE 2025: Working Group 1 – exciting news!
Posted: February 14, 2025 Filed under: Education | Tags: computer science education research, education, games, higher education, ITiCSE, learning, play, research, teaching, technology, thinking Leave a commentTwo posts in the same year? Something must be up… and it is! After the successful presentation of Dr Rebecca Vivian and my work at Koli as both DC tool and award winning poster/demo, I looked into taking this to a working group and Dr Miranda Parker agreed to co-lead it with me, as Rebecca is currently on leave. Miranda and I have been digging into all of the aspects of this in the middle of both our day jobs and it’s been a lot of fun to work on! You think you’ve got difficult collaborators? Miranda has to listen to me pontificate about ontologies, paradigms, and philosophies!
It’s really important to recognise Rebecca’s ongoing connection with this project, as it’s still very much Rebecca’s work that got us here and she will continue to be a significant part of this, we’re just making sure we have the co-leadership of people who aren’t on leave to make it work. It’s really exciting that our Workgroup has gone to the advertisement stage!
You can see all of the WG proposals here, and sign up (maybe to ours if you like what you read here) here. We’re happy to answer questions and it’s going to be an amazing combination of serious play, serious research, and great fun.
Here’s the ad as a cut and paste!
WG1 – Paradigms, Methods, and Outcomes, Oh My!: Refining and Evolving a Research Knowledge Development Activity for Computer Science Education
Leaders:
- Nick Falkner, nickolas.falkner@adelaide.edu.au
- Miranda Parker, miranda.parker@uncc.edu
Motivation:
Computer Science Education Research (CSER) combines the frequently quantitative approaches of computer science, engineering, and mathematics with the often more qualitative techniques seen in psychology, sociology, behavioural science, and education. It can be challenging to select appropriate research methods in effective and efficient ways.
Inspired by the use of card-based techniques in the classroom, the Research Alternatives Exercise (RAE) is a pack of 105 cards introducing a wide range of possible research approaches. RAE provides alternatives to a participant’s current research plans using new random lenses, leading to the sketch of a new research design. The participant refers to their own design through the lens of the randomly drawn card, working to see how well this fits, informs, or improves what they have done.
The initial version of the card deck and examples of play won best paper/demo at Koli Calling 2024 and an example “run” is shown below:
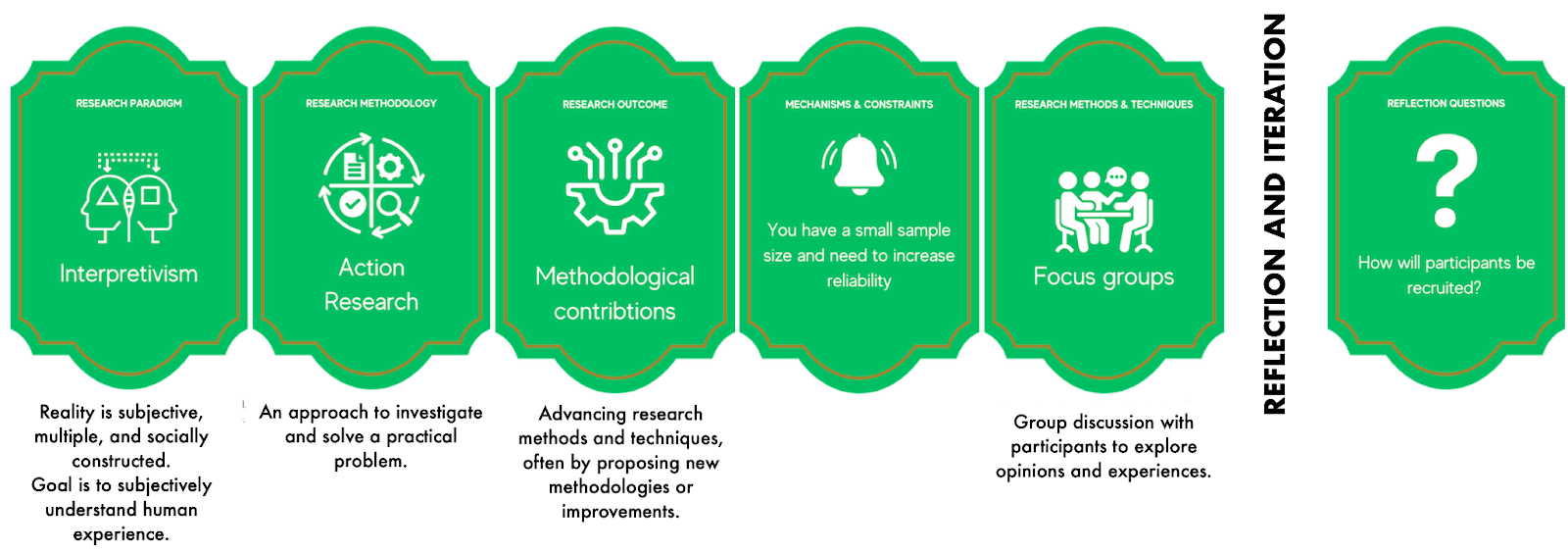
Goals:
- review and modify the existing deck through collaboration in the WG
- develop a version of the deck that can be shared and used widely across the CSER community,
- develop a concise support glossary for the cards
Methodology:
The current deck will be shared with participants, to support targeted literature review, research, and consultation to:
- refine the terminology used for categories, which are currently paradigms, methodologies, outcomes, and methods,
- refine the components within categories,
- review the existing rules for suitability,
- develop the first draft of the support glossary, and
- develop different decks and play approaches for specific purposes.
Following kickoff at the end of March, we will work on Items 1 and 3, aiming for completion by the start of May. When categories are finalized, we will undertake Item 2, where each group member will work in small groups to review each category. Findings will be presented to the whole group by the beginning of June, for further discussion and collaboration. Each sub-group will be responsible for the glossary elements of their contribution, to be completed and reviewed for the start of the in-person WG time. Each working group member will be asked to share the deck with colleagues to provide feedback.
Member Selection:
We seek at least 8-10 individuals to share the required work manageably.
We are looking for participants with at least one of:
- Experience with a wide variety of research methodologies,
- Experience in supervising graduate students,
- Interest and knowledge in using game-based and facilitated techniques, or
- Experience with research skills development.
We actively invite applications from disciplines beyond computing for diversity in research skills development experience. We seek a diversity of experience, background, and culture, to ensure that the feedback encompasses the full range of CSER community experience. We also welcome student applications.
Successful applicants will:
- Attend fortnightly 60-90 minute online progress meetings, held from mid-late March to the end of June,
- Register for ITiCSE 2025,
- Physically attend the full duration of the working group, and
- Make significant contributions during the pre- and post-ITiCSE Working Group activities (3-4 hours a week).
Books about Play
Posted: January 27, 2025 Filed under: Education, Opinion | Tags: books, education, games, gaming, play, reading, reflection, teaching, teaching approaches, thinking Leave a commentBeing a subset of interesting books from my collection, accompanied with explanatory texts of varying utility, as well as references to this blog.
A very rapid summary in far too much detail.
I recently had reason to distill my thoughts on why games, play, and the playing of games were a valid and even necessary area of discussion when talking about education. Some collaborators and I have been working on a new way to assist in research skills development that uses play mechanisms. I have had a lot of opportunity to read and think about this but I wanted to get it out of my head so other people could also understand why I thought the way that I did.
However, I realised when I was trying to write up my books about games and play, that I had quite a large amount of philosophy and theory behind it, as well as some motivating examples from other educators. I can direct people to the books but unless I really explain at least some of the journey, the books are just islands of fact in a desert, when really most of what I have here are stations on a longer and much more detailed journey. As with everything, it is not the fact, it is the context in which you encounter it and your mood and willingness to engage when that fact and context are coincident.
I also realise that there is a chance that anyone reading this may need to skim this. You will still have the books by name, which achieves the initial goal, and it is quite useful for me to write all of this up so that I have a record of it, should anyone else ask. The excuse to do this has allowed me to invest the effort, doubly so now that I have modified the original version of the text for publication on my (long dormant) education blog.
The layout of the following sections will be a collection of books and then some discussion as to why they’re here. Some are just good examples, some are more illustrative, some are essential. I shall attempt to make the difference clear.
Robert A. Sage
Myth

Theodor W. Adorno
Aesthetics

Genis Carreras
Philographics

Don Norman
The Design of Everyday Things

Myth: Robert A. Segal
Play is a fundamental part of being alive, for many creatures, not just us. Because we can’t communicate well with other species, it can be very hard to understand what is a habit or somehow driven by the surroundings, what is a (conscious?) choice for a creature to under a serious action, and what is play: to engage in activity for recreational purposes or enjoyment.
Obviously, many activities have both serious and play applications, so understanding whether an activity is play or serious cannot be determined simply by observing. For me, my pathway to understanding play began by seeking to understand how we, the human we, work with information, how we process what has gone before, how we understand it, label it, categorise it, express it, communicate it, and interact with it.
Thus I started with trying to understand how we formed the understanding of our early selves. I have had a number of books on the formation of human myth, how we talk about our pre-history and pre-written selves. There are many books of myth but I like this (tiny) Oxford University Press book from Segal about contemporary theories of myth, which contains the great truth that theories of myth are often subsets of some larger theory from a given discipline restricted to the area of myth.
Myths are not just stories in word or voice, but there is often a tie to ritual, physical activities that are associated with a long held traditional story or belief. This book covers many angles of the theory of myth, discussing in brief many approaches, and it was a (much larger but) similar text that led me to understand the importance of the physical in story-telling and communication.
A good story has many elements to it, in the use of voice and physical theatre, in the choice of location, even down to the timing of the tale and its cadence. But we only have to look to puppetry, an ancient art, or how children react to the use of small wooden animals, to see how quickly our minds can wrap narrative and assistive explanatory tool together. The idea that this could reinforce a ritual, reinforce a memory, and hence give us a mythic form that might carry information forward comes from books like this.
To restrict the domain of play to either the physical or the non-physical is to ignore the reality that we engage in physical and intellectual pursuits for our own amusement. From a personal angle, I am a somewhat infamous juggler of words, which is more intellectual, but I was for many years a keen underwater swimmer, as my terrible swimming style is no disadvantage when submerged. Water was my medium of play for many long Australian summers, as long as I could stay underneath it competing with my friends, diving for thrown objects, or diving to the bottom of the deepest pools I could find. It was a break from reality, a different space altogether: concepts I shall return to later on. Play has turned out to a very natural thing for me, but it took a lot of reading to understand how essential it was to my humanity and my serious work as well.
Theodor W. Adorno – Aesthetics
The next book is a rather odd choice as this is a set of lectures delivered by Adorno in 1958-59, which he used to base a book on … that he never finished. Theodor W. Adorno was a German philosopher, musicologist, and social theorist. He was a leading member of the Frankfurt School of critical theory and wrote many fascinating works including the amazing “Minima Moralia“, which is worth looking at in its own right as it is a collection of short themed observations, many of which are profound in their expression and content. However, this book is here for two reasons:
- His definitions of aesthetics from Kant and Hegel and the ongoing discussion throughout the book are some of the clearest I’ve seen and show very clearly the difference between “aesthetic as decoration” and “aesthetic as fitness for.. everything”.
- His deep commitment to interactive work with his students, where his own intellectual understanding of the work and his desire to present it in an engaging manner resulted in his own students not quite following. Rather than not following, he corrected himself and reset his context. Reading this book shows you a masterful thinker and philosopher being relatively really rather humble and I love it for that alone.
Returning briefly to point 1, I shall recall that aesthetics can be briefly described as the philosophy of the principles of beauty (among other things). Well, what then is beauty? I’m glad you asked. Kant basically defined beauty as everything attractive that was not useful – a ‘disinterested pleasure’. For example, an apple could be beautiful and hence aesthetically pleasing until you ate it, at which point your interaction was animal and essentialist – having found function/value, your interaction was no longer aesthetic. Hegel disagreed, quelle surprise, with Kant and redefined beauty as “the sensual appearance of an idea”. Now we could still interact with something in meaningful ways and indeed incorporate function into our definition of beauty.
This immediately admits the aesthetic of form in function, where aesthetically pleasing objects are also excellent examples of form, as is seen in a great deal of Japanese and Scandinavian artisanal handicraft, where function without good form is anathema.
You have to read the book to find out how much Hegel then went on to get wrong, according to Adorno, but one more thing to remember is that Adorno rejected aesthetic sensibilities as somehow objective or rigid, they were strongly associated with whatever matter you were regarding and that was where you derived their sense. This notion of relativism is quite liberating, as it allows for a multiplicity of aesthetic interpretations.
Genis Carreras – Philographics
This is a recent addition to my collection and I bought because it was a reminder of the complex pathway people have taken in their attempts to render complex concepts as simply symbols. One of my many interests is in wayfinding, in the physical and intellectual sense; this being the work of communicating pathways and directions to other people. This leans heavily on semiotics, the study of signs and symbols and their interpretation, as no map for wayfinding would work without a very clear sign vocabulary.
There are so many books I could put here but this is already long enough. This book is here as a simple symbolic placeholder to the importance of agreed contexts for shared understanding of symbolic representations, a vital part of the language of play. The range of human interpretation of words, actions, and symbols is vast and understanding if someone is playful or serious often hinges on this understanding. (Consider the Australian slang ‘sport’, which can be one of the most serious and threatening words anyone hears. It is not clear at all that this is the verbal equivalent of three giant flashing red lights and a tornado siren.)
Contrast this with the two images from this book, which seek to explain different concepts with simple symbols. Do they work? Perhaps. Are they interesting to consider, to view as guides to our own symbolic representation, and thus the way that we could consider play? Definitely.


Don Norman – The Design of Everyday Things
And here we are with the classic. How does the great naked ape, Homo Sapiens Sapiens, interact with the elements of its world? Norman’s book explains mugs, handles, defining the requirements of the things that a human is going to try to use in their pursuit of love, life, and work. In design, affordances, what the environment offers the individual, are reduced to what actions you can perceive are valid with an object. I have often extended this into the ethical sphere, as I believe that well-defined ethics provide the affordances for living with other people: what are the valid “handles” that one can “grab” and still be considered part of the in-group?
From a play perspective, we are back in the realm of semiotics: what do I need to show you so that you understand that the available affordances are playful rather than serious? What does that even mean?
I also find Norman invaluable for thinking about requirements analysis, as a simple affordance test on a prototype is a great way to show you all the things that actual people will do. Of course, in HCI and UI-design, the fact that you cannot predict everything a human will do is often a core concern, but reading Norman can help you to think about finding a coherent interaction model despite that.
Summary
So we’ve looked at the way we talk about ourselves, to understand how we might communicate play and serious, started a definition of aesthetics, wandered into wayfinding, and appreciated affordances. Let’s walk a little further into design before we finally start talking about texts that describe play.
Helen Cann
Hand Drawn Maps

Tomitsch et al
Design. Think. Make. Break. Repeat.

Bleecker et al
The Manual of Design Fiction

Roger Caillois
Man, Play, and Games

Helen Cann – Hand Drawn Maps
Again, there could be many books here. There is always Korzybski’s “The Map is not the Territory”, which is a very solemn version of “All models are incomplete but some are useful.” Maps are representations of something in the/a world, most often visual and two-dimensional, showing the things that are of interest to the map maker and also hopefully the map user. (Korzybski’s statement may be read as that if something was exactly the same as what it was mapping, it would be the thing – therefore, all maps are not exactly the same so what do you choose to change.)
I like public transit maps, because they so clearly show how you can get around cities, are almost always well-designed, and have to be useful to a large number of busy people. They are some of the most effective maps you’ll ever see because they have to be.
Amusingly, the London Underground Map is only useful underground. There had to be an active “London aboveground” program to show Londoners how to navigate the world above, because some things shown on the Underground map gave a totally false impression of what sensible aboveground navigation would look like. Why? Because the underground map prioritises connections, a breakthrough design by Harry Beck in the 1930s because he represented everything as a schematic diagram, rather than a mapping of the geographical reality. People on trains don’t need to know if the track is straight or curved, they need to know how many stations until they connect to go three more stations to Tooting Bec. I wrote a lot more about this about ten years ago.
Helen Cann’s book takes a playful perspective on maps and is aimed solidly at people who are building maps for fun, which is why it’s here instead of some other very serious books. It contains many creative prompts for building visual 2D imagery that conveys spatial and other relationships in a way that helps you navigate them. Maps, boards, cards, and games are all linked in my head and her book helps to understand why this is and why they are all subtly different.
This also admits the kind of graph/connection thinking that we see in the works of Franco Moretti – the Distant Reading Guy – where he carries out corpus analysis and NLP to derive relationships, determine changes, and explore hypotheses, without necessarily every personally reading the text. I like his stuff as a tool but I’m not sure I buy it as a solid methodology. Again, there’s a couple of blog posts on this here. Maps are fun!
Tomitsch et al – Design. Think. Make. Break. Repeat.
This is a book of design methods, roughly 60 different ways to engage in design with many perspectives and disciplines. It’s basically a short reference to scaffold the development of knowledge in the area of design: from product design to user experience and much in-between. I like this book for several reasons:
- Each section has a clear description, a reference list, step-by-step exercises, and a number of handy templates you can just start using.
- It’s very focused on getting you started trying something, to build knowledge through hands-on attempts.
- It has some really interesting case studies at the back.
I haven’t just learned about design from this book, I’ve learned about how to learn about design, and how I could construct other materials to make learning easier. This book has helped me to communicate ideas about play.
Bleecker et al – The Manual of Design Fiction
The last of the design books! Design fiction is probably one of my favourite things (I have many and don’t usually rank them so this is less exclusive than it may seem). At its heart, design fiction is the deliberate construction of narrative prototypes to suspend disbelief about the possibility and benefit of change. It is, like all fiction, inherently playful. We are building castles in the air and then sending in virtual construction inspectors to find our faults! How much more fantastically playful can we get?
This work is part of the core thinking about play and the research skills development tool that colleagues and I are working on. How can I get someone to understand that there might be another way to undertake their research? Let me rewrite that: how can I reduce the barriers to explore change? How do I encourage people to consider that there may be techniques and thinking that are not nonsense from other disciplines but valid contributors to academia? Again, let me rewrite that: how can I change your mind about which paradigms and methodologies are valid?
This book is a touch focused in the physical/reification space when, to me, design fiction has as much, if not more validity, in the area of ideation and knowledge development – this may all be nuance and I may just need to think more. It’s still a really interesting read and will add enormous amounts of interesting food for thought around group work, collaboration, and skill development.
Roger Caillois – Man, Play, and Games
I am deliberately presenting this book first, although it is very much a reaction to the next book, Homo Ludens. Caillois’ book is about the definition of what play is, with a wide range of culturally located definitions of the key games of given peoples, linking games even to moral aspects of culture, defining customs and institutions.
He accepts the essential need of humans to play and defines it (partially) as a voluntary sidestep from the realities of life, wherein rules constrain action and we all move to some outcome that has at least some randomness in its achievement. Children tend to improvise more, adults tend to strategise more, an increase of discipline with age and knowledge, perhaps or just another custom? He links some games back to mythic connection, where the games played by children mimic the actions of gods long ago, sometime deliberately as part of religious practice.
There are any number of important terms introduced here, including alea, which is best understood as chance but has many other meanings. When Julius Caesar took his armies across the Rubicon and into Rome, to take it as Emperor, he is supposed to have said “Alea iacta est.” which means “The die has been cast/I have taken my chance.” This statement is significant in its appeal to the fates, but also a recognition of uncertainty and a clear statement of bravado! (Recall that the study of probability is terrifyingly recent and many earlier cultures regarded what we would think of as random outcomes as clear indicators of favours granted by supernatural powers.)
Caillois took issue with Huizinga’s work, as he felt it lacked recognition of the variations of play and the needs served by play in a cultural context. While Caillois is, to me, the better text in terms of its utility because of its cultural inclusion, it’s still important to read Huizinga.
Summary
All of this is designed to provide tools, vocabulary, and background to really start to understand that games are important, culturally and personally, which provides us with a way to discuss useful games in well-defined manner. One of the biggest problems with educational games is that they are often a non-game activity which has had game elements bolted onto it. That does not make it a game, nor does it make it play. We shall return to this.
Johan Huizinga
Homo Ludens

Bernard Suits
The Grasshopper

Eric Zimmerman
The Rules We Break

Helen Fioratti
Playing Games

Johan Huizinga – Homo Ludens
At its core, Homo Ludens is about the necessity of play to culture and society. Animals play, but humans play in ways that assist us in becoming more than a small in-group, limited by the Dunbar limit and the size of our cerebellum. Play, to Huizinga, is one of the primary drivers that creates culture and is necessary if we are to generate culture. (We need more than play but there must be play.)
Huizinga, in a rather dour way, leads off with the fact that play must be fun, which is why animals also do it despite many of the playful species lacking the additional brain stuff that we and other sentients or proto-sentients appear to have.
As Caillois agreed with (mostly), Huizinga had five rules: that play is free, it is not everyday life and in fact it is noticeably different from everyday life, play has a sense of absolute order (think rules here), and nobody actually benefits in any real or monetary sense from play.
Play was not just free, play was freedom, and that concept explains a lot of the subsequent rules and text. Although Huizinga did not follow up on culture as Caillois would have liked, he did note that cultural perceptions change the nature of play: while western children might pretend to be an animal, a first-nations’ shaman would be culturally considered to have become one. Even the way that we talk about play shows how fragile our definitions are once we start thinking.
My paraphrase of all of this is that once we engage someone in play, they will potentially engage with the activity that we had planned, all the while inhabiting a totally different context due to their own cultural experience and perception.
This is not a book I can summarise easily as it has an enormous amount of classification, ideas, and content. I will share some important ideas from or derived from the work that I am using in developing new tools:
- The “magic circle”: this is the space in which the normal rules of reality are suspended and others now apply.
- The notion of metaphor as play, the metaphorical representation of wisdom/lesson as god forming myth in a model that is inherently playful. Thus all myth-making, a strong civilising force, is a playful activity.
- Poetry is play. I just like this one.
Bernard Suits – The Grasshopper
Words cannot contain how much I love this book. Suits takes direct aim at Wittgenstein’s assertion that definition is impossible, demonstrated by an inability to define what games are, by providing a definition. But he does so through the most charming and heart-wrenching of conceits. You are probably familiar with the fable of the hard working ants and the lazy grasshopper, where the ants worked all summer and the grasshopper just played music, then winter came and the ants lived and the grasshopper died because … ants are just not very nice, apparently. The conceit at the core of “The Grasshopper” is that the grasshopper is a philosopher of play and can thus not commit to beneficial labour as it contradicts his principles. He makes great contributions in his philosophical discourse with his students (ants dressed up as grasshoppers), who beseech him to take food that they have worked for, for him, but he refuses, committed at the deepest level to his philosophy of play.
Suits’ rules (slightly paraphrased) are:
- There are a set of rules for the game
- You cannot take the most direct path to achieve the outcome
- Players willingly accept both the previous rules, adopting a ludic mindset.
As you can see, we’re back in the realm of an excursion from reality, with its own rules, mind space, and no definition of benefit. In fact, the Grasshopper provides an example of total detriment by comparison but he would rather die firm in his philosophy than give up his principles
I am not doing this book justice, but I hope I am conveying its essence. I draw on this in a lot of what I do, as a communicator, because I am always seeking to draw people into a semi-ludic space to explore new ideas and I must have their consent and commitment to the ludic mindset to do it: people must give themselves the authority and freedom to play.
Eric Zimmerman – The Rules We Break
This is a book about how to actually make games but also how to evolve and adapt games. Zimmerman goes through possible problems with games and is also reinforcing all the things that people want to see in games: is a game too predictable, does a winner emerge too early, do people drop out too fast, or is it simply “not fun”?
There are many notionally educational games that are merely the activity in question with a strange game frame around, in the style of “Let’s get to Mars by solving this algebra problem”, which often fall very rapidly into the “not fun” category because it’s not a game at all. It’s a learning activity with set process and correct outcome, wearing some silly clothes.
This is another book about design, very hands on, and built to try things. Imagine running students through a redevelopment of a combined text generation exercise as a game where one student writes the title, another writes the slug, another writes key elements, but they only have two words to do it from without any discussion, then they combine it and look at the whole they’ve created from that cue. Not only does this book drive that sort of creativity, it helps you to analyse whether it’s working and how to fix it.
You will look at games differently after reading this book AND have lots of great things to try in the classroom.
Helen Fioratti – Playing Games
Again, many books could be here but I have a soft spot for this one as I picked it up in Florence while I was starting my ponderings about games. There are so many different games in the world, card games alone would keep you busy for a lifetime, let alone variants on boardgames.
In many ways, understanding what has gone before is both informative and interesting, and understanding the rise of new games as new technologies or practices emerged is important to thinking about games in general. Why did a certain game gain a particular variant? How do games change when they are played with a “house” (casino) vs playing against other people?
As I noted, there was a time where people played games of chance without understanding probability. Oh wait, that’s Vegas. I’ve never been to Vegas because it scares the hell out of me – it’s like a trap invented for people who sometimes think that they are more clever than they are.
Games are part of who we are, who we were, and who we hope to be. A good historical reference of games is essential and this one is quite acceptable.
Summary
I hope that I have now motivated why play is both essential and useful as a tool, given that it allows us to move into another space with other rules – ideal for us seeking to get students to experiment and engage in new spaces with less overhead. So let’s get to the final two books in my collection that are relevant here.
Peterson and Smith
The Rapid Prototyping Game

Engelstein and Shalev
Building blocks of Tabletop Design
Engelstein and Shalev – Building Blocks of Tablerop Game Design
An incredible reference and the most amazing way to understand every game you’ve every played and every game mechanic you’ve ever used elsewhere. It’s almost impossible to read sequentially as, despite being very thorough and technically interesting, it’s an encyclopaedia, not a narrative work.
In many ways it’s the archetype (with the design guide above) of the written work that I discuss below: a well-written, technically correct, and thorough capture that introduces every important concept, paradigm, framework, methodology etc.
It also gives an example of the way that categories matter in the formation of the work. A different set of categorisation choices would put some things in a very, very different place.
Peterson and Smith – The Rapid Prototyping Game
Finally, the cards that inspired the tool that I’m currently working on – there are substantial and meaningful differences but the cards themselves made me think of what else we could do. Smith wanted to teach his game design students other techniques and wanted to engage them and mentioned to Peterson that he wanted a good range of techniques to draw from. You can find his own blog on this here. Smith found the encyclopaedia above (Engelstein and Shalev) and thought it was a great resource that he could turn into a playful activity by using cards. Why? because what he was trying to do wasn’t working
“You see, the students were still struggling. They were afraid of failing. They were unoriginal. They made games like Chutes and Ladders or Monopoly.”
Smith, https://www.gamedeveloper.com/design/the-rapid-prototyping-game
His goal: build something the students could play with that broke a complex task down into well-defined and manageable categories that enabled the students to isolate particular categories and work on them. Decomposition, simplification, and information management all being used to make something complex far easier to work with. By using random allocation, via the cards, he was able to break students out of their “I’m going to make Monopoly” because they might not get the elements to do it – in fact, it was quite unlikely.
Smith and Peterson’s model used three dice throws to establish medium (board, card,…) , format (competitive, cooperative,…) , and objective (exploration, building,…). Then they used four decks of cards to let students draw from a much larger range of options for Mechanics, Themes, Victory Condition and Turn Order.
For the tool I’m working on, we have more decks of cards, because a 6-sided die only allows six options, whereas we often have up to twenty. While what I’m doing is definitely inspired by this approach, it is more inspired by the idea of play as a super-positional rule space that allows exploration in a free space with different rules, which I approach far more formally than the original card authors do.
Final Summary
Thus, my books on play along with, not promised at all, an unpacking of my process that led towards the idea that my wonderful colleague Dr Rebecca Vivian then reified as the cards themselves. I hope to be able to share more on this soon.
On pedagogical rations, we still seek to thrive.
Posted: June 7, 2020 Filed under: Education, Opinion | Tags: advocacy, education, educational problem, higher education, teaching, thinking 2 CommentsIt has been a tough year. Australia was on fire at the start, then sabre rattling started, then COVID came, and now the US is in turmoil as black voices rise up to demand justice and fair and equitable treatment as citizens. (Black Lives Matter. If that bothers you, go read someone else, or, better yet, educate yourself as to why you should agree.)
The COVID crisis has had a large impact on the educational sector, affecting enrolments at many Australian institutions as we are (to varying degrees) dependent upon international students for income. But now, many of our international students are not coming, which means that every University in Australia is taking a hit. At the same time, the COVID issues that prevent students from entering the country have forced us into an unexpected and unprecedented level of remote and on-line teaching for every student. We have been in remote mode for months now.
Many far more respected voices than me have correctly identified that we cannot learn a great deal about remote learning from this change, because it was not planned, it has no “before” state that we captured for a control, and it is a scrabbling matter of survival. We have gone from the relatively ample sustenance of Universities in the 1960s and ’70s, to a more constrained budget as funding changed, and now we are on survival rations.
Our pedagogies are also rationed, limited by the physical space we can occupy, the technologies that we have, the staff who are available, and an overwhelming sense of dread that fills the spaces in June as many of us think “What next?”
Rationing reduces both the quantity and range of what we consume. From a food perspective, history tells us that limited sustenance is dangerous in two ways: firstly because slow starvation is still starvation, and secondly, that there is a minimum requirement for a balanced diet or humans can get very sick or even die with full bellies. The consumption of maize, a staple of Mesoamerica, can easily lead to pellagra and other deficiency diseases unless it is nixtamalized with lye or lime. Where maize went without this knowledge, outbreaks of deficiency disease followed. It’s not just cereals and vegetables that have this problem: rabbit meat is so low in fat that a diet exclusively on this meat can lead to protein poisoning and, if rabbit is your only meat source, common advice is not to make it a substantial part of your diet.
Back to our pedagogies, while we are forced to ration our approaches and our resources, we have to think about whether we are providing enough for a balanced and sufficient education, or are we slowly starving our students or, worse still, introducing educational deficiencies that will hamper their development in the future?
There will be weeks and months of analysis after this challenging year, and many assumptions will be challenged. We will see the impact of these remote terms and semesters on education, on knowledge, on community, and on identity. But that analysis is after things improve. Right now, our focus is on monitoring the health of our communities, looking for slow decline and deficiency as best we can, and improving things where we can.
How long do we stay on these rations? 2020 is a brewing storm of new things, each one pushing a previous event into the background. Every lightning bolt is brighter and closer than before, every thunder clap louder.
If this were a storm at sea, we would be desperately trying to ensure our ship was sound, that it could stay afloat, and we would look for signs of the storm breaking.
When a ship is in distress, often its weight is reduced to improve its chances of staying afloat. The things thrown off are known as “jetsam”, distinguished from those things that float away (either from waves or because the ship has foundered), which are “flotsam”. What have we thrown from our ships, or at least considered?
There are no more face-to-face lectures in many cases. These are replaced with recordings or on-line presentation and discussion. There are fewer tutorials, with fewer people, as the tyranny of the physical prevents us from filling rooms while we are under disease management social distancing restrictions. We do not exchange paper. We do not gather in laboratories. We do not sit in one place to undertake examinations under strict invigilation conditions.
The traditional lecture, with hundreds of students sitting in a room to receive the wisdom from the front, is jetsam. At my institution, there will be no face-to-face lectures until 2021. This is mostly because we will not be legally allowed to put students into many of the lecture theatres at densities and numbers that make it feasible. Existing laws would require us to have 10 times the lecture space – which is an impossible requirement, even if we had the lecturing staff available to multiply their effort by 10. But the presentation of information, interactively with the lecturer, is still going strong in the remote space and we have noticed that more students participate in Q&A than the few we used to see dominating the physical space. We have lost the “vitamin” of community that occurs through regular mingling but that may come from other sources.
Paper assignments, long dwindling, are jetsam but that is perhaps hastening an inevitable demise. In a time of growing part-time student numbers, students who work part-time, increasing transit times, requiring the physical transfer of cellulose fibres imprinted with marking reagent seems a little excessive unless absolutely necessary. It’s true that on-line and electronic systems are less flexible than paper and, especially for formulae, there is a steep learning curve for formatting tools to represent complex symbols. E-paper, in its various forms, is promising but still not there. The removal of paper is probably making things harder and stifling some students’ creativity.
The tutorials and the laboratories are coming back, under new regulations and new requirements. Their value, the authentic and hands-on nature of a good exercise in these spaces, saved them from the ocean. We know what is good about them but now have to make sure that we have placed that good at the forefront.
The invigilated paper examination is another case altogether. I have just finished working on a fully remote examination, open book, and presented across a network. Instead of having two pens and pencils, my students need a fully-charged battery and a good internet connection. But the move to open book (a first for this course) has meant a Bloomian shift up into application and evaluation as a minimum – a very positive direction that we had been making but was much more easily justified in this change. We have kept most of the exam but we have thrown out some of its old baggage.
I will be honest. I think that on-line examinations, already a busy area of research, are going to be an area of a great deal of future research, much of it looking back into this year as we desperately try to work out what worked and how it worked. For me, this rationing has been fascinating, as it forced me to think in detail about exactly what I wanted students to do, as their potential identities as graduates, as students, and as discipline specialists.
There is another nautical term, which you might not know, lagan, that refers to heavy goods thrown from a ship to reduce weight but marked with a buoy to be recovered later. When danger has passed, you circle back and get them again. While flotsam and jetsam are often legally passed to their discoverer, unless the former owner makes a claim, lagan is always yours and you will be back for it.
I do wonder how many of the things that we didn’t do, that went overboard, are considered to be so valuable that we circle back for them? As we come out of this, even while we’re circling back, it’s probably worth some moments in reflection to determine whether we really want that heavy thing back on board or we learned something new while we weathered the storm.
Stay safe, stay well.
The Year(s) of Replication #las17ed L@S 2017
Posted: April 22, 2017 Filed under: Education, Opinion | Tags: community, education, l@s, las17ed, learning, learning@scale, mit, replication, science, teaching, testing 6 CommentsI was at Koli Calling in 2016 and a paper was presented (“Replication in Computing Education Research: Researcher Attitudes and Experiences”) regarding the issue of replicating previous studies. Why replicate previous work? Because we have a larger number of known issues that have emerged in psychology and the medical sciences, where important work has not been able to be replicated. Perhaps the initial analysis was underpowered, perhaps the researchers had terrible bad luck in their sample, and perhaps there were… other things going on. Whatever the reason, we depend upon replication as a validation tool and being unable to replicate work puts up a red flag.

After the paper, I had follow-up discussions with Andrew Petersen, from U Toronto, and we talked about the many problems. If we do choose to replicate studies, which ones do we choose? How do we get the replication result disseminated, given that it’s fundamentally not novel work? When do we stop replicating? What the heck do we do if we invalidate an entire area of knowledge? Andrew suggested a “year of replication” as a starting point but it’s a really big job: how do we start a year of replication studies or commit to doing this as a community?
This issue was raised again at Learning@Scale 2017 by Justin Reich, from MIT, among others. One of the ideas that we discussed as part of that session was that we could start allocating space at the key conferences in the field for replication studies. The final talk as part of L@S was “Learning about Learning at Scale: Methodological Challenges and Recommendations”, which discussed general problems that span many studies and then made recommendations as to how we could make our studies better and reduce the risk of failing future replication. Justin followed up with comments (which he described as a rant but he’s being harsh) about leaving room to make it easier to replicate and being open to this kind of examination of our work: we’re now thinking about making our current studies easier to replicate and better from the outset, but how can we go back and verify all of the older work effectively?
I love the idea of setting aside a few slots in every conference for replication studies. The next challenge is picking the studies but, given each conference has an organising committee, a central theme, and reviewers, perhaps each conference could suggest a set and then the community identify which ones they’re going to have a look at. We want to minimise unnecessary duplication, after all, so some tracking is probably a good idea.
There are several problems to deal with: some political, some scheduling, some scientific, some are just related to how hard it is to read old data formats. None of them are necessarily insurmountable but we have to be professional, transparent and fair in how we manage them. If we’re doing replication studies to improve confidence in the underlying knowledge of the field, we don’t want to damage the community in doing it.
Let me put out a gentle call to action, perhaps for next year, perhaps for the year after. If you’re involved with a conference, why not consider allocating a few slots to replication studies for the key studies in your area, if they haven’t already been replicated? Even the opportunity to have a community discussion about which studies have been effectively replicated will help identify what we can accept as well as showing us what we could fix.
Does your conference have room for a single track, keynote-level session, to devote some time to replication? I’ll propose a Twitter hashtag of #replicationtrack to discuss this and, hey, if we get a single session in one conference out of this, it’s more than we had.
Voices – LATICE 2017
Posted: April 25, 2016 Filed under: Education, Opinion | Tags: advocacy, blogging, community, discrimination, education, equality, higher education, inequality, latice, thinking 5 Comments[Edit: The conference is now being held in Hong Kong. I don’t know the reason behind the change but the original issue has been addressed. I have been accepted to Learning @ Scale so will not be able to attend anyway, as it turns out, as the two conferences overlap by two days and even I can’t be in the US and Hong Kong at the same time.]
There is a large amount of discussion in the CS Ed community right now over the LATICE 2017 conference, which is going to be held in a place where many members of the community will be effectively reduced to second-class citizenship and placed under laws that would allow them to be punished for the way that they live their lives. This affected group includes women and people who identify with QUILTBAG (“Queer/Questioning, Undecided, Intersex, Lesbian, Trans (Transgender/Transsexual), Bisexual, Asexual, Gay”). Conferences should be welcoming. This is not a welcoming place for a large percentage of the CS Ed community.
There are many things I could say here but what I would prefer you to do is to look at who is commenting on this and then understand those responses in the context of the author. For once, it matters who said what, because not everyone will be as affected by the decision to host this conference where it is.
From what I’ve seen, a lot of men think this is a great opportunity to do some outreach. A lot has been written, predominantly by men, about how every place has its problems and so on and so forth.
But let’s look at other voices. The female and QUILTBAG voices do not appear to share this support. Asking for their rights to be temporarily reduced or suspended for this ‘amazing opportunity’ is too much to ask. In response, I’ve seen classic diminishment of genuine issues that are far too familiar. Concerns over the reductions of rights are referred to as ‘comfort zone’ issues. This is pretty familiar to anyone who is actually tracking the maltreatment and reduction of non-male voices over time. You may as well say “Stop being so hysterical” and at least be honest and own your sexism.
Please go and read through all of the comments and see who is saying what. I know what my view of this looks like, as it is quite clear that the men who are not affected by this are very comfortable with such a bold quest and the people who would actually be affected are far less comfortable.
This is not a simple matter of how many people said X or Y, it’s about how much discomfort one group has to suffer that we take their concerns seriously. Once again, it appears that we are asking a group of “not-men”, in a reductive sense, to endure more and I cannot be part of that. I cannot condone it.
I will not be going. I will have to work out if I can cite this conference, given that I can see that it will lead to discrimination and a reduction of participation over gender and sexuality lines, unintentionally or not. I have genuine ethical concerns about using this research that I would usually reserve for historical research. But that is for me to worry about. I have to think about my ongoing commitment to this community.
But you shouldn’t care what I think. Go and read what the people who will be affected by this think. For once, please try to ignore what a bunch of vocal guys want to tell you about how non-male groups should be feeling.
Our duty to the future, a letter from the 18th Century.
Posted: February 25, 2016 Filed under: Education | Tags: advocacy, education, ethics, higher education, learning, teaching, thinking 1 Comment
Official Presidential Portrait of John Adams (John Trumbull, 1792).
Extract of a letter from John Adams to Abigail Adams, posted 12 May 1780, from Paris.
I could fill Volumes with Descriptions of Temples and Palaces, Paintings, Sculptures, Tapestry, Porcelaine, &c. &c. &c. — if I could have time. But I could not do this without neglecting my duty. The Science of Government it is my Duty to study, more than all other Sciences: the Art of Legislation and Administration and Negotiation, ought to take Place, indeed to exclude in a manner all other Arts. I must study Politicks and War that my sons may have liberty to study Mathematicks and Philosophy. My sons ought to study Mathematicks and Philosophy, Geography, natural History, Naval Architecture, navigation, Commerce and Agriculture, in order to give their Children a right to study Painting, Poetry, Musick, Architecture, Statuary, Tapestry and Porcelaine.
